Prometheus集成pushgateway监控k8s集群
Prometheus部署
环境介绍
本文的k8s环境是通过二进制方式搭建的v1.20.13版本
清单准备
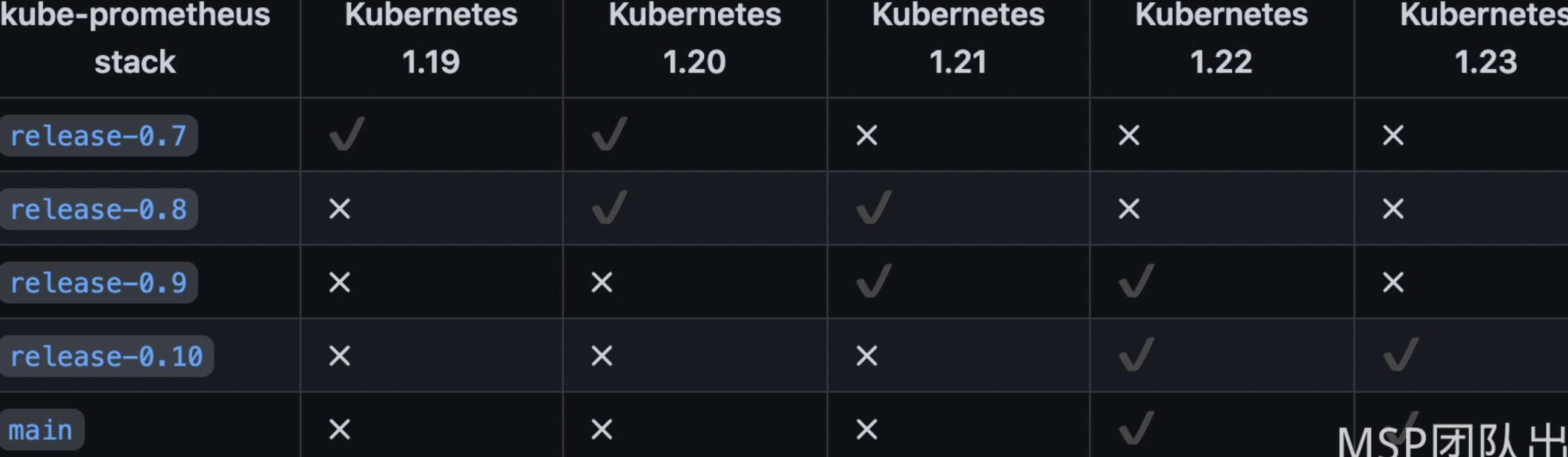
注意集群版本的坑,自己先到Github上下载对应的版本。
注意: 集群版本在v1.21.x之前需要注意下载对应分支的安装包,否则可能会有问题。集群版本和适配分支对应关系如下:
部署prometheus
下载安装包,下载命令:
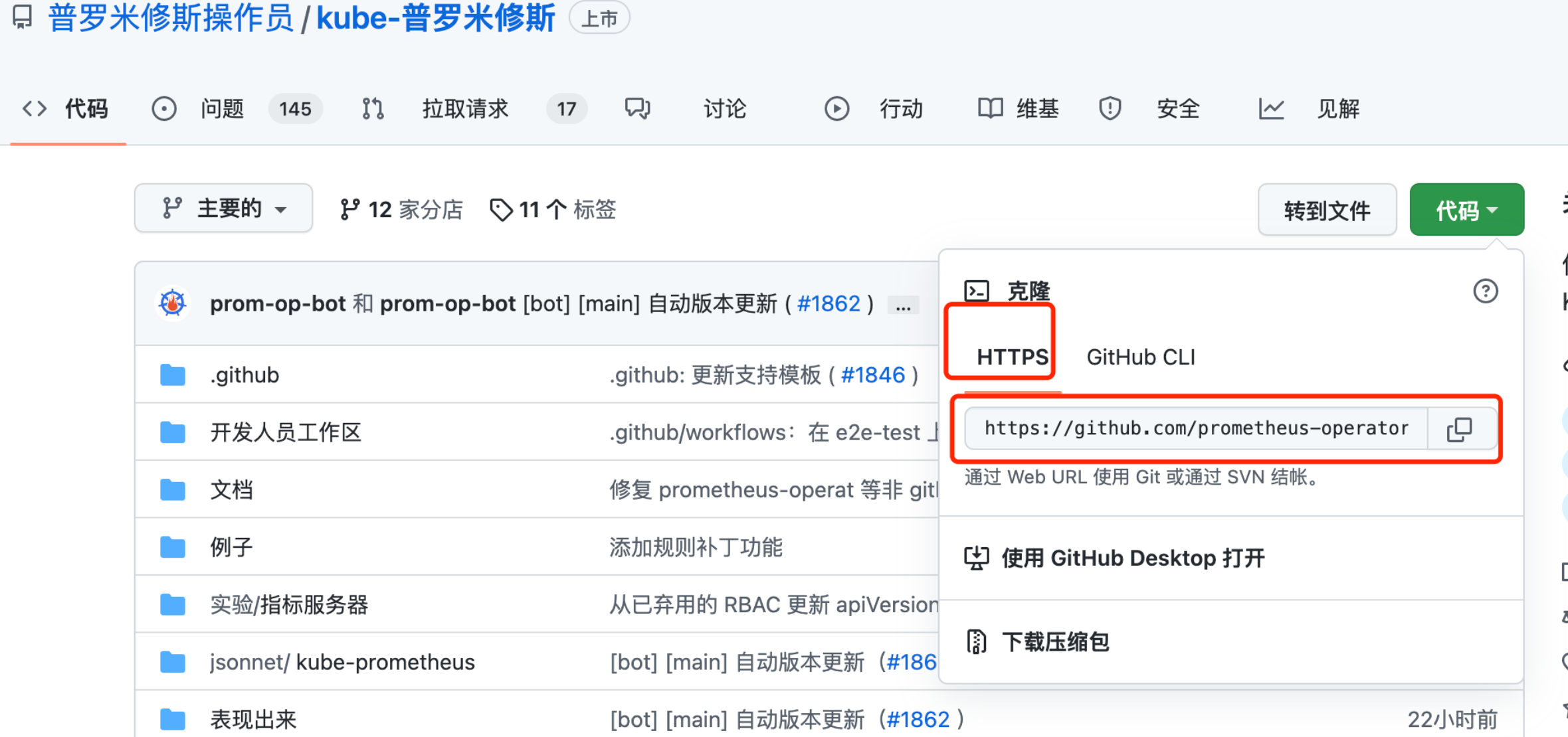
git clone https://github.com/prometheus-operator/kube-prometheus.git
下载指定版本的
git clone -b release-0.7 https://gh.con.sh/https://github.com/prometheus-operator/kube-prometheus.git
下载完成之后解压,并执行安装命令:
进入kube-prometheus/manifests/setup,就可以直接创建CRD对象:
[root@master01 kube-prometheus-main]# kubectl apply --server-side -f manifests/setup customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied namespace/monitoring serverside-applied
可以看到创建如下的CRD对象:
[root@master01 prometheus-Operator]# kubectl get crd | grep coreos alertmanagerconfigs.monitoring.coreos.com 2021-12-16T12:17:58Z alertmanagers.monitoring.coreos.com 2021-12-16T07:03:11Z podmonitors.monitoring.coreos.com 2021-12-16T12:17:58Z probes.monitoring.coreos.com 2021-12-16T12:17:58Z prometheuses.monitoring.coreos.com 2021-12-16T07:03:11Z prometheusrules.monitoring.coreos.com 2021-12-16T07:03:11Z servicemonitors.monitoring.coreos.com 2021-12-16T07:03:11Z thanosrulers.monitoring.coreos.com 2021-12-16T12:17:58Z
然后在上层目录创建资源清单:
[root@master01 kube-prometheus-main]# kubectl apply -f manifests/ alertmanager.monitoring.coreos.com/main created prometheusrule.monitoring.coreos.com/alertmanager-main-rules created secret/alertmanager-main created service/alertmanager-main created serviceaccount/alertmanager-main created servicemonitor.monitoring.coreos.com/alertmanager-main created clusterrole.rbac.authorization.k8s.io/blackbox-exporter created clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created configmap/blackbox-exporter-configuration created deployment.apps/blackbox-exporter created service/blackbox-exporter created serviceaccount/blackbox-exporter created servicemonitor.monitoring.coreos.com/blackbox-exporter created secret/grafana-config created secret/grafana-datasources created configmap/grafana-dashboard-alertmanager-overview created configmap/grafana-dashboard-apiserver created configmap/grafana-dashboard-cluster-total created configmap/grafana-dashboard-controller-manager created configmap/grafana-dashboard-k8s-resources-cluster created configmap/grafana-dashboard-k8s-resources-namespace created configmap/grafana-dashboard-k8s-resources-node created configmap/grafana-dashboard-k8s-resources-pod