MySQL 查询 Binlog 生成时间
描述
本 SOP 介绍如何查询 Binlog 的生成时间。云上 RDS 有日志管理,但是自建实例没有,该脚本可用于自建实例闪回定位 Binlog 文件。
脚本介绍
通过读取 Binlog FORMAT_DESCRIPTION_EVENT header 时间戳获取 Binlog 时间范围。
# -*- coding: utf-8 -*-
import os
import sys
import math
import time
import struct
import argparse
binlog_quer_event_stern = 4
binlog_event_fix_part = 13
table_map_event_fix_length = 8
BINLOG_FILE_HEADER = b'\xFE\x62\x69\x6E'
binlog_event_header_len = 19
class BinlogTimestamp(object):
def __init__(self, index_path):
self.index_path = index_path
def main(self):
binlog_info_list = list()
for file_path in self.reed_index_file():
result = self.read_binlog_pos(file_path)
binlog_info_list.append({
'file_name': result[0],
'binlog_size': result[2],
'start_time': result[1]
})
# print
i = 0
while len(binlog_info_list) > i:
if i + 1 == len(binlog_info_list):
end_time = 'now'
else:
end_time = binlog_info_list[i + 1]['start_time']
binlog_info_list[i]['end_time'] = end_time
print(binlog_info_list[i])
i += 1
def read_binlog_pos(self, binlog_path):
binlog_file_size = self.bit_conversion(os.path.getsize(binlog_path))
file_name = os.path.basename(binlog_path)
with open(binlog_path, 'rb') as r:
# read BINLOG_FILE_HEADER
if not r.read(4) == BINLOG_FILE_HEADER:
print("Error: Is not a standard binlog file format.")
sys.exit(0)
# read binlog header FORMAT_DESCRIPTION_EVENT
read_byte = r.read(binlog_event_header_len)
result = struct.unpack('=IBIIIH', read_byte)
type_code, event_length, event_timestamp, next_position = result[1], result[3], result[0], result[4]
binlog_start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(event_timestamp))
return file_name, binlog_start_time, binlog_file_size
def reed_index_file(self):
"""
读取 mysql-bin.index 文件
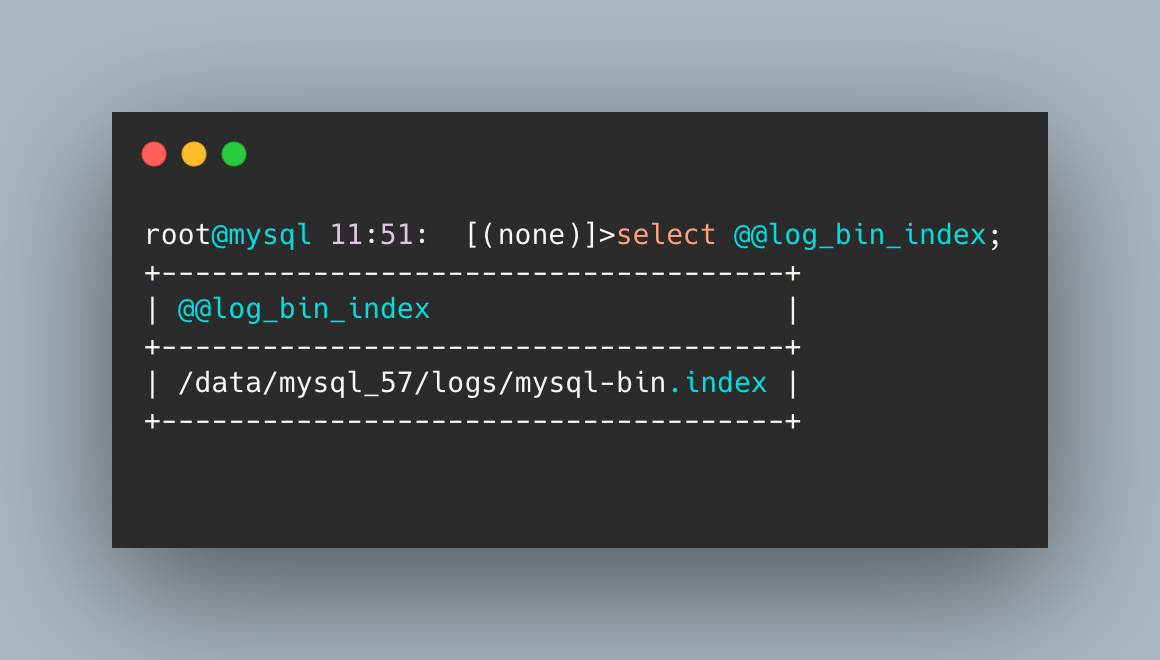
select @@log_bin_index;
:return:
"""
with open(self.index_path) as r:
content = r.readlines()
return [x.replace('\n', '') for x in content]
