基于Jenkins和Kubernetes的CI/CD
jenkins安装
安装helm CRD
编辑好yaml文件后直接安装即可
k3s kubectl apply -f jenkins-crd.yaml
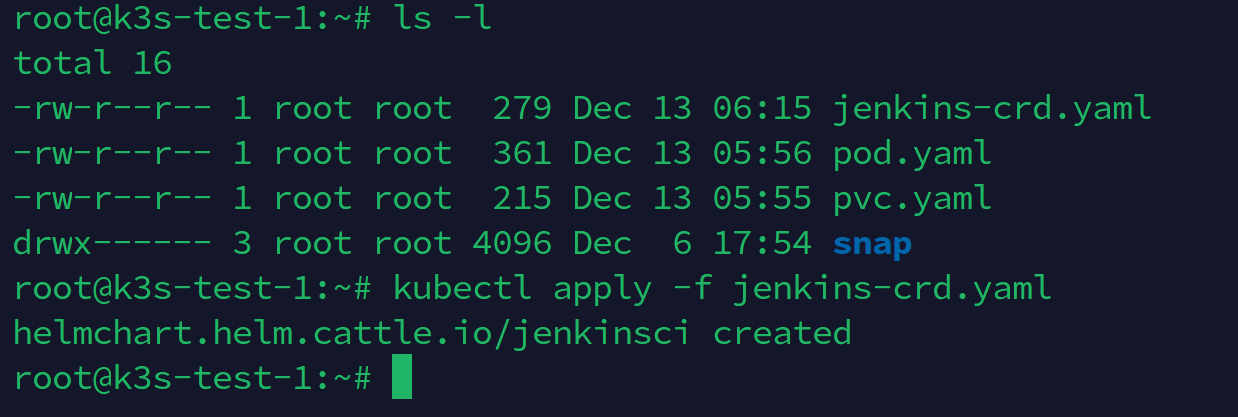
查看我们安装好的helmchart crd
k3s kubectl get helmchart -A

查看jenkins
k3s kubectl get all -n jenkins