created configmap/grafana-dashboard-k8s-resources-workload created configmap/grafana-dashboard-k8s-resources-workloads-namespace created configmap/grafana-dashboard-kubelet created configmap/grafana-dashboard-namespace-by-pod created configmap/grafana-dashboard-namespace-by-workload created configmap/grafana-dashboard-node-cluster-rsrc-use created configmap/grafana-dashboard-node-rsrc-use created configmap/grafana-dashboard-nodes created configmap/grafana-dashboard-persistentvolumesusage created configmap/grafana-dashboard-pod-total created configmap/grafana-dashboard-prometheus-remote-write created configmap/grafana-dashboard-prometheus created configmap/grafana-dashboard-proxy created configmap/grafana-dashboard-scheduler created configmap/grafana-dashboard-workload-total created configmap/grafana-dashboards created deployment.apps/grafana created service/grafana created serviceaccount/grafana created servicemonitor.monitoring.coreos.com/grafana created prometheusrule.monitoring.coreos.com/kube-prometheus-rules created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created service/kube-state-metrics created serviceaccount/kube-state-metrics created servicemonitor.monitoring.coreos.com/kube-state-metrics created prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created servicemonitor.monitoring.coreos.com/kube-apiserver created servicemonitor.monitoring.coreos.com/coredns created servicemonitor.monitoring.coreos.com/kube-controller-manager created servicemonitor.monitoring.coreos.com/kube-scheduler created servicemonitor.monitoring.coreos.com/kubelet created clusterrole.rbac.authorization.k8s.io/node-exporter created clusterrolebinding.rbac.authorization.k8s.io/node-exporter created daemonset.apps/node-exporter created prometheusrule.monitoring.coreos.com/node-exporter-rules created service/node-exporter created serviceaccount/node-exporter created servicemonitor.monitoring.coreos.com/node-exporter created clusterrole.rbac.authorization.k8s.io/prometheus-k8s created clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created prometheus.monitoring.coreos.com/k8s created prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s-config created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created service/prometheus-k8s created serviceaccount/prometheus-k8s created servicemonitor.monitoring.coreos.com/prometheus-k8s created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created