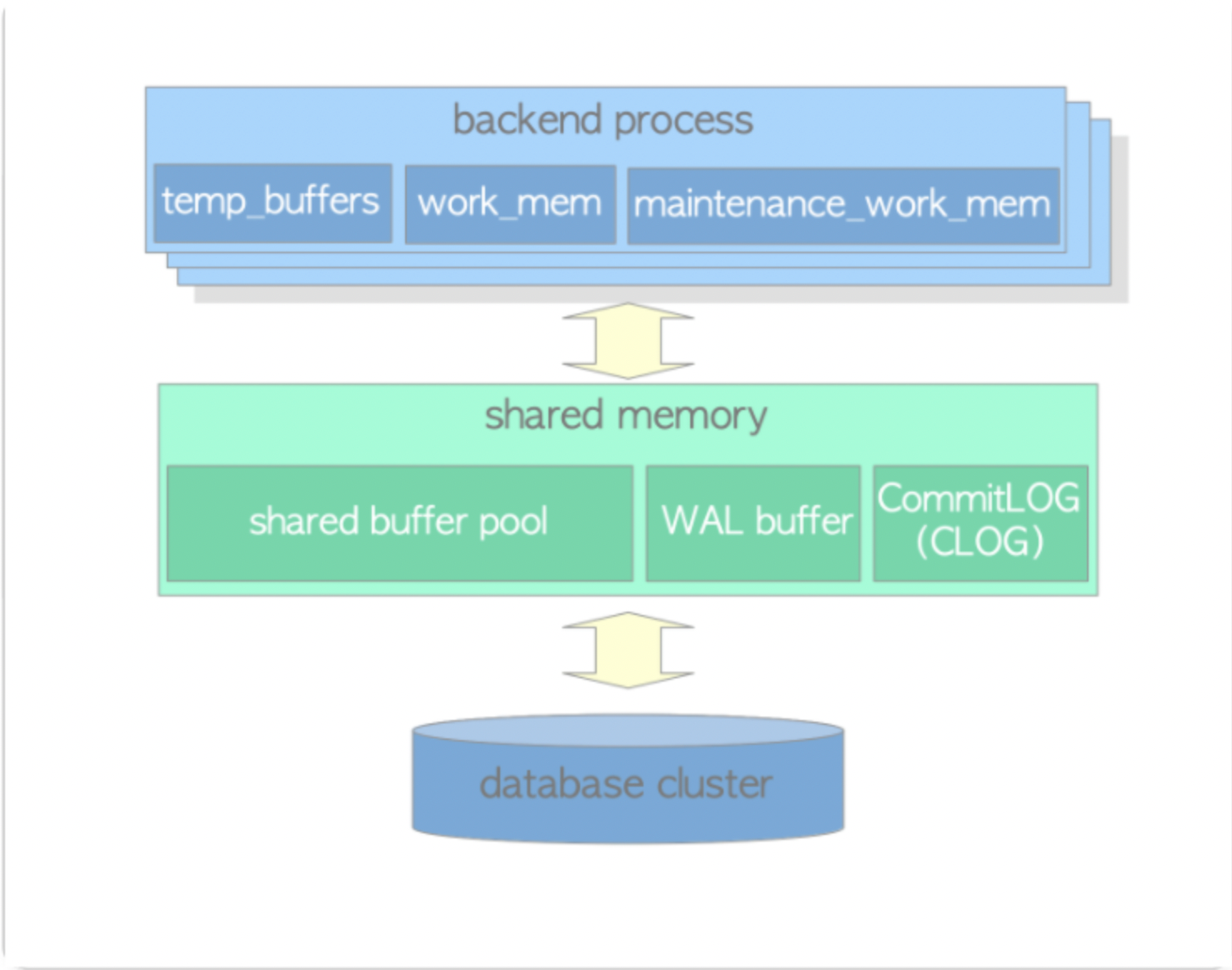
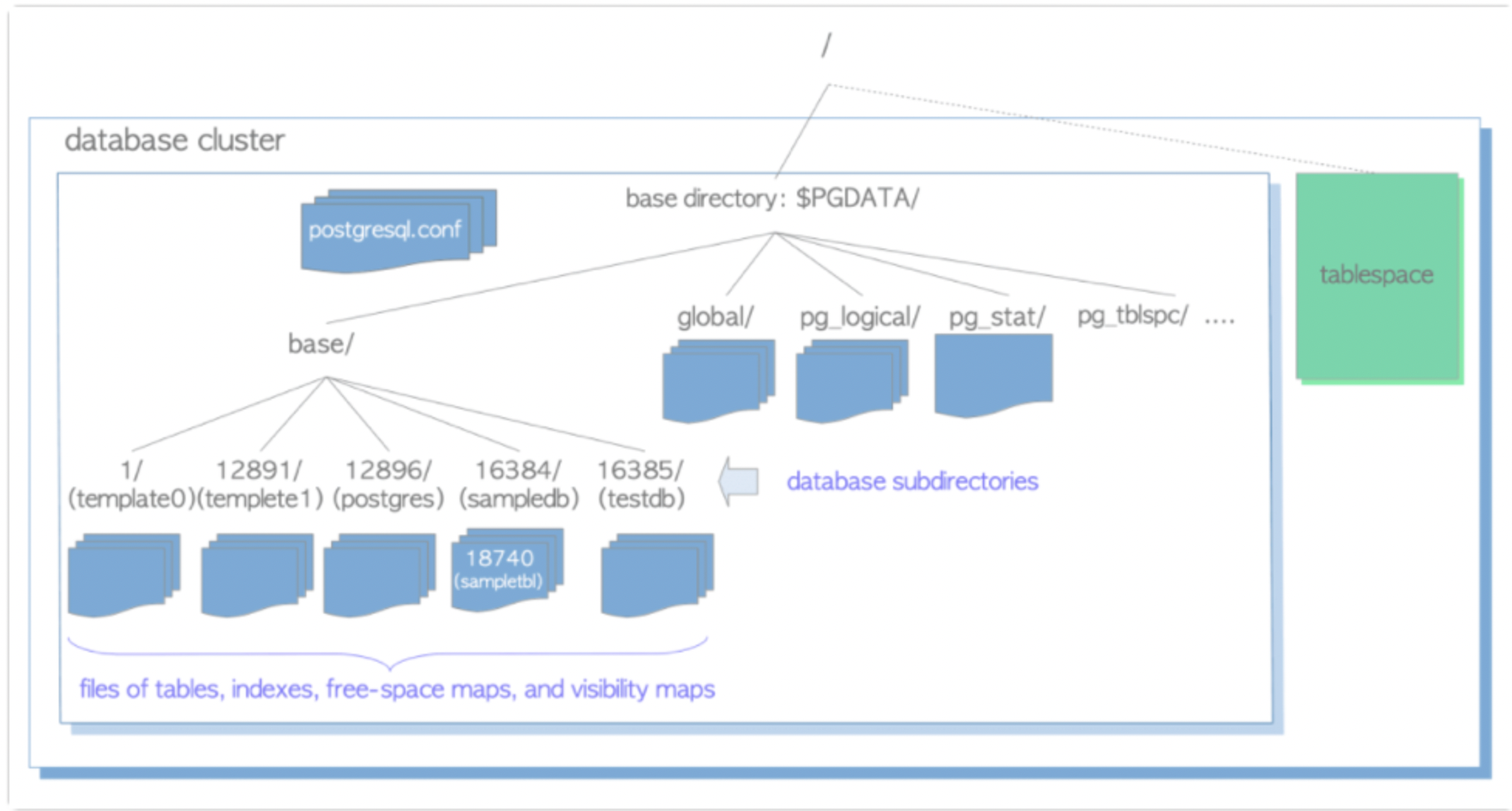
pgbench 压测工具
一、基本参数
pgbench工具是Postgres自带的一款轻量型基准压测工具。它自定义相关场景下脚本进行
1.1 初始化参数
参数 | 含义 |
-i / --initialize | 调用初始化模式 |
-I init_steps / --init-steps=init_steps | 初始化步骤:d(删除)、t(创建表)、g(生产数据)、v(清理)、p(创建主键)、f(创建外键) |
-F fillfactor / --fillfactor=fillfactor | 用给定的填充因子创建表,默认100 |
-n / --no-vacuum | 在初始化期间不做VACUUM,会抑制-Iv的操作 |
-q / --quiet | quiet模式输出,每5s产生一个进度消息 |
-s scale_factor / --scale=scale_factor | 指定生成表数据行数,实际生成行数= scale_factor * 100000,s默认为1 |
--foreign-keys | 为标准表创建外键约束(如果f在初始化步骤序列中不存在,这个选项会把它加入) |
--index-tablespace=index_tablespace | 指定表空间限制 |
--unlogged-tables | 把所有的表创建为非日志记录表而不是永久表。 |
1.2 基准测试选项
参数 | 含义 |
-b scriptname[@weight] / --builtin=scriptname[@weight] | 执行内建脚本,@后可指定调用该脚本的概率,默认为1 |
-c clients / --client=clients | 模拟客户端并发请求数,默认为1 |
-C / --connect | 为每个事务创建一个新连接,而不是为每个客户端创建一个新连接,该参数主要用于度量创建连接的消耗 |
-d / --debug | debug调试 |
-D varname=value / --define=varname=value | 指定用户自定义脚本中的自定义变量,允许同时使用多个-D |