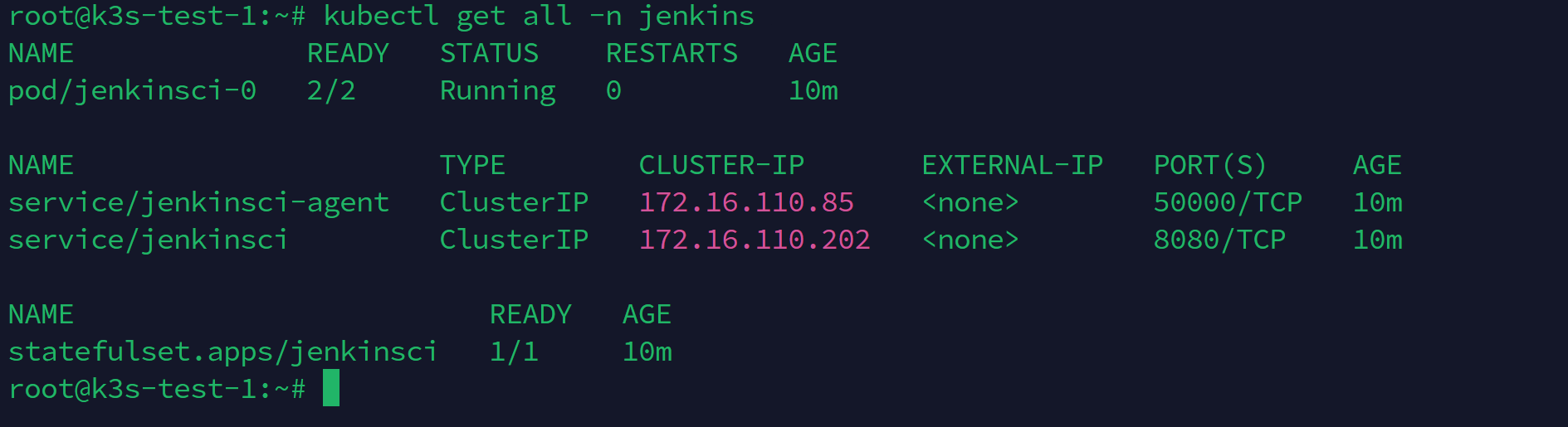
此时可以看到jenkins已经安装
jenkins配置
访问jenkins
我们的jenkins使用nodeport的访问方式,查看下nodeport的端口并进行访问
k3s kubectl get svc -n jenkins

访问宿主机的30341端口
获取jenkins密码
根据jenkins helm chart相关配置可以得知,jenkins初始账号密码存储在secret中,查看相关secret
k3s kubectl get secret -n jenkins