clusterrole.rbac.authorization.k8s.io/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created configmap/adapter-config created deployment.apps/prometheus-adapter created rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created service/prometheus-adapter created serviceaccount/prometheus-adapter created servicemonitor.monitoring.coreos.com/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created prometheusrule.monitoring.coreos.com/prometheus-operator-rules created service/prometheus-operator created serviceaccount/prometheus-operator created servicemonitor.monitoring.coreos.com/prometheus-operator created unable to recognize "manifests/alertmanager-podDisruptionBudget.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1" unable to recognize "manifests/prometheus-podDisruptionBudget.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1" unable to recognize "manifests/prometheusAdapter-podDisruptionBudget.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1"
可以看到有三个资源没有正常创建,需要修改下yaml文件。
将:apiVersion: policy/v1beta1 修改为:apiVersion: policy/v1beta1
然后重新创建资源:
[root@master01 manifests]# kubectl apply -f alertmanager-podDisruptionBudget.yaml poddisruptionbudget.policy/alertmanager-main created [root@master01 manifests]# kubectl apply -f prometheus-podDisruptionBudget.yaml poddisruptionbudget.policy/prometheus-k8s created [root@master01 manifests]# kubectl apply -f prometheusAdapter-podDisruptionBudget.yaml poddisruptionbudget.policy/prometheus-adapter created
查看创建的pod:
[root@master01 prometheus-Operator]# kubectl get pod -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 6d alertmanager-main-1 2/2 Running 0 6d alertmanager-main-2 2/2 Running 0 6d blackbox-exporter-6798fb5bb4-mwdkt 3/3 Running 0 6d grafana-d7f564887-fd7m2 1/1 Running 0 6d kube-state-metrics-7b8ccf569-nxcxv 3/3 Running 0 5d20h node-exporter-2pgfm 2/2 Running 0 6d node-exporter-chcfv 2/2 Running 2 6d node-exporter-kfgth 2/2 Running 0 6d node-exporter-pvvm2 2/2 Running 0 6d node-exporter-vwpzr 2/2 Running 0 6d node-exporter-zcm82 2/2 Running 0 6d prometheus-adapter-56b57579b4-hrb7x 1/1 Running 0 5d23h prometheus-adapter-56b57579b4-t5dzv 1/1 Running 0 5d23h prometheus-k8s-0 2/2 Running 0 6d prometheus-k8s-1 2/2 Running 0 6d prometheus-operator-66cf6bd9c6-xcxjp 2/2 Running 0 6d
查看创建的Service:
[root@master01 prometheus-Operator]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main ClusterIP 10.254.30.198 <none> 9093/TCP,8080/TCP 6d alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 6d blackbox-exporter ClusterIP 10.254.83.3 <none> 9115/TCP,19115/TCP 6d grafana ClusterIP 10.254.132.62 <none> 3000/TCP 6d kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 6d node-exporter ClusterIP None <none> 9100/TCP 6d prometheus-adapter ClusterIP 10.254.27.119 <none> 443/TCP 6d prometheus-k8s ClusterIP 10.254.12.222 <none> 9090/TCP,8080/TCP 6d prometheus-operated ClusterIP None <none> 9090/TCP 6d prometheus-operator ClusterIP None <none> 8443/TCP 6d
看到我们常用的prometheus和grafana都是clustorIP,我们要外部访问可以配置为NodePort类型或者用ingress。配置ingress:
配置prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: prometheus-ingress # Ingress 的名字,仅用于标识 namespace: monitoring spec: ingressClassName: nginx rules: # Ingress 中定义 L7 路由规则 - host: prometheus.com # 根据 virtual hostname 进行路由(请使用您自己的域名) http: paths: # 按路径进行路由 - path: / backend: serviceName: prometheus-k8s # 指定后端的 Service 为之前创建的 nginx-service servicePort: 9090
配置grafana-ingress.yaml
apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: grafana-ingress # Ingress 的名字,仅用于标识 namespace: monitoring spec: ingressClassName: nginx rules: # Ingress 中定义 L7 路由规则 - host: grafana.com # 根据 virtual hostname 进行路由(请使用您自己的域名) http: paths: # 按路径进行路由 - path: / backend: serviceName: grafana # 指定后端的 Service 为之前创建的 nginx-service servicePort: 3000
查看ingress
[root@master01 manifests]# kubectl get ingress -n monitoring NAME CLASS HOSTS ADDRESS PORTS AGE grafana-ingress nginx grafana.com 10.254.174.120 80 42h prometheus-ingress nginx prometheus.com 10.254.174.120 80 44h
部署prometheus-pushgateway
cd /root/kube-prometheus/manifests/pushgateway
[root@test-master-65 pushgateway]# cat pushgateway-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: prometheus-pushgateway
name: prometheus-pushgateway
namespace: monitoring
spec:
selector:
matchLabels:
k8s-app: prometheus-pushgateway
replicas: 1
template:
metadata:
labels:
k8s-app: prometheus-pushgateway
component: "prometheus-pushgateway"
spec:
serviceAccountName: prometheus-pushgateway
containers:
- name: prometheus-pushgateway
image: "prom/pushgateway:v0.5.2"
imagePullPolicy: "IfNotPresent"
args:
ports:
- containerPort: 9091
readinessProbe:
httpGet:
path: /#/status
port: 9091
initialDelaySeconds: 10
timeoutSeconds: 10
resources:
{}[root@test-master-65 pushgateway]# cat pushgateway-serviceaccount.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: prometheus-pushgateway name: prometheus-pushgateway namespