HDFS核心参数
1.NameNode内存生产配置
(1)NameNode内存计算,每个文件块大概占用150byte,一台服务器128G内存为例,能存储9.1亿个文件
128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1亿
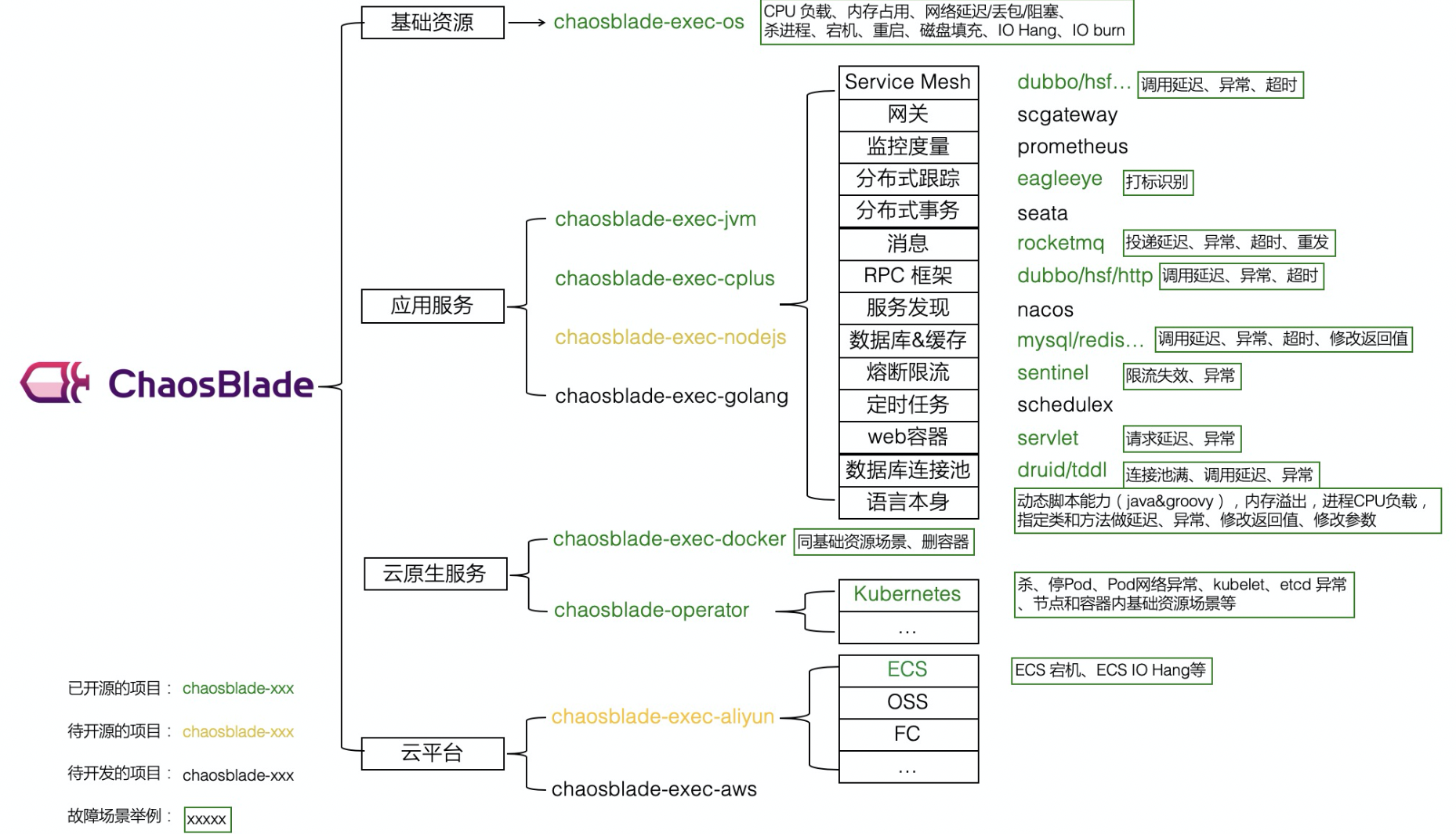
(2)Hadoop2.x系列,NameNode内存默认2000m,如果服务器内存4G,NameNode内存可以配置3g。在hadoop-env.sh文件中配置HADOOP_NAMENODE_OPTS=-Xmx3072m
(3)Hadoop3.x系列,hadoop-env.sh中描述Hadoop的内存是动态分配的
hadoop-env.sh中描述Hadoop的内存是动态分配的
2.NameNode心跳并发配置
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作,对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
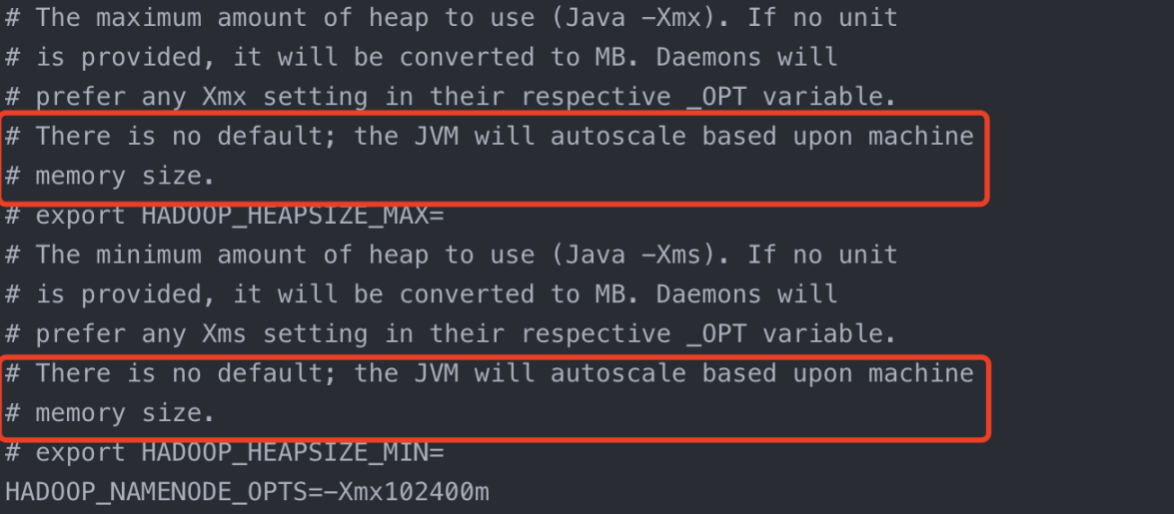
企业经验计算:
比如集群规模(DataNode台数)为3台时,此参数设置为21。计算公示如下:
3. 开启回收站配置
(1)开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
(2)回收站工作机制如右图所示
(3)开启回收站功能参数说明
默认值fs.trash.interval = 0,0表示禁用回收站;其他值表示设置文件的存活时间。
默认值fs.trash.checkpoint.interval = 0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
要求fs.trash.checkpoint.interval <= fs.trash.interval。
(4)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
(5)查看回收站
回收站目录在HDFS集群中的路径:/user/hdfs/.Trash
(6) 通过网页上直接删除的文件也不会走回收站
(7) 通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
(8) 只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站
(9) 回收站回复,通过hadoop fs mv命令将回收站数据移动到制定目录