查看jenkinsci的secret
k3s kubectl get secret -n jenkins jenkinsci -o yaml
这里获取到的用户名和密码是经过base64加密的,获取未加密的用户名和密码(用户名是admin,这里不再获取)
jsonpath="{.data.jenkins-admin-password}"
secret=$(kubectl get secret -n jenkins jenkinsci -o jsonpath=$jsonpath)
echo $(echo $secret | base64 --decode)
通过用户名成功登录到jenkins,jenkins部署完成
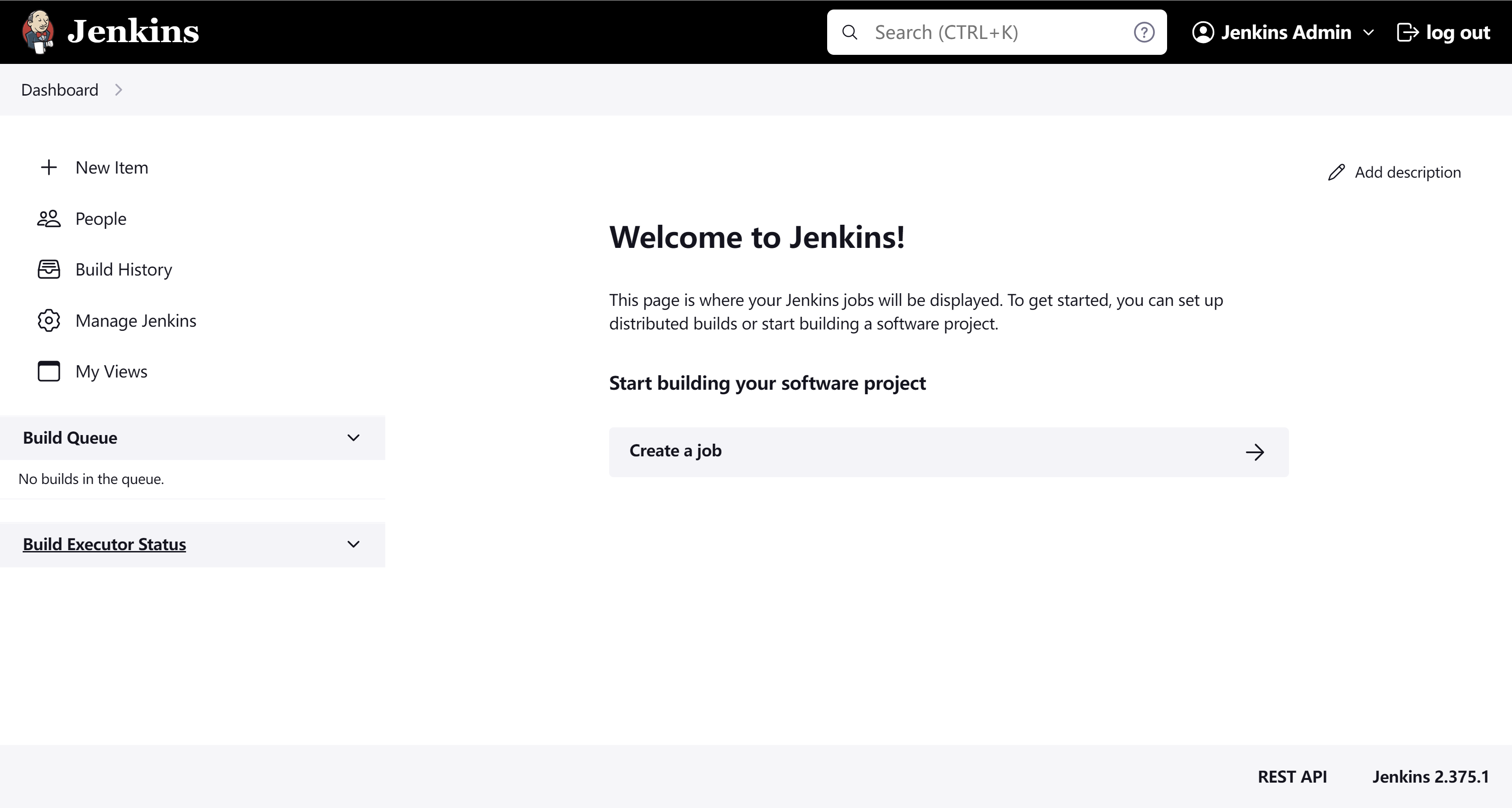
配置jenkins
首先通过jenkins页面安装一些插件
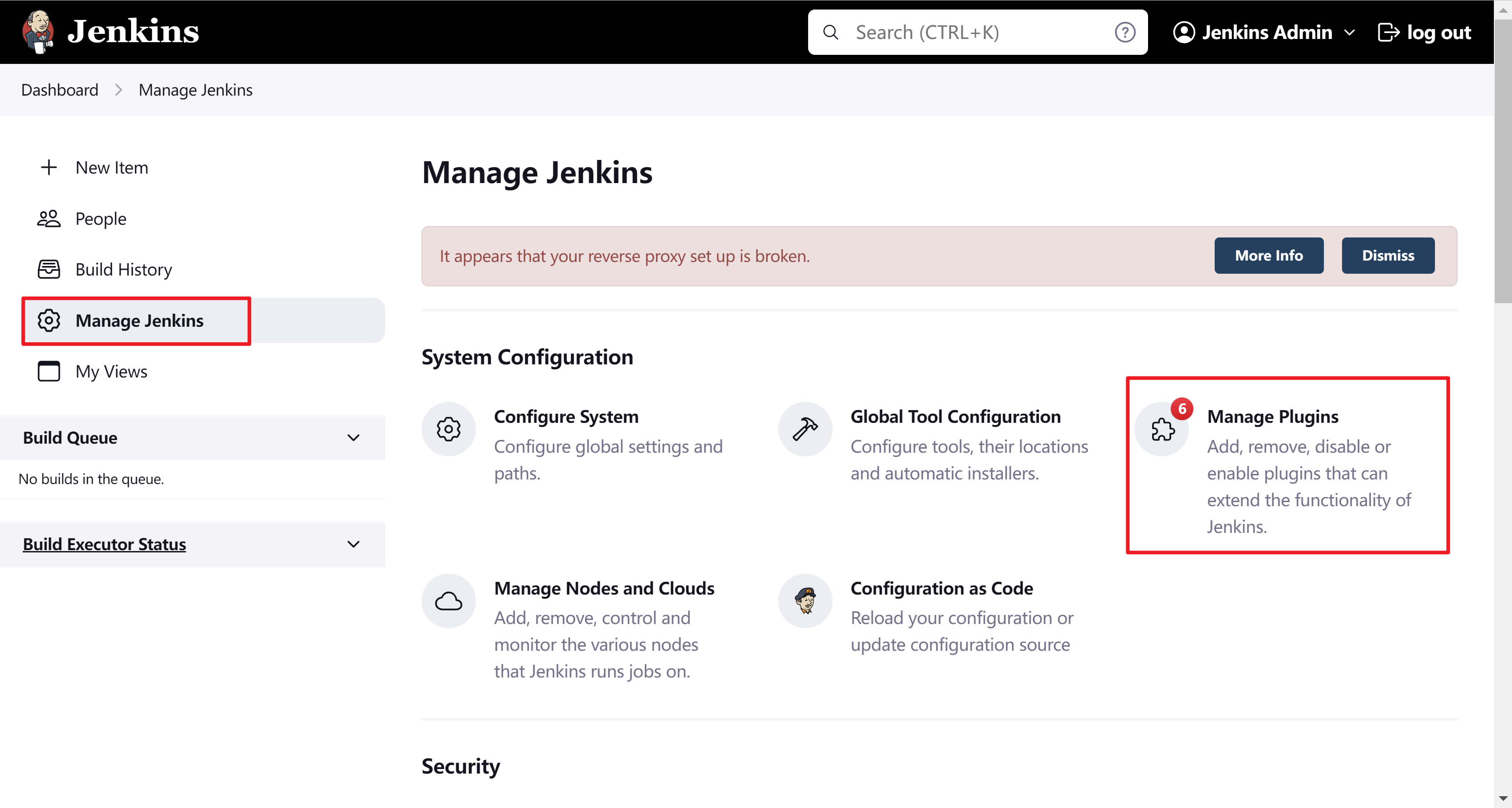
如git,中文汉化等
安装完成后访问/restart路径重启jenkins生效
重启完成后就可以正常使用jenkins了
Config File Provider插件
