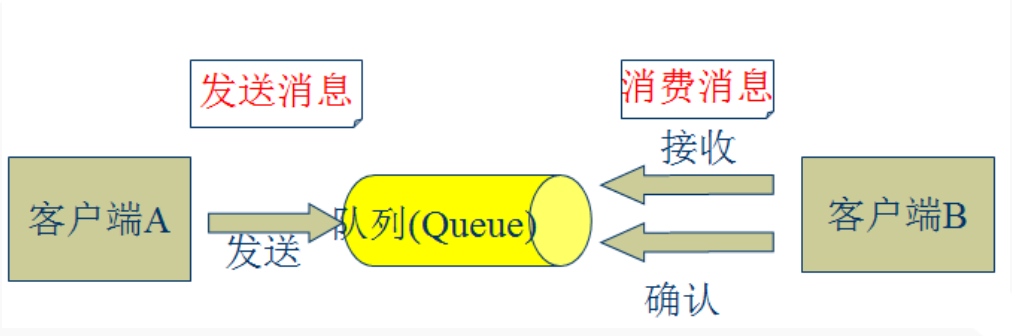
Kafka日志管理
Kafka在运行时会生成大量的日志记录信息,包含了运行状态、错误信息、性能指标等。
这些日志文件会占用很大的磁盘空间,过多的日志文件也会影响Kafka的性能,因此需
要采取一些日志管理措施来清理无用的日志记,减少磁盘空间的占用并提高Kafka的性能
日志清理策略
1.日志压缩
对Kafka的日志进行压缩以减少磁盘空间占用,Kafka提供了两种日志压缩方式:
gzip和snappy。
gzip会导致CPU负载的增加但能够获得更高的压缩比
snappy则需要更少的CPU负载但压缩比相对较低
可以根据自己的需求选择适合的压缩方式。
2.日志清理策略
使用Kafka内置的日志清理工具来清除无用的日志记录,Kafka的日志清理工具会根据一些配
置参数来删除旧的日志记录。
例如可以指定一个保留期限来决定多长时间之前的日志记录需要被删除
设定一个日志最大大小当每个分区的日志大小超过阀值时就会删除最早的日志
3.日志管理工具
可以使用一些第三方日志管理工具如ELK(Elasticsearch、Logstash和Kibana)
能够对Kafka的日志进行集中管理和分析从而更好地了解Kafka的运行状况