-f filename[@weight] / --file=filename[@weight] | 指定用户自定义脚本参数,,@后可指定调用该脚本的概率,默认为1 |
-j threads / --jobs=threads | pgbench并发线程数 |
-l / --log | 打印日志 |
-L limit / --latency-limit=limit | 对于超过limit时间限制的事务进度单独的统计与报告,这些事务被认定为late事务 |
-M querymode / --protocol=querymode | 提交查询到服务端的协议:simple(使用简单查询协议)、extended(使用扩展查询协议)、prepared(使用带预备语句的扩展查询语句) |
-n / --no-vacuum | 在运行测试前不进行vacuum清理,若运行在一个非标准表测试场景下,该选项是必须的 |
-N / --skip-some-updates | 运行内建的简单更新脚本。这是-b simple-update的简写。 |
-P sec / --progress=sec | 每sec秒显示进度报告 |
-r / --report-latencies | 在基准结束后,报告平均的每个命令的每语句等待时间(从客户端的角度来说是执行时间) |
-R rate / --rate=rate | |
-s scale_factor / --scale=scale_factor | 在pgbench的输出中报告指定的比例因子。对于内建测试,这并非必需;正确的比例因子将通过对pgbench_branches表中的行计数来检测。不过,当只测试自定义基准(-f选项)时,比例因子将被报告为 1(除非使用了这个选项)。 |
-S / --select-only | 执行内建的只有选择的脚本,是-b select-only简写形式。 |
-t transactions / --transactions=transactions | 每个客户端执行事务数量,默认为10 |
-T seconds / --time=seconds | 指定基准测试运行时常,单位s.-t和-T是互斥的 |
-v / --vacuum-all | 在运行测试前清理所有四个标准的表。 |
