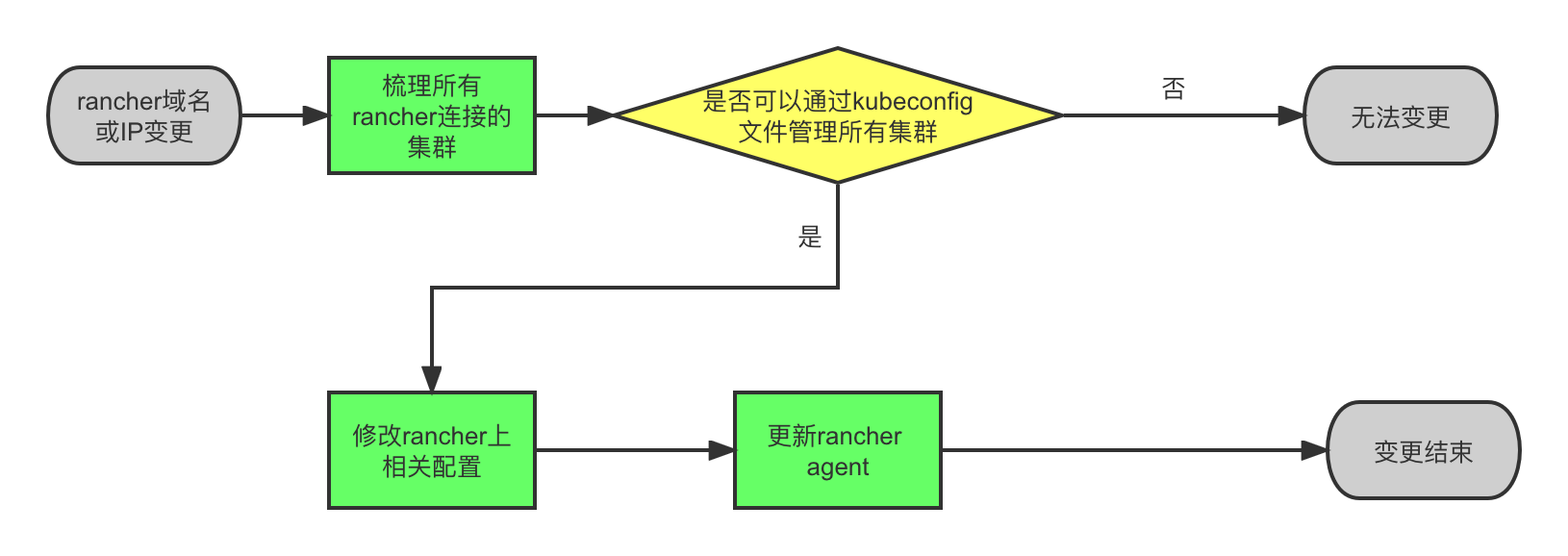
一条sql 在MySQL中是如何执行的
在 MySQL 中,SQL 查询的执行涉及多个内存区域和处理步骤,以确保查询能够高效地执行和返回结果。以下是 SQL 查询在 MySQL 中执行时通常会经过的内存路径:
1. 客户端内存
- SQL 文本发送 :SQL 查询首先从客户端发送到 MySQL 服务器。客户端内存用于存储和发送 SQL 查询文本。
2. 网络缓冲区
- 接收和处理请求 :SQL 查询通过网络传输到 MySQL 服务器,在服务器端进入网络缓冲区(Network Buffer),等待处理。
3. 解析器和优化器内存
-SQL 解析 :MySQL 解析器将 SQL 查询解析为语法树。此过程使用解析器内存来存储中间数据结构。
- 查询优化 :MySQL 优化器会生成多个查询执行计划,并选择最优的执行路径。这一过程使用优化器内存来计算和存储执行计划的相关信息。
4.查询缓存(可选)
- 查询缓存检查 :MySQL 在执行查询之前,会检查是否在查询缓存中已有结果(如果查询缓存启用)。如果查询结果已缓存且未过期,则直接从查询缓存中返回结果,从而跳过后续的处理步骤。
5.表缓存(Table Cache)
- 表打开和管理 :如果查询涉及的表没有被打开,MySQL 将会在表缓存中检查并尝试打开表文件。表缓存内存用于存储已打开表的元数据和文件句柄。
6.内存表(Memory Tables)
-内存临时表 :某些复杂查询,如带有 `GROUP BY`、`ORDER BY`、或 `DISTINCT` 的查询,可能需要 MySQL 在内存中创建临时表来存储中间结果。如果数据量过大,临时表可能会被存储到磁盘。
7.InnoDB 缓冲池(Buffer Pool)
-数据页缓存 :MySQL 使用 InnoDB 缓冲池来缓存表数据和索引页。查询过程中涉及到的表数据首先在缓冲池中查找,如果未命中,则从磁盘加载相应的数据页到缓冲池。
- 索引和数据访问 :缓冲池用于存储经常访问的索引和表数据,以减少磁盘 I/O 操作,提高查询速度。
8.排序缓冲区(Sort Buffer)
-排序操作 :如果查询中包含排序操作(`ORDER BY`),MySQL 可能会使用排序缓冲区来存储需要排序的数据。这个缓冲区大小可以通过配置参数调整。
9.连接缓冲区(Join Buffer)
-表连接操作 :在处理多表连接(尤其是嵌套循环连接)时,MySQL 可能会使用连接缓冲区来存储中间结果。
10.服务器内存
-执行查询计划 :最终,MySQL 根据优化器生成的执行计划进行查询执行。执行过程中,数据从磁盘读取到内存中进行处理,并通过不同的内存区域(如缓冲池、排序缓冲区、连接缓冲区等)进行操作。
11.结果集生成
-生成最终结果 :查询执行完毕后,生成结果集并将其放入结果缓存中,以便发送回客户端。
12.网络缓冲区
-发送结果集 :结果集通过服务器端的网络缓冲区发送回客户端。
13.客户端内存
-接收和显示结果 :最终,客户端接收到查询结果,并在客户端内存中存储和处理这些数据。
总结
MySQL 的查询执行过程涉及多个内存区域,从解析和优化查询到处理数据和生成结果,每个步骤都在特定的内存区域中完成。这种内存路径设计旨在最大化查询执行的效率,并尽量减少磁盘 I/O 以提升性能。