apiserver指标分析
概述
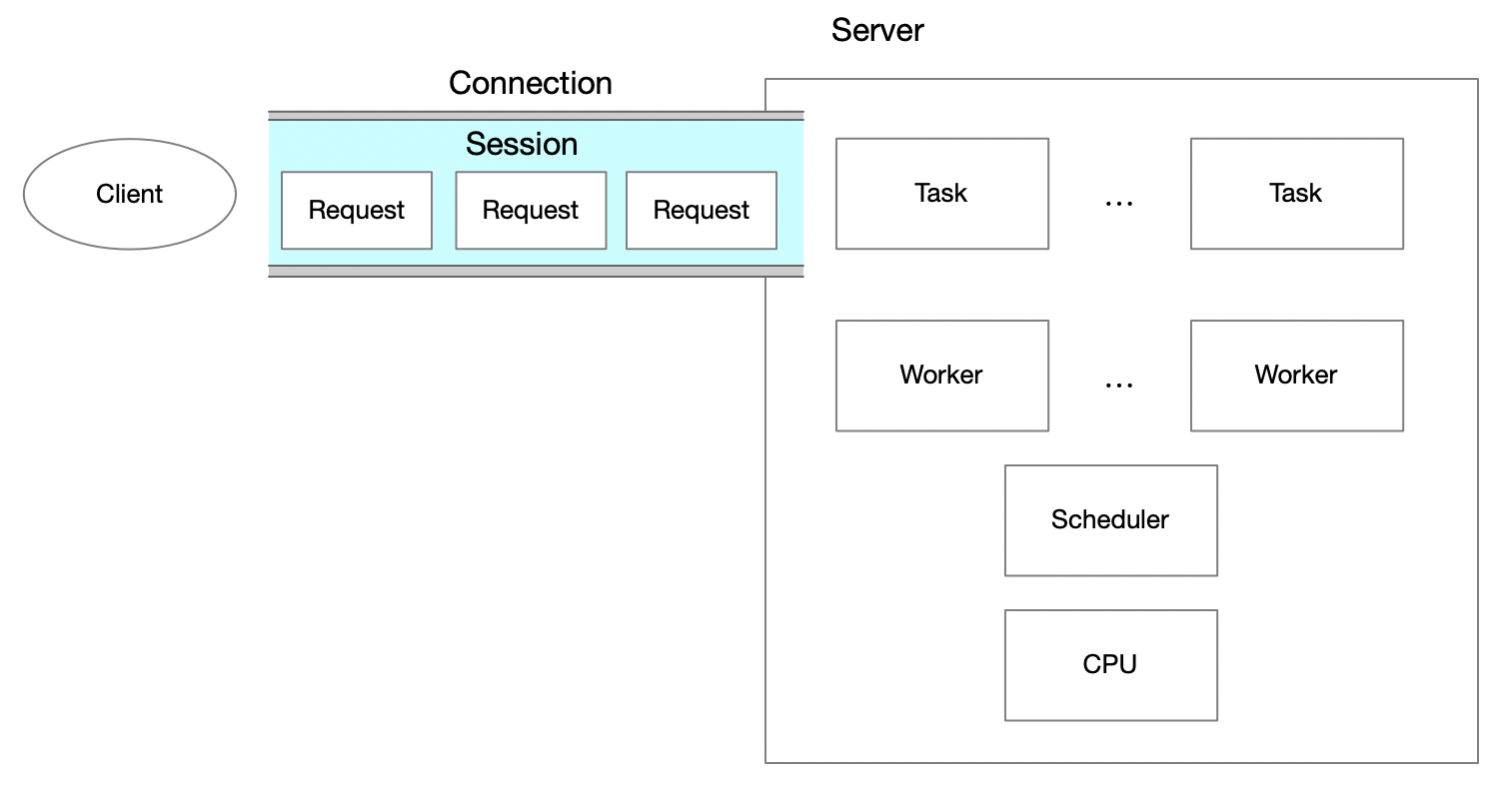
kube-apiserver 是集群所有请求的入口,指标的分析可以反应集群的健康状态。
Apiserver 的指标可以分为以下几大类:
请求速率和延迟
控制器队列的性能
etcd 的性能
进程状态:文件系统、内存、CPU
golang 程序的状态:GC、进程、线程
基于 RED 方法,评估 apiserver 服务的一些指标:
Rate 速率:每秒的请求数。
Error 错误:失败的那些请求的数量。
Duration 持续时间:这些请求所花费的时间
请求速率和延迟
Rate 速率
sum(rate(apiserver_request_count[5m])) by (resource, subresource, verb)
该查询会列出Kubernetes资源各种操作的五分钟的速率。操作有:WATCH,PUT,POST,PATCH,LIST,GET,DELETE和CONNECT
Error 错误
rate(apiserver_request_count{code=~"^(?:5..)$"}[5m]) / rate(apiserver_request_count[5m])此查询获取5分钟内错误率与请求率的比率
Duration 请求时间
histogram_quantile(0.9, sum(rate(apiserver_request_latencies_bucket[5m])) by (le, resource, subresource, verb) ) / 1e+06
查看 90%情况下请求的时间分布
队列情况
所有资源的请求都会被 apiserver 中的 controller 处理,controller 维护了队列,队列的一些指标可以反应资源处理的速度等指标
以apiserver_admission_controller为例:
apiserver_admission_controller_admission_duration_seconds:准入控制器的处理时间 以秒为单位),通过名称进行标识,并针对每个操作以及API资源和类型(验证或准入)进行细分。