@staticmethod
def bit_conversion(size, dot=2):
size = float(size)
if 0 <= size < 1:
human_size = str(round(size / 0.125, dot)) + ' b'
elif 1 <= size < 1024:
human_size = str(round(size, dot)) + ' B'
elif math.pow(1024, 1) <= size < math.pow(1024, 2):
human_size = str(round(size / math.pow(1024, 1), dot)) + ' KB'
elif math.pow(1024, 2) <= size < math.pow(1024, 3):
human_size = str(round(size / math.pow(1024, 2), dot)) + ' MB'
elif math.pow(1024, 3) <= size < math.pow(1024, 4):
human_size = str(round(size / math.pow(1024, 3), dot)) + ' GB'
elif math.pow(1024, 4) <= size < math.pow(1024, 5):
human_size = str(round(size / math.pow(1024, 4), dot)) + ' TB'
elif math.pow(1024, 5) <= size < math.pow(1024, 6):
human_size = str(round(size / math.pow(1024, 5), dot)) + ' PB'
elif math.pow(1024, 6) <= size < math.pow(1024, 7):
human_size = str(round(size / math.pow(1024, 6), dot)) + ' EB'
elif math.pow(1024, 7) <= size < math.pow(1024, 8):
human_size = str(round(size / math.pow(1024, 7), dot)) + ' ZB'
elif math.pow(1024, 8) <= size < math.pow(1024, 9):
human_size = str(round(size / math.pow(1024, 8), dot)) + ' YB'
elif math.pow(1024, 9) <= size < math.pow(1024, 10):
human_size = str(round(size / math.pow(1024, 9), dot)) + ' BB'
elif math.pow(1024, 10) <= size < math.pow(1024, 11):
human_size = str(round(size / math.pow(1024, 10), dot)) + ' NB'
elif math.pow(1024, 11) <= size < math.pow(1024, 12):
human_size = str(round(size / math.pow(1024, 11), dot)) + ' DB'
elif math.pow(1024, 12) <= size:
human_size = str(round(size / math.pow(1024, 12), dot)) + ' CB'
else:
raise ValueError('bit_conversion Error')
return human_size
if __name__ == '__main__':
file_name = sys.argv[1]
bt = BinlogTimestamp(file_name)
bt.main()使用案例
1. 查询 binlog index 文件
2. 使用脚本查询时间
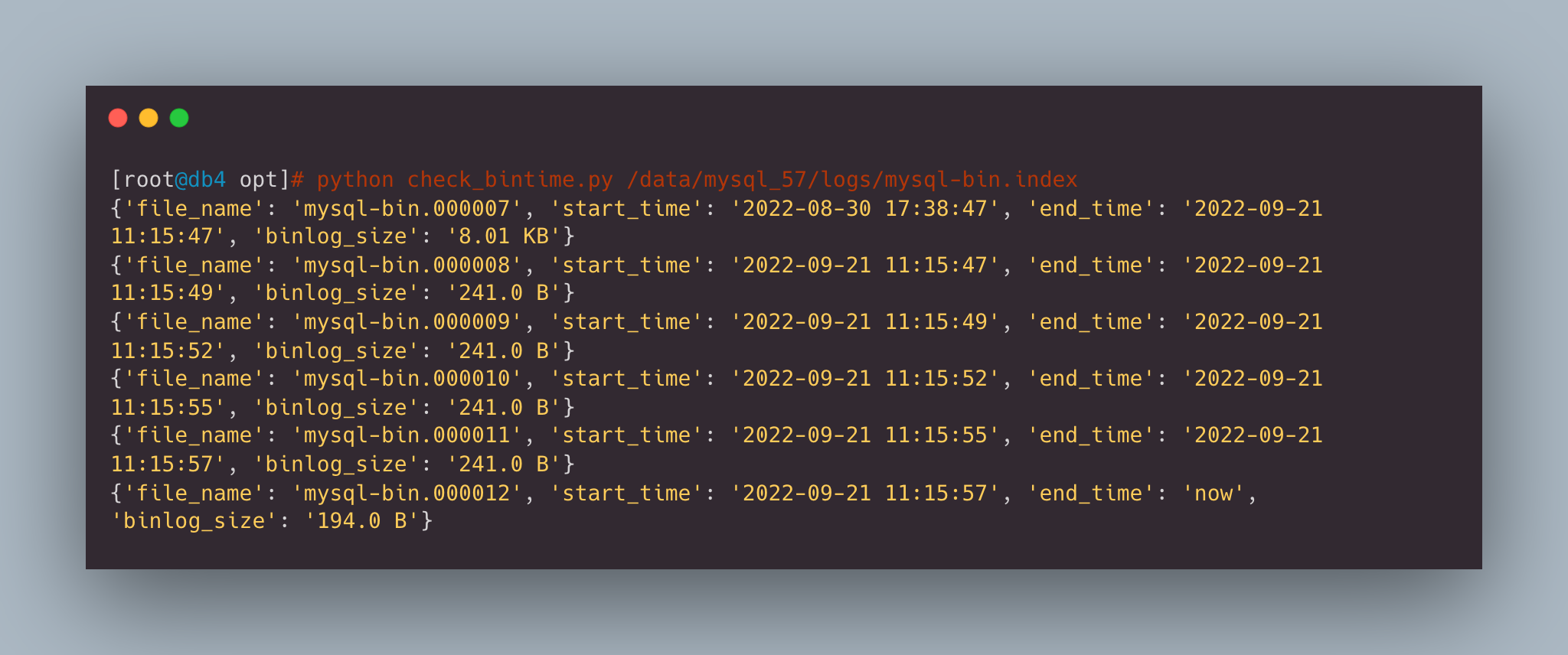
脚本上传到 MySQL 服务器后,指定 binlog index 文件位置即可:
python check_bintime.py /data/mysql_57/logs/mysql-bin.index