
StorageClass(NFS)
一、什么是StorageClass
Kubernetes提供了一套可以自动创建PV的机制,即:Dynamic Provisioning.而这个机制的核心在于:StorageClass这个API对象.
StorageClass对象会定义下面两部分内容:
1,PV的属性.比如,存储类型,Volume的大小等.
2,创建这种PV需要用到的存储插件
有了这两个信息之后,Kubernetes就能够根据用户提交的PVC,找到一个对应的StorageClass,之后Kubernetes就会调用该StorageClass声明的存储插件,进而创建出需要的PV.
但是其实使用起来是一件很简单的事情,你只需要根据自己的需求,编写YAML文件即可,然后使用kubectl create命令执行即可
二、为什么需要StorageClass
在一个大规模的Kubernetes集群里,可能有成千上万个PVC,这就意味着运维人员必须实现创建出这个多个PV,此外,随着项目的需要,会有新的PVC不断被提交,那么运维人员就需要不断的添加新的,满足要求的PV,否则新的Pod就会因为PVC绑定不到PV而导致创建失败.而且通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求 而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了。
三、StorageClass运行原理及部署流程
1)StorageClass运行原理
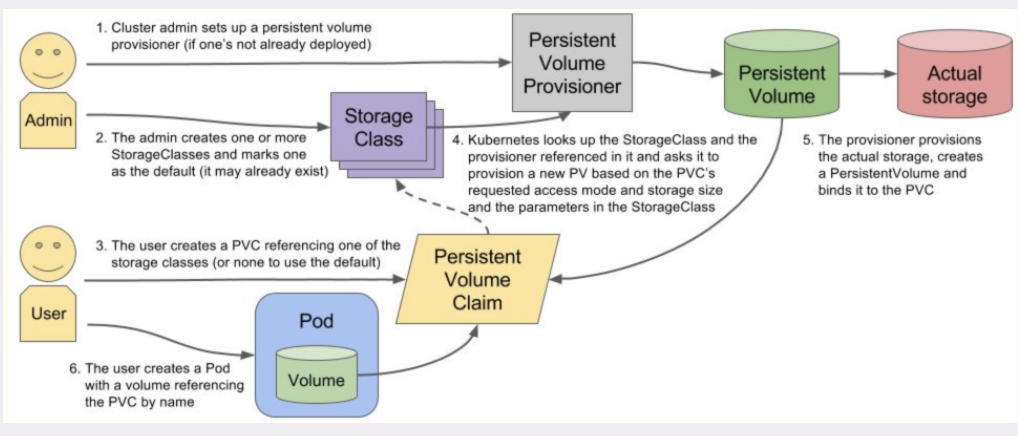
2)部署 StorageClass流程
创建或者选取一个 Namespace
创建 rbac,因为 StorageClass 有对应的 Pod 要运行,每个 pod 都有自己的身份即 ServiceAccount,而这个 serviceAccount 是和某个角色绑定的,所以需要创建 ServiceAccount、rule、rolebinding
创建 provisioner,即关联 NFS 工作类,负责给 PVC 提供存储资源,这里使用的是 nfs-client-provisione
创建 StorageClass,所有需要 PVC 通过该 StorageClass 即可获得存储
1.创建NFS共享服务
该步骤比较简单不在赘述,大家可以自行百度搭建
当前环境NFS server及共享目录信息
IP: 172.16.155.227 Export PATH: /data/volumes/
2.配置account及相关权限
rbac.yaml: #唯一需要修改的地方只有namespace,根据实际情况定义
apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default #根据实际环境设定namespace,下面类同 --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io
此处一定注意role以及RoleBinding一定要和pod或者pvc的namespace相同,否可能会导致pvc一直处于pending状态
3.创建NFS资源的StorageClass
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: managed-nfs-storage provisioner: qgg-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致parameters: archiveOnDelete: "false"
4.创建NFS provisioner
nfs-provisioner.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default #与RBAC文件中的namespace保持一致 spec: replicas: 1 selector: matchLabels: app: nfs-client-provisioner strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: qgg-nfs-storage #provisioner名称,请确保该名称与 nfs-StorageClass.yaml文件中的provisioner名称保持一致 - name: NFS_SERVER value: 172.16.155.227 #NFS Server IP地址 - name: NFS_PATH value: /data/volumes #NFS挂载卷 volumes: - name: nfs-client-root nfs: server: 172.16.155.227 #NFS Server IP地址 path: /data/volumes #NFS 挂载卷
5.创建测试pod,检查是否部署成功
创建PVC
test-claim.yaml
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: test-claim annotations: volume.beta.kubernetes.io/storage-class: "managed-nfs-storage" #与nfs-StorageClass.yaml metadata.name保持一致 spec: accessModes: - ReadWriteMany resources: requests: storage: 1Mi
确保PVC状态为Bound
[root@k8s-master-155-221 deploy]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE test-claim Bound pvc-aae2b7fa-377b-11ea-87ad-525400512eca 1Mi RWX managed-nfs-storage 2m48s [root@k8s-master-155-221 deploy]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-aae2b7fa-377b-11ea-87ad-525400512eca 1Mi RWX Delete Bound default/test-claim managed-nfs-storage 4m13s