apiserver_admission_controller_admission_latencies_milliseconds 延迟*
ETCD 的指标
API Server对etcd 的读写有缓存
etcd_helper_cache_entry_count —缓存中的元素数。
etcd_helper_cache_hit_count —缓存命中计数。
etcd_helper_cache_miss_count —缓存未命中计数。
etcd_request_cache_add_latencies_summary —将条目添加到缓存的时间(以微秒为单位)。
程序指标
apiserver 是 go 程序,目前所有 prometheus 采集的指标都会包含 golang 程序指标,如:
go_gc_duration_seconds 程序 GC 的耗时
go_gc_duration_seconds_count 程序 GC 的次数
go_gc_duration_seconds_quantile 程序 GC 的耗时分布
go_goroutines goroutines信息
go_info go环境信息
request
apiserver_request 请求信息
apiserver_request_count 请求次数
apiserver_request_duration_seconds 请求耗时
response
apiserver_response_sizes 每个组,版本,动作,资源,子资源,范围和组件的响应大小分布(以字节为单位)
apiserver_response_sizes_bucket 区间分布
apiserver_response_sizes_count 返回的数量
audit
apiserver_audit_event: 审计事件
apiserver_audit_requests_rejected:审核拒绝的请求
参考
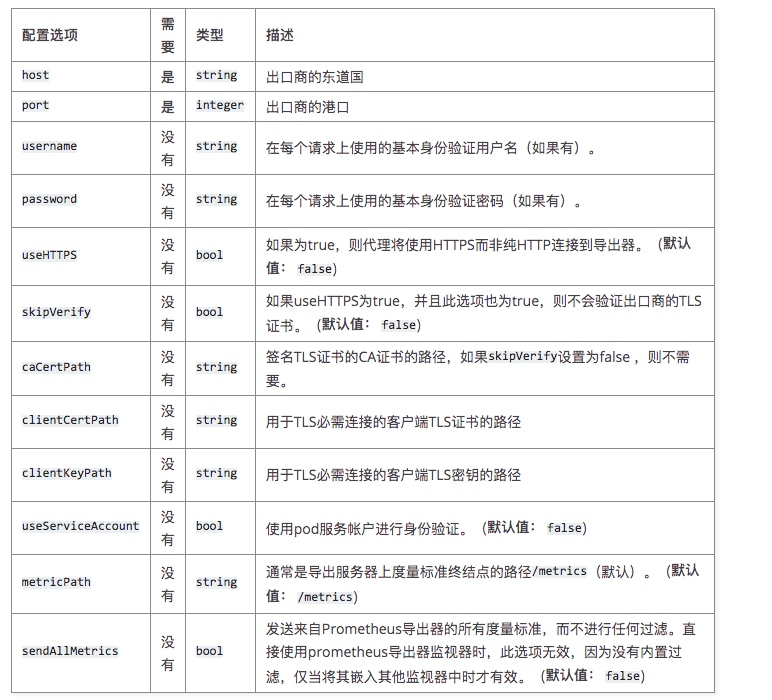
访问 apiserver 的 metric 时需要的参数