我们这里使用Config File Provider来对jenkins进行管理,插件商店直接安装即可。安装完成后可以在jenkins管理页面看到配置页面。
这里需要安装两个插件(pipeline-multibranch-defaults和Config File Provider)
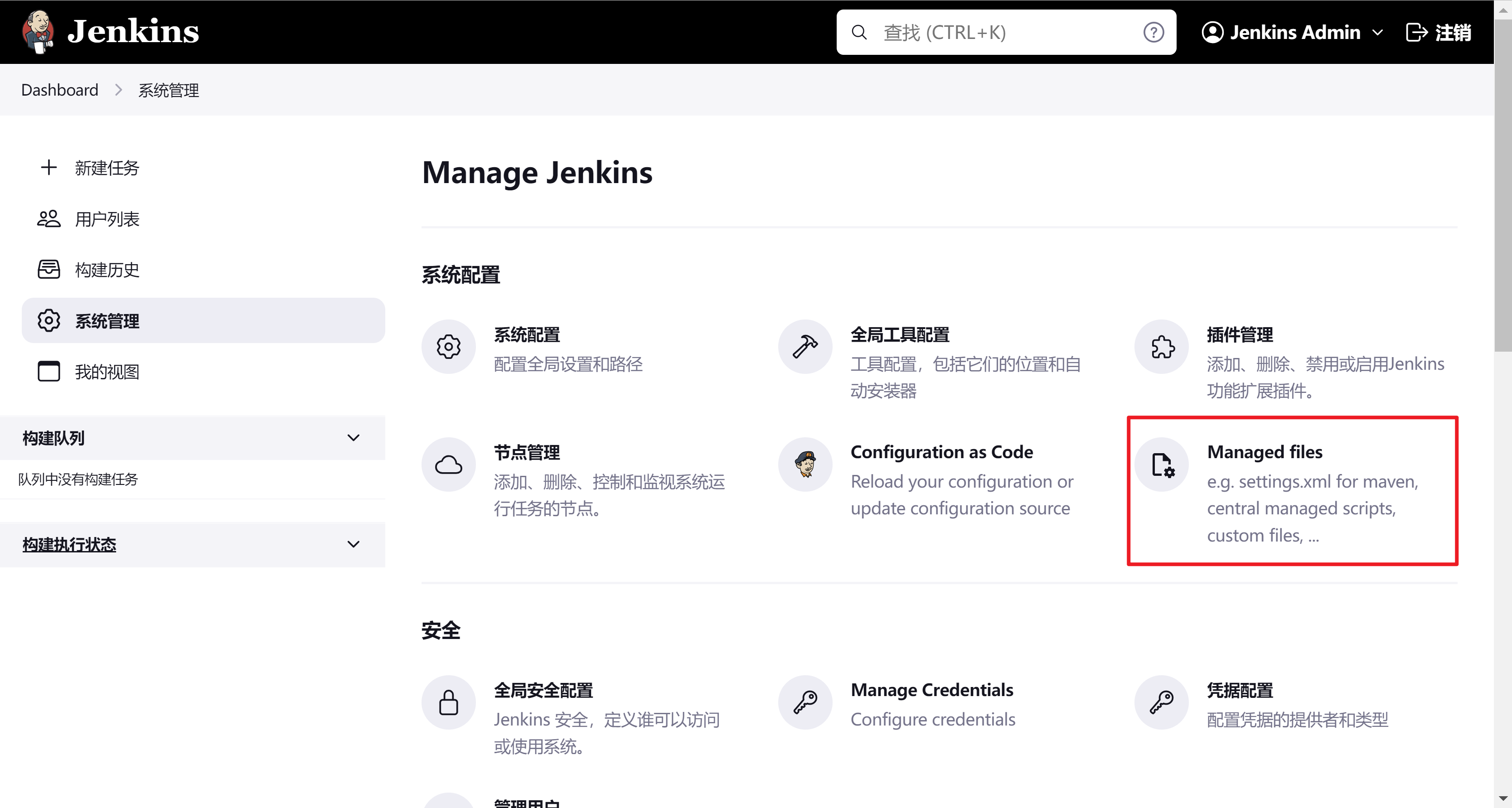
简单使用config file provider来管理jenkins file
点击 add new config 选择groovy file
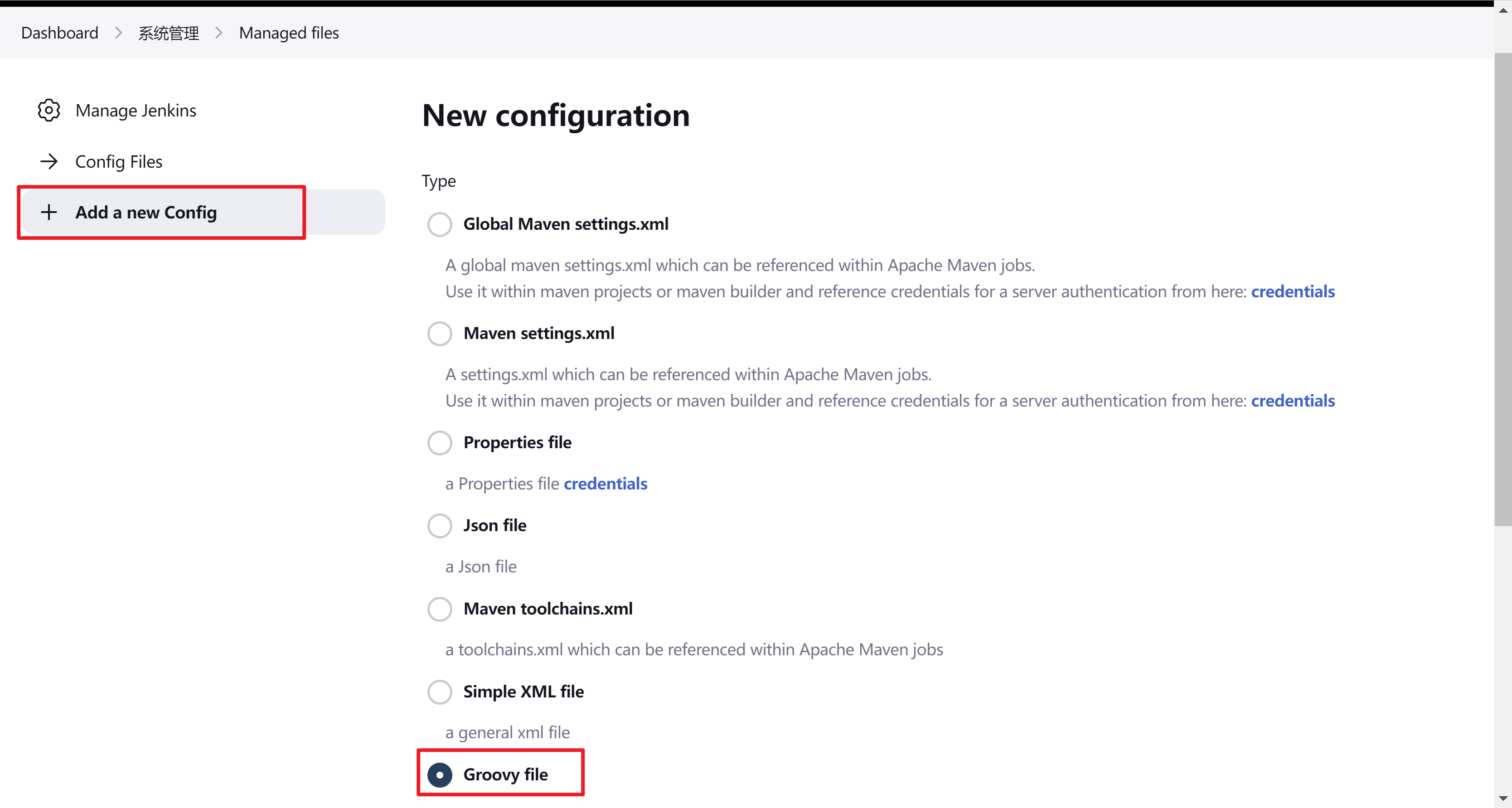
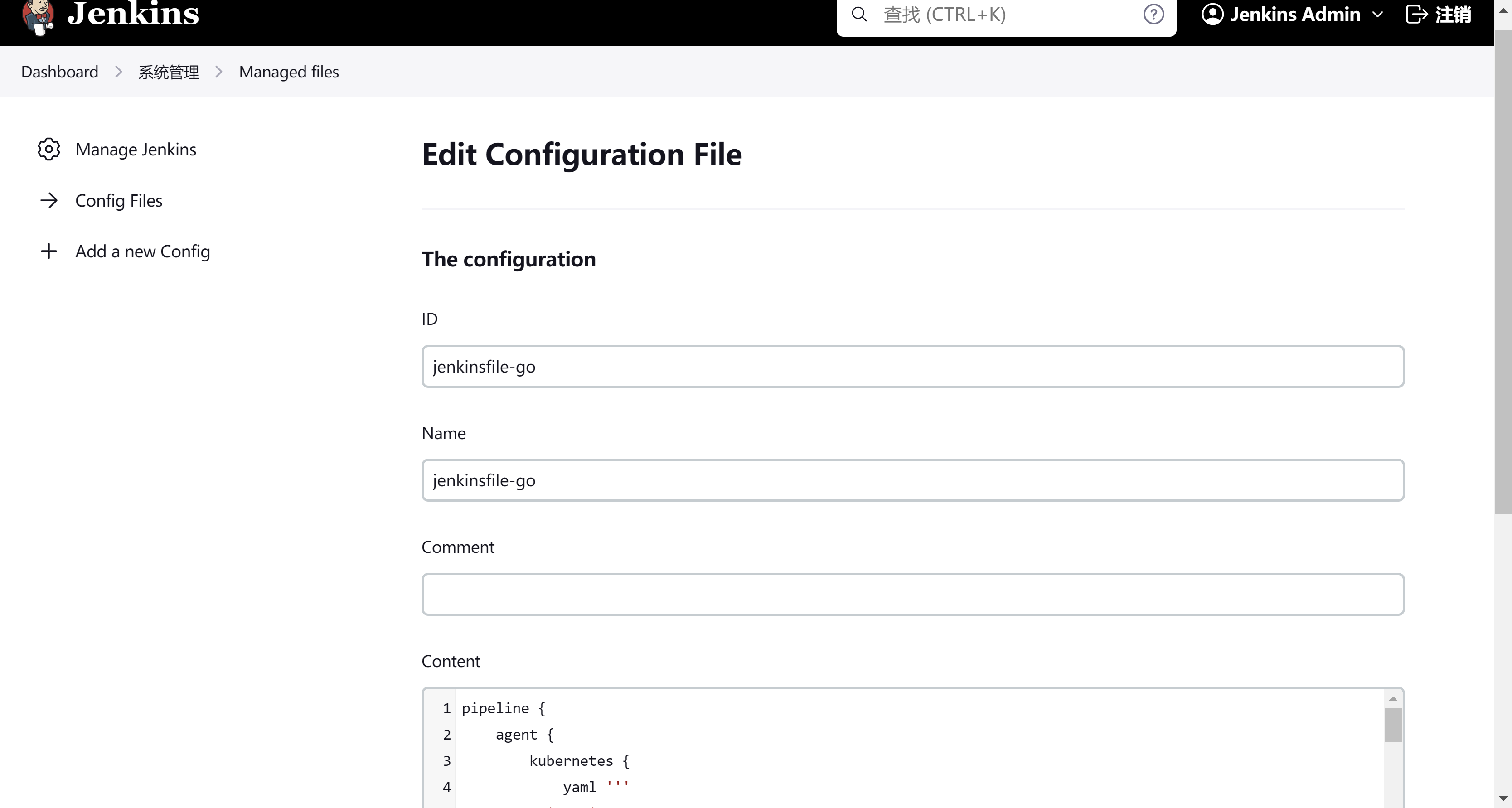
这里的ID需要注意,后面将会用到。内容填写jenkinsfile的内容即可
创建jenkins多分支流水线项目并使用上述配置文件
jenkins新建一个多分支流水线项目

创建完成后进行配置
分支源按照需求填写即可
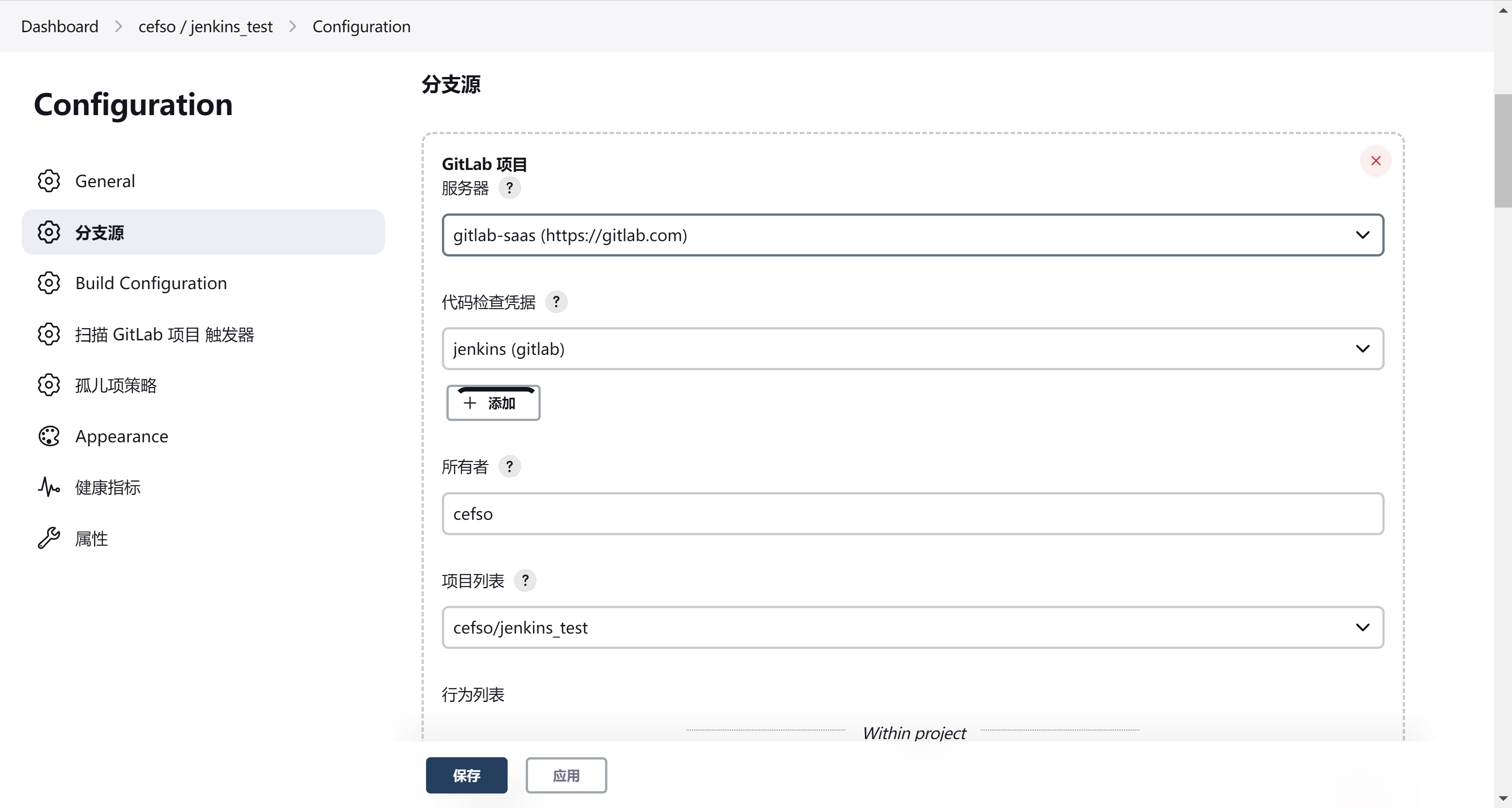
配置构建配置,这里就需要使用到我们上述创建的配置文件了
这里mode选择by default jenkinsfile,这个选项需要安装了pipeline-multibranch-defaults才可以找到,Script ID填写我们上面创建时配置文件的ID
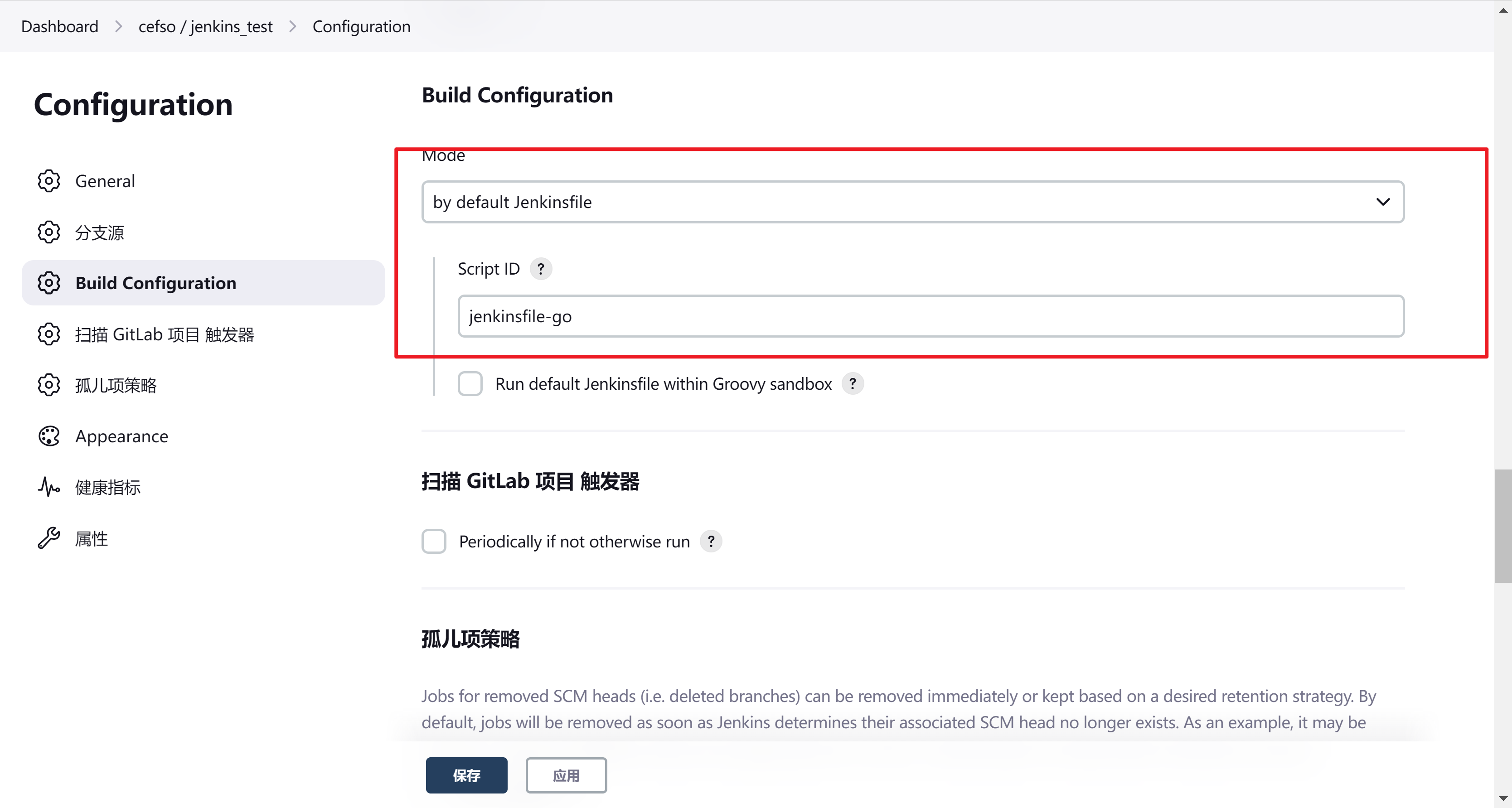
保存完成后我们就创建好了一个jenkins流水线
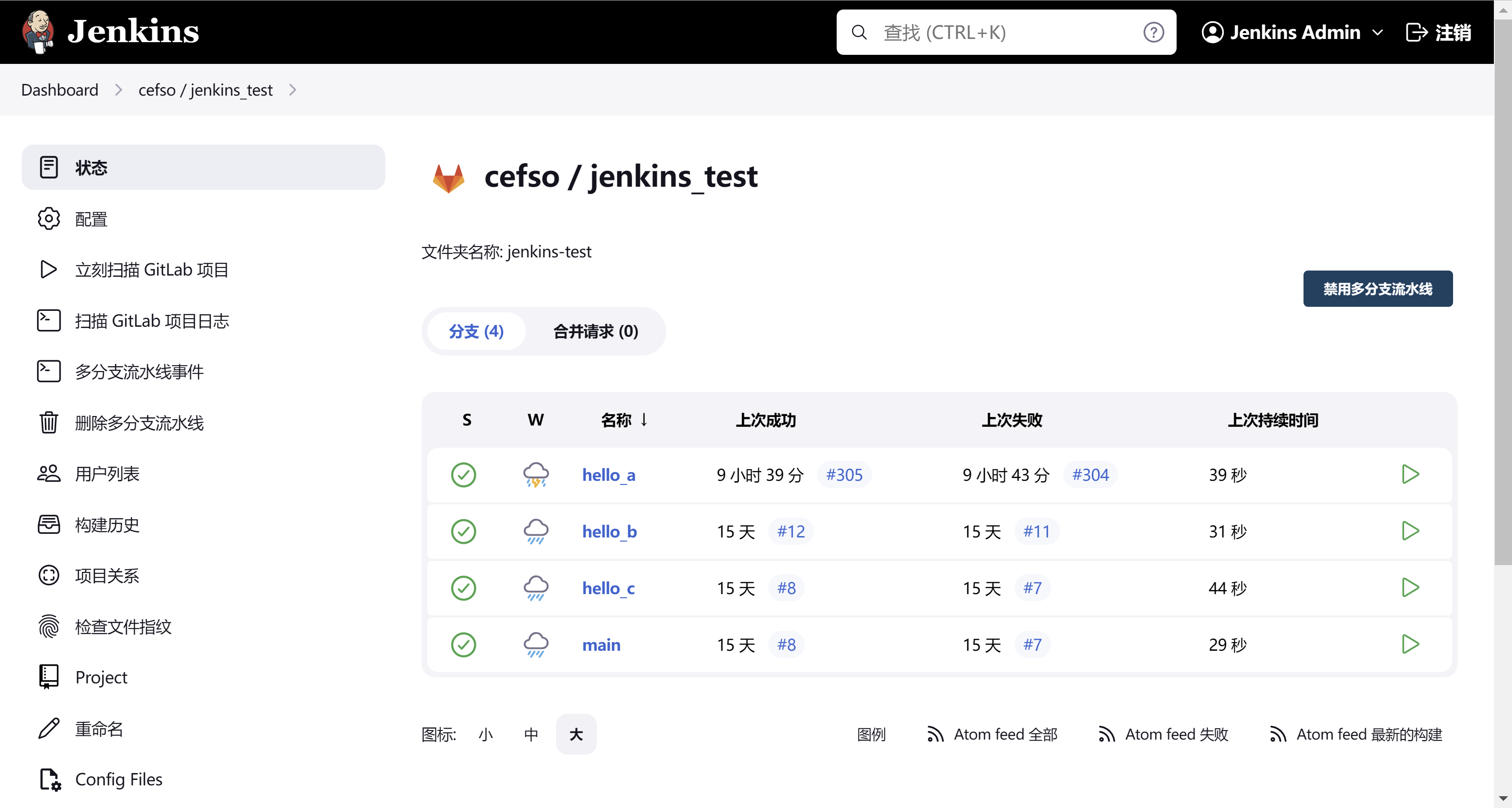
使用视图区分jenkins流水线工程不同分支
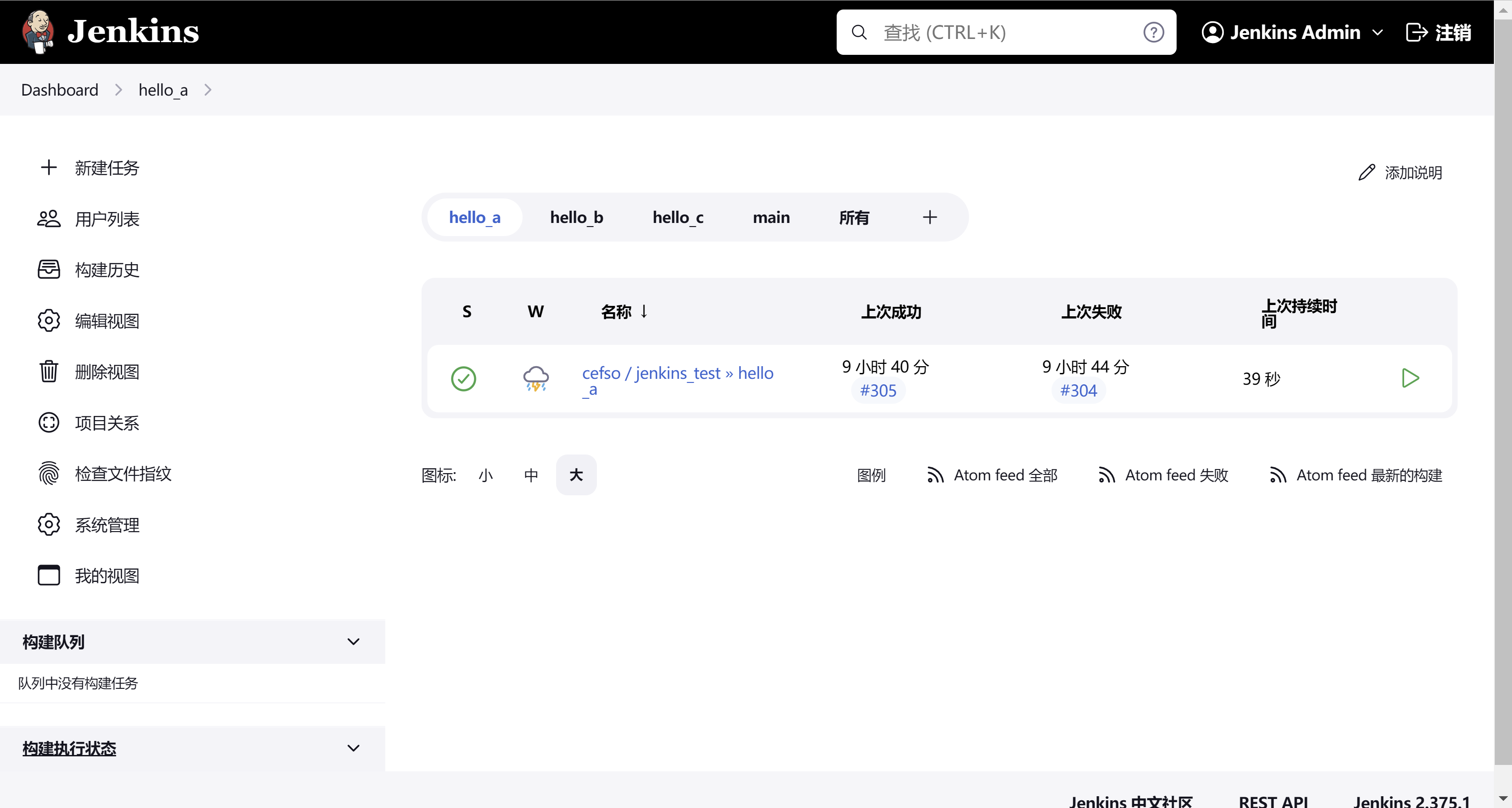
