MySQL优化器特性(三)表关联之BKA(Batched Key Access)优化
单表range查询时,可以使用MRR优化,先对rowid进行排序,然后再回表查询数据。在表关联的时候,也可以使用类似的优化方法,先根据关联条件取出被关联表的rowid,将rowid缓存在join buffer中,对rowid进行排序后,再回表获取数据。
一个例子
执行计划
出于测试的目的,给查询加上BKA hint(或MRR hint),执行计划Extra中显示“Using join buffer (Batched Key Access)”,说明表关联时,使用了BKA优化。
mysql> explain select /*+ BKA(t2) */ * from tb t1, tb t2 where t1.a = t2.a and t1.c=2\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ref possible_keys: idx_c,idx_ab key: idx_c key_len: 5 ref: const rows: 32 filtered: 100.00 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: t2 partitions: NULL type: ref possible_keys: idx_ab key: idx_ab key_len: 5 ref: test.t1.a rows: 32 filtered: 100.00 Extra: Using join buffer (Batched Key Access) 2 rows in set, 1 warning (0.00 sec)
表结构
上述测试使用的表结构和数据:
mysql> show create table tb\G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int DEFAULT NULL, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `id` int NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`), KEY `idx_c` (`c`), KEY `idx_ab` (`a`,`b`) ) ENGINE=InnoDB AUTO_INCREMENT=321 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) mysql> select a,b,c , count(*) from tb group by a,b,c; +------+------+------+----------+ | a | b | c | count(*) | +------+------+------+----------+ | 1 | 1 | 1 | 32 | | 2 | 2 | 2 | 32 | | 3 | 3 | 3 | 32 | | 4 | 4 | 4 | 32 | | 5 | 5 | 5 | 32 | | 6 | 6 | 6 | 32 | | 7 | 7 | 7 | 32 | | 8 | 8 | 8 | 32 | | 9 | 9 | 9 | 32 | | 10 | 10 | 10 | 32 | +------+------+------+----------+ 10 rows in set (0.00 sec)
使用场景
和单表MRR优化类似,表关联时使用BKA优化有一些前提条件:
1、被驱动表的关联字段存在二级索引。如果使用被驱动表的关联条件是主键,则不会采用BKA优化。
2、需要回表访问被关联表。如果在查询中,被驱动表访问的字段都在索引中,不需要回表,则不会采用BKA优化。
3、使用BKA的执行计划成本比默认的Nest loop关联低,或者查询中添加了BKA或MRR hint。
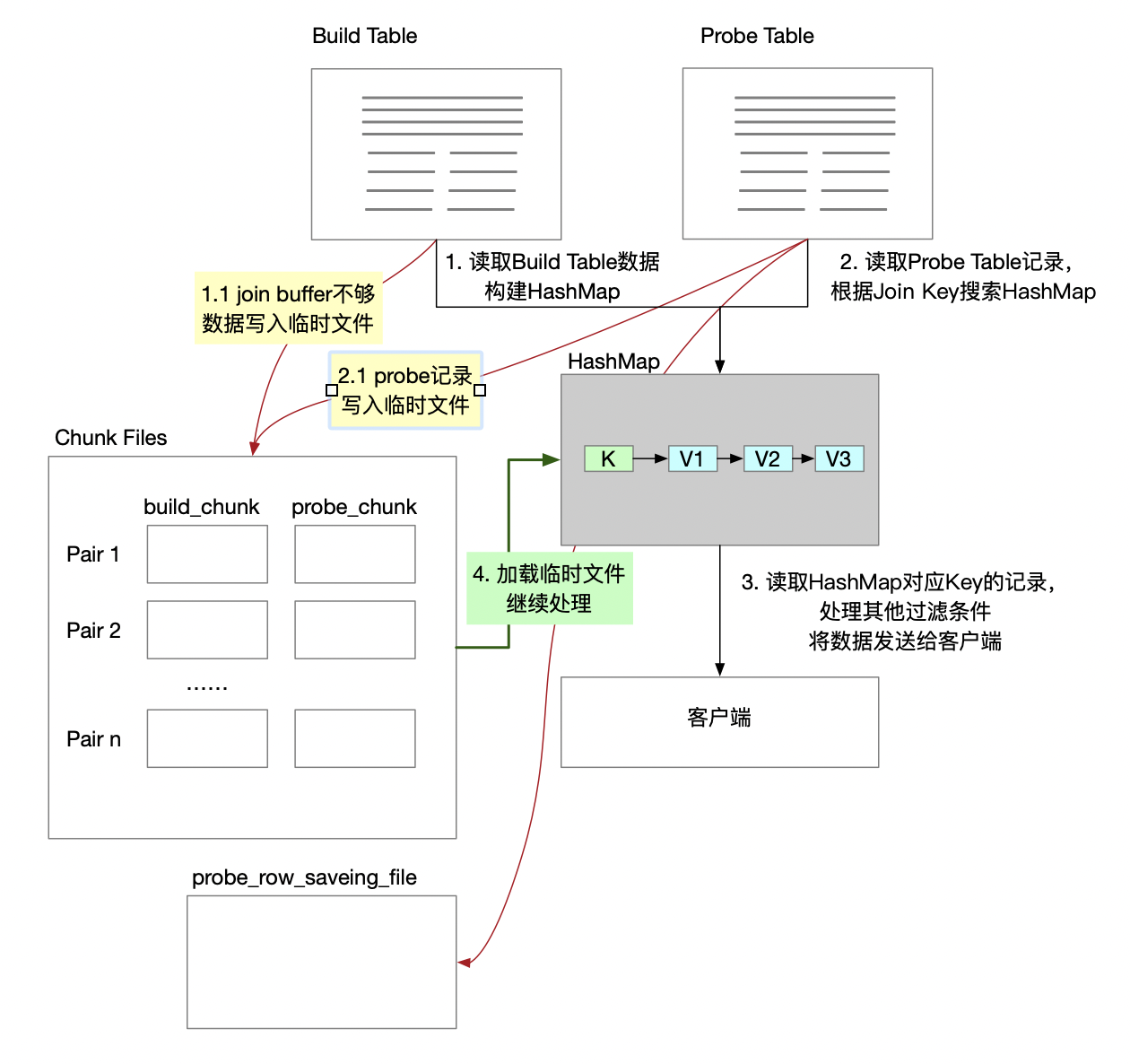
BKA Join执行过程

使用BKA算法关联,会用到Join Buffer。BKA关联执行过程大致如下:
第一阶段:往join buffer中写入驱动表的数据
1、获取驱动表的数据。将获取到的数据缓存到Join Buffer中。
2、评估驱动表的一条记录,需要占用多少内存。包括记录本身的长度,加上存放对应的被驱动表rowid需要的空间。
3、如果join buffer空间够,则继续往join buffer中加入驱动表记录。否则,分配MRR buffer,进入下一阶段。
第二阶段:填充MRR buffer
根据缓存的驱动表的记录,扫描被驱动表的索引,将得到的rowid缓存到MRR buffer中。
填充完成后对MRR buffer按rowid进行排序。
第三阶段:获取被驱动表的记录
1、根据rowid回表获取数据。
2、读取驱动表缓存在join buffer中的数据。
3、关联数据,并将关联后的数据返回给客户端。
如果数据还没有处理完成,重复以上几个阶段。
总结
BKA Join在实际中可能并不常见。不过通过学习BKA Join的实现方式,可以了解MySQL如何使用join buffer,也能帮我们更好地理解表关联在代码层面是如何实现的。
(本文的描述,以及SQL和执行计划基于mysql 8.0.31版本)