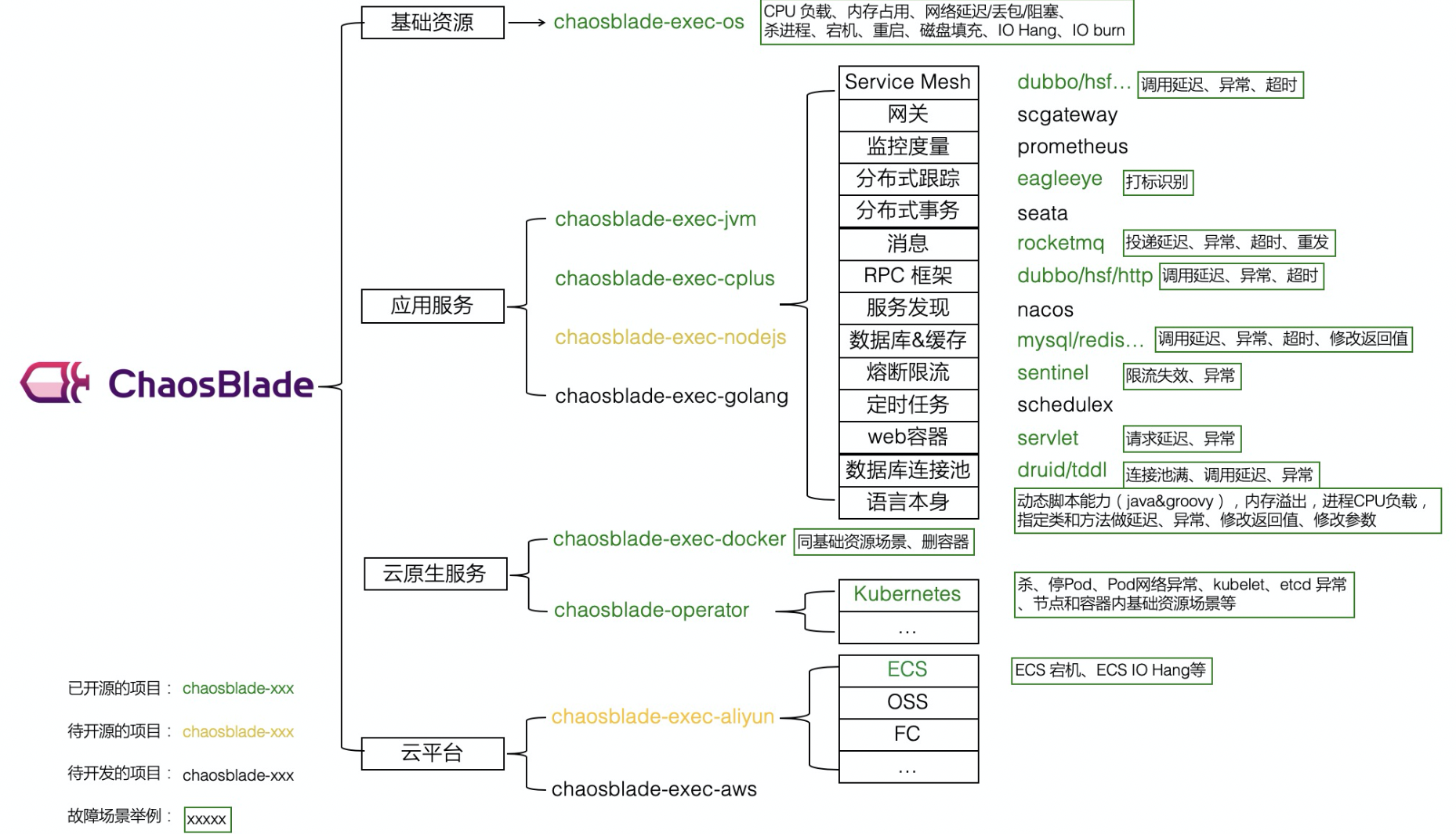
spark指标性能分析
1) Spark的性能指标
任务启动后可以在yarn的原生页面看到对应的任务信息,点击ApplicationMaster
后可以跳转到spark原生页面查看任务信息。

job信息:

Executor信息:在启动命令中可以设置excutor的个数

具体每个批次的执行的数据量,延迟时间,处理时间等。

进入每个批次后,能够看到这个批次执行的具体数据,也就是具体消费了哪些数据;这些数据能够精确到具体的分区和具体的数据量。

2) Spark的调优参数
l 并行度调优:如果每个批次消费正常,但是性能慢,可以增加消费并行度,并且增加kafka的分区数。
l 批次时间优化:修改以下客户端参数,提升批次的处理时间
参数 | 默认值 | 意义 |
spark.authenticate.enableSaslEncryption | false | |
spark.reducer.maxSizeInFlight | 96MB | |
spark.shuffle.file.buffer | 64KB | |
spark.authenticate | false | |
spark.network.sasl.serverAlwaysEncrypt | false | |
spark.shuffle.service.enabled | false | |
spark.streaming.kafka.consumer.poll.ms | 0 | Executor Consumer拉去一次数据的超时时间 |
l Kafka消费端参数调优:
参数 | 默认值 | 意义 |
max.poll.records | 500 | Consumer一次拉取得数据量,调大该值能够提升一个消费线程的吞吐量,减少对kafka的请求数。 |
metadata.max.age.ms | 30000ms | 元数据更新时间,建议这个值不大于spark.streaming.kafka.consumer.poll.ms值的1/2 |
session.time.out | 10000 | 组管理协议中判定consumer是否失效的超时时间,建议将这个值调整到30000以上 |
3) 问题排查流程
如果想查看具体是哪个task的问题,需要具体的分析一下task的日志信息。查看路径如下:
1. 找到具体的批次,例如:

2. 进入后,能够看到具体的jobID的执行时间

3. 选中其中的一个延时较长的job,点击进入后继续选择时间较长的Description

4. 进入后选择,对应的日志进行分析

5. 日志中能够反映出,每个Excutor consumer的配置文件信息,如下:

能够反映出每个task的执行间隔时间:

如果执行时间间隔较长,需要分析jstack信息。
6. 根据第4步中的Excutor的id(图中为7),可以查看Tread dump信息,查看具体线程哪里有异常。