可以看到我这里创建了多个jenkins的视图,每个视图对应我们一个git分支
创建分支视图
jenkins选择新建视图
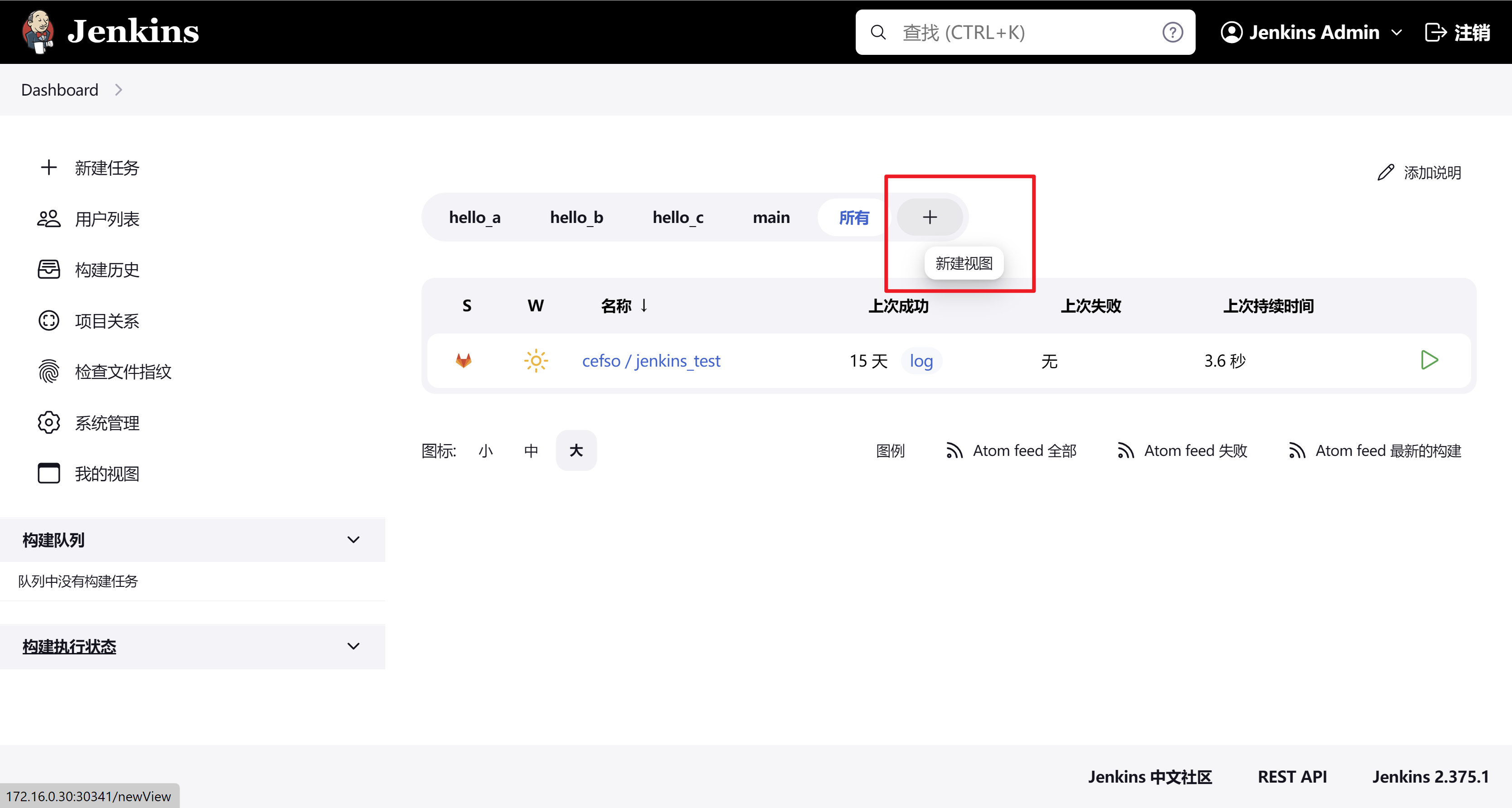
视图名称填写我们的分支名称,选择列表视图即可
任务过滤器选择遍历文件夹,使用正则表达式显示任务,正则表达式匹配我们的分支名称
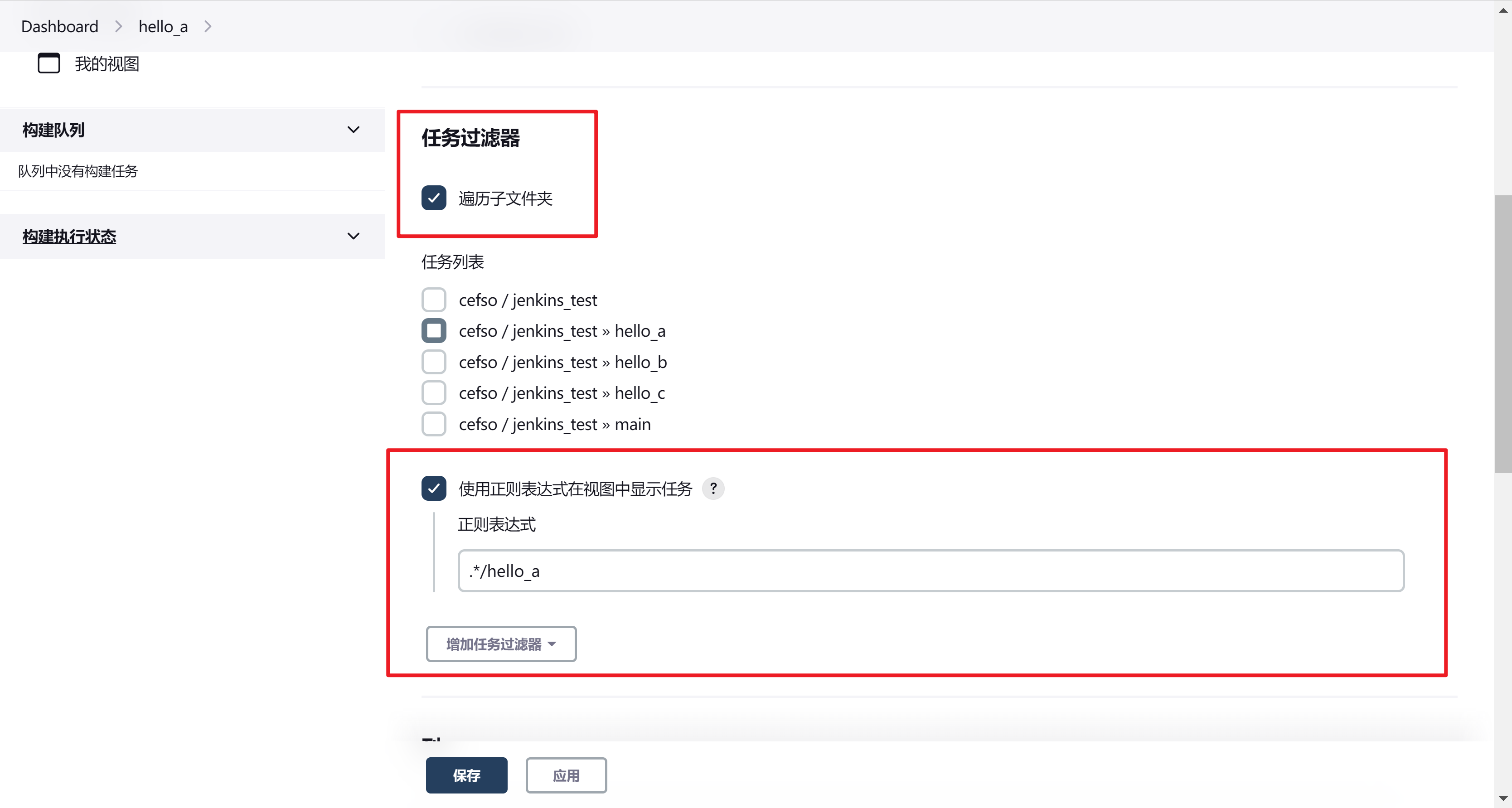
这样只要包含我们正则表达式匹配到的分支的应用都会在该视图下显示