--aggregate-interval=seconds | 聚集区间的长度(单位是秒),仅可以与-l选项一起使用 |
--log-prefix=prefix | 设置--log创建的日志文件的文件名前缀,默认是pgbench_log。 |
--progress-timestamp | 当显示进度(选项-P)时,使用一个时间戳(Unix 时间)取代从运行开始的秒数。单位是秒,在小数点后是毫秒精度。这可以有助于比较多种工具生成的日志。 |
--random-seed=SEED | |
--sampling-rate=rate |
1.3 普通选项
参数 | 含义 |
-h hostname / --host=hostname | 主机名 |
-p port / --port=port | 端口 |
-U login / --username=login | 数据库用户 |
-V / --version | 打印pgbench版本 |
-? / --help | 显示有关pgbench命令行参数的信息,并且退出 |
1.4 内建脚本
比较常见的内置脚本主要有: simple-update 、 select-only 、tpcb-like
$ pgbench -M prepared -v -r -P 1 -b select-only -c 5 -j 5 -T 120 -D scale=10000 -D range=500000 -Upostgres db1 -P 5
1.5 用户自定义脚本
1、自动变量

2、语法
脚本文件元命令以反斜线(\)开始并且通常延伸到行的末尾,不过它们也能够通过写一个反斜线回车继续到额外行。一个元命令和它的参数用空白分隔。支持的元命令是:
\if expression \elif expression \else \endif \set varname expression //设置变量 \sleep number [ us | ms | s ] //指定休眠时间 \setshell varname command [ argument ... ] //设置变量为shell执行命令结果,command和每个argument要么是一个文本常量,要么是一个引用了一个变量的:variablename \shell command [ argument ... ] //与\setshell相同,但是结果被抛弃。
