大数据之数据采集组件选型
按数据的源头、实际上也是对应的数据采集方式,分别进行分析与技术推荐,数据从源头基本分为
以下三大类
1、Web页面/移动App/MES/IoT/系统生产:
这些数据是被动接收。建议可采用Apache NiFi,Apache Seatunel,虽然国内有DataX,但是NiFi
的能力要丰富,可视化界面,画布模式简单拖拽,NiFi经过Apache多年开源积累已经相当成熟,
有每天处理几十亿数据的案例SeaTunnel 与 kettle,NiFi这种重量级的平台相比,更像 Datax 轻量
级的数据传输工具,用户可以根据需要来安装 Source、Sink、Transform插件对于特殊场景,可以
使用NiFi和SeaTunnel结合使用
第一种结合方式是可以用 NiFi 的 执行程序组件封装 SeaTunnel ,利用NiFi的调度能力,使其可以
定时运行 SeaTunnel 任务另外一种形式是NiFi可以二次开发来封装 SeaTunnel 组件
2、数据库(database):
首先可以是定期增量或全量批拉的方式,这里主要讲实时的CDC方式,数据是基于事件被推过来的。
(1)MySQL,可以采用Sqoop/Canal,也可以自己写逻辑成一个定制的NiFi Processor,最后流入
Kafka,也可以同时流入其它存储。
(2)Oracle可以采用OGG同步Oracle数据,通过解析源数据库在线日志或归档日志获得数据的增
删改变化(数据量只有日志的四分之一左右)
(3)HBase可以考虑写一个基于HBaseEndpoint的CDC(Change Data Capture)
(4)Cassandra作为一线业务存储,官方有CDC支持
(5)关系数据库管理系统(RDBMS)采用Sqoop完全可以支持
3、系统日志(System log):
可以用Apache NiFi中的TailFile(支持Rolling)这个Processor,中间加上自己写或拖拽处需要的处
理逻辑,最后吐到Kafka等存储中。或者使用经典的Flume也是可以,但是相对来说NiFi简单便捷。
4、消息队列:一般选用Apache Flink做准实时数据处理,也可采用SparkStreaming或者
Apache Storm
数据采集组件选择流程图:
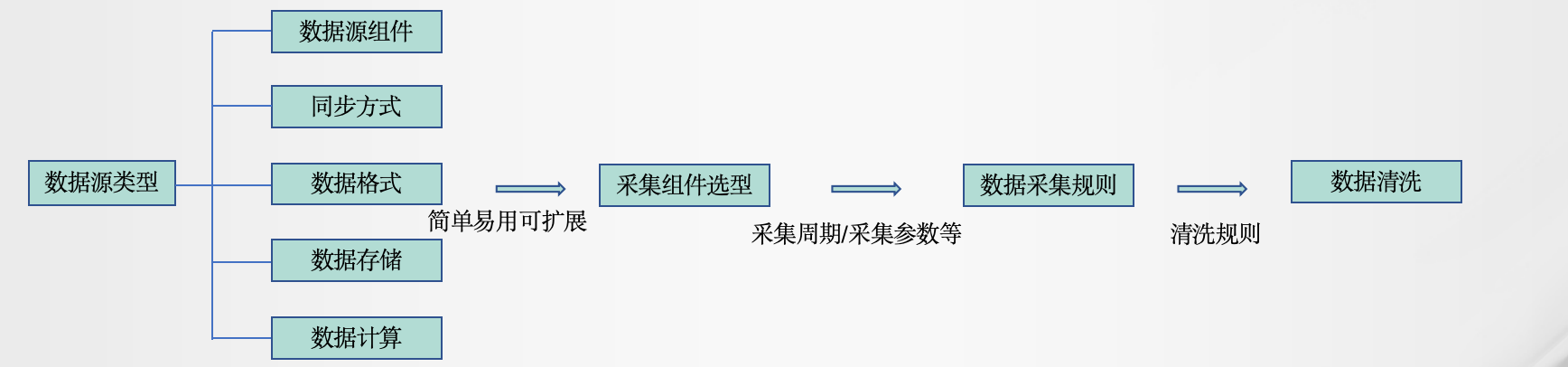
综合:用NiFi一个框架就可以解决所有数据的问题了,而且NiFi具备综合的管理能力,如:跟踪、
监控、拖拽开发、多租户、HA方案等。可以把NiFi看成是万能的整合采集器,但不要把复杂的
计算逻辑让它来担当,那不是它的强项。NiFi还有背压的能力