PromQL语法
一、PromQL语法
1.1、什么是PromQL
PromQL(Prometheus Query Language)是 Prometheus 自己开发的表达式语言,语言表现力很丰富,内置函数也很多。使用它可以对时序数据进行筛选和聚合。
1.2、数据类型
PromQL 表达式计算出来的值有以下几种类型:
瞬时向量 (Instant vector)
区间向量 (Range vector)
标量数据 (Scalar)
字符串 (String)
1.2.1、瞬时向量选择器
瞬时向量选择器用来选择一组时序在某个采样点的采样值。最简单的情况就是指定一个度量指标,选择出所有属于该度量指标的时序的当前采样值。比如下面的表达式:
apiserver_request_total
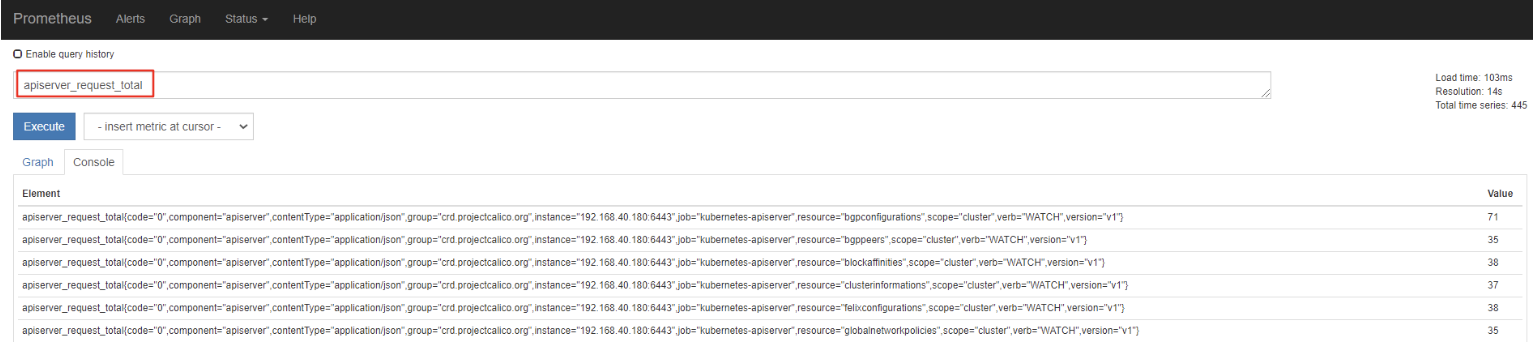
可以通过在后面添加用大括号包围起来的一组标签键值对来对时序进行过滤。比如下面的表达式筛选出了 job 为 kubernetes-apiservers,并且 resource为 pod的时序:
apiserver_request_total{job="kubernetes-apiserver",resource="pods"}匹配标签值时可以是等于,也可以使用正则表达式。总共有下面几种匹配操作符:
=:完全相等 !=: 不相等 =~: 正则表达式匹配 !~: 正则表达式不匹配
1.2.2、区间向量选择器
区间向量选择器类似于瞬时向量选择器,不同的是它选择的是过去一段时间的采样值。可以通过在瞬时向量选择器后面添加包含在 [] 里的时长来得到区间向量选择器。比如下面的表达式选出了所有度量指标为apiserver_request_total且resource是pod的时序在过去1 分钟的采样值。
apiserver_request_total{job="kubernetes-apiserver",resource="pods"}[1m]说明:时长的单位可以是下面几种之一:
s:seconds m:minutes h:hours d:days w:weeks y:years
1.2.3、偏移向量选择器
偏移修饰器用来调整基准时间,使其往前偏移一段时间。偏移修饰器紧跟在选择器后面,使用 offset 来指定要偏移的量。比如下面的表达式选择度量名称为apiserver_request_total的所有时序在 10分钟前的采样值。
apiserver_request_total{job="kubernetes-apiserver",resource="pods"} offset 10m下面的表达式选择apiserver_request_total 度量指标在 1 周前的这个时间点过去 10 分钟的采样值。
apiserver_request_total{job="kubernetes-apiserver",resource="pods"} [10m] offset 1w1.2.4、聚合操作符
PromQL 的聚合操作符用来将向量里的元素聚合得更少。总共有下面这些聚合操作符
sum:求和 min:最小值 max:最大值 avg:平均值 stddev:标准差 stdvar:方差 count:元素个数 count_values:等于某值的元素个数 bottomk:最小的 k 个元素 topk:最大的 k 个元素 quantile:分位数
1)计算k8s-master1节点所有容器总计内存:
sum(container_memory_usage_bytes{instance=~"k8s-master1"})/1024/1024/10242)计算k8s-master1节点最近1m所有容器cpu使用率
sum (rate (container_cpu_usage_seconds_total{instance=~"k8s-master1"}[1m])) / sum (machine_cpu_cores{ instance =~"k8s-master1"}) * 1003)计算最近1m所有容器cpu使用率
1.2.5、函数
Prometheus 内置了一些函数来辅助计算
abs():绝对值 sqrt():平方根 exp():指数计算 ln():自然对数 ceil():向上取整 floor():向下取整 round():四舍五入取整 delta():计算区间向量里每一个时序第一个和最后一个的差值 sort():排序