PG的多版本并发控制(三)
三、多版本并发控制
3.1 常见多版本并发的实现方式
第一种方式是,数据库仅保存最新版本数据,将发生变更的旧行版本数据写到其他地方如undo,当需要读取旧版本数据时,通过undo重构。oracle和MySQL就是通过undo的方式实现。
第二种方式是,数据库保存所有行版本数据,当需要读取旧版本数据时直接读取即可,数据库通过一定的机制定时回收无限的行版本数据释放物理空间。postgres数据库就是通过该方式实现,SQL Server使用的方式也类似这种方式,不过它会将旧版本数据保存在tmpdb中。
3.2 PG多版本并发控制实现原理
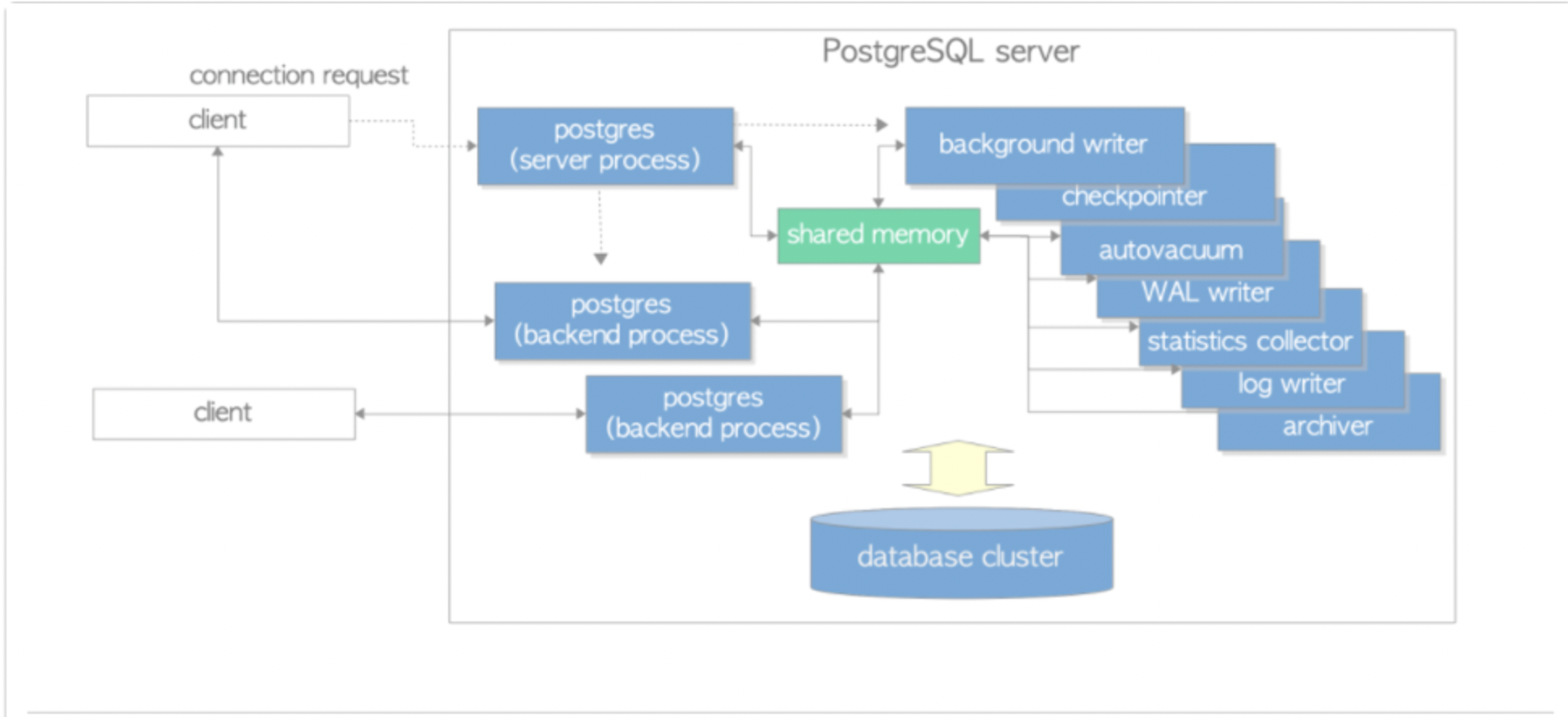
Postgres数据库保留旧版本数据在数据文件中,也就是对于delete操作pg数据库并不会将该记录行进行物理删除,而仅仅是做了一个删除打标而已,且每个数据行中额外存储xmin、xmax、ctid的系统信息。
每条语句执行是都会去查看当前事务的事务快照信息,事务快照反应了当前并发事务中所有活跃与非活跃的事务ID信息
clog记录了所有事务的事务状态
PG数据库根据tuple的xmin、xmax、当前的事务快照信息、clog事务状态、以及当前隔离级别,根据一定的规则确定对应tuple是否可见,其规则相对比较复杂,具体信息可见:http://www.interdb.jp/pg/pgsql05.html 中 5.6. Visibility Check Rules
3.3 PG并发版本控制所必要的一些维护操作
旧版本数据需要清理,旧版本数据一定程度上会导致查询变慢,因为旧版本数据仍然存在数据文件中,会导致查询扫描更多的数据块。
删除没有必要的clog
当事务达到一定上限必须通过冻结事务来避免事务回卷
更新FSM,VM和统计信息
FSM : 空闲空间映射,以.fsm进行存储。所有表和索引都有各自的FSM,每个FSM在相应的表或索引文件中存储有关每个页面的可用空间容量的信息。
PG多版本并发的一些优势:
事务回滚可立刻完成,无论事务执行了多少操作
数据可以进行很多更新,不必像oracle和innodb那样需要保证回滚段不会被用完