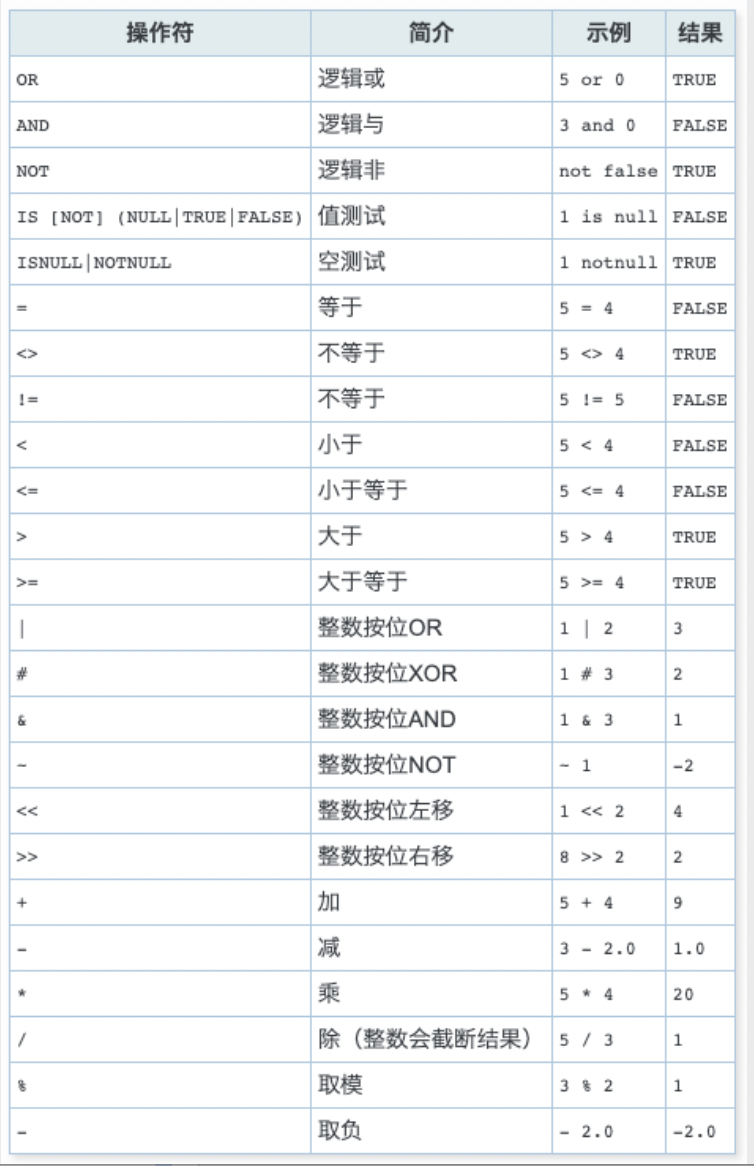
3、内建操作符
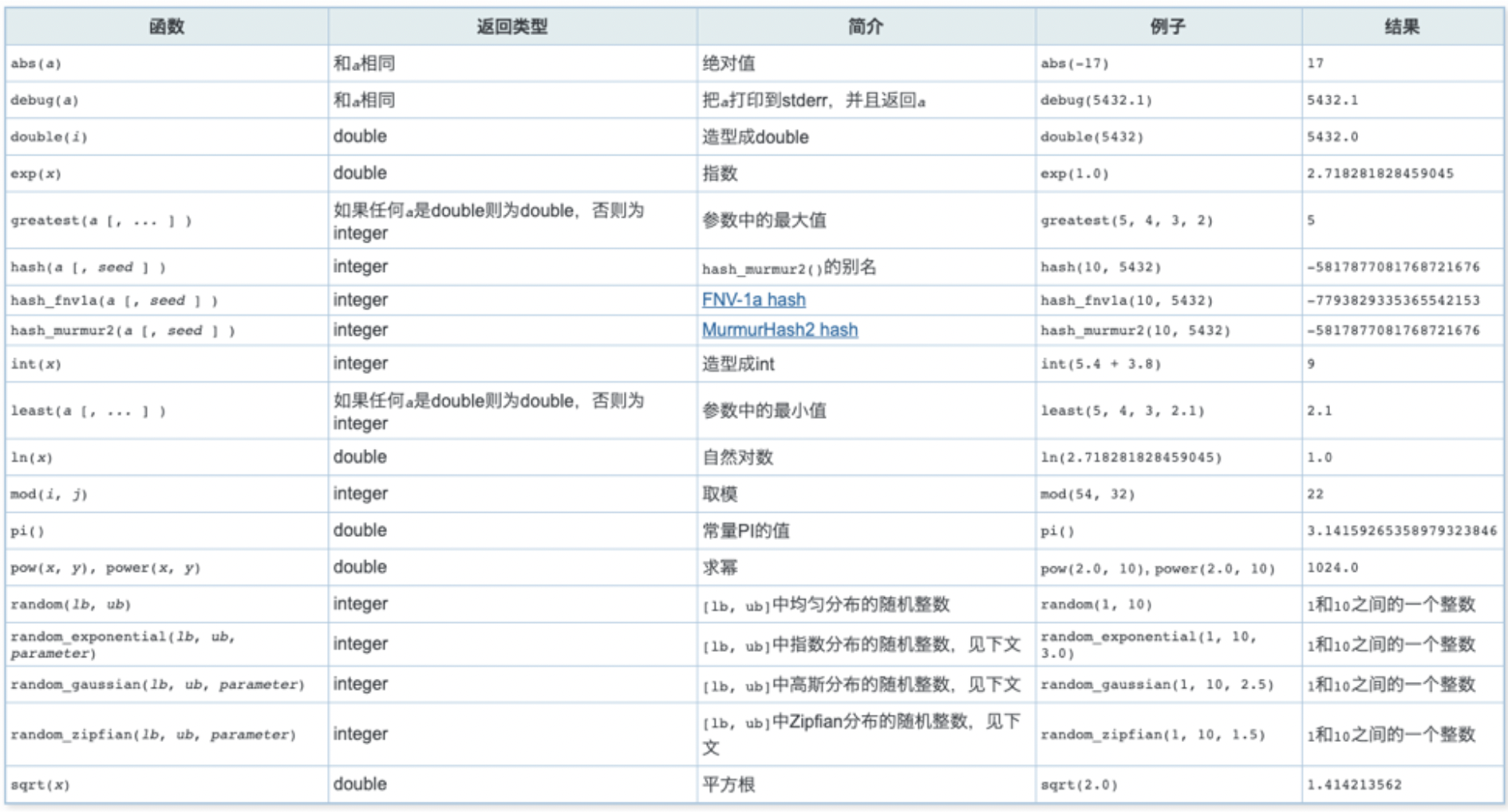
4、内建函数
二、基准压测
1、数据准备
$ pgbench -i db1 -Upostgres -s50 //实际数据量 = 50 * 100000 Password: dropping old tables... creating tables... generating data... 100000 of 5000000 tuples (2%) done (elapsed 0.11 s, remaining 5.40 s) 200000 of 5000000 tuples (4%) done (elapsed 0.20 s, remaining 4.81 s) ... 5000000 of 5000000 tuples (100%) done (elapsed 10.70 s, remaining 0.00 s) vacuuming... creating primary keys... done.
2、压测脚本准备
1)只读场景的脚本
$ vi ro.sql \set aid random_gaussian(1, :range, 10.0) SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
2)读写场景下的脚本
$ vi rw.sql \set aid random_gaussian(1, :range, 10.0) \set bid random(1, 1 * :scale) \set tid random(1, 10 * :scale) \set delta random(-5000, 5000) BEGIN; UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid; SELECT abalance FROM pgbench_accounts WHERE aid = :aid; UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid; UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid; INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP); END;
参数说明:
scale乘以10万:表示测试数据量 range:表示活跃数据量 -c:表示测试连接数
3、基准压测
1)只读场景
$ pgbench -M prepared -v -r -P 1 -f ./ro.sql -c 30 -j 30 -T 120 -D scale=10000 -D range=500000 -Upostgres db1 -P 5
2)读写场景
$ pgbench -M prepared -v -r -P 1 -f ./rw.sql -c 30 -j 30 -T 120 -D scale=10000 -D range=500000 -Upostgres db1 -P 5
4、关注指标
$ pgbench -M prepared -v -r -P 1 -f ./ro.sql -c 30 -j 30 -T 120 -D scale=10000 -D range=500000 -Upostgres db1 -P 5 transaction type: ./ro.sql scaling factor: 1 query mode: prepared number of clients: 30 number of threads: 30 duration: 120 s number of transactions actually processed: 3673930 latency average = 0.979 ms latency stddev = 0.210 ms tps = 30615.649501 (including connections establishing) tps = 30628.359592 (excluding connections establishing) statement latencies in milliseconds: 0.001 \set aid random_gaussian(1, :range, 10.0) 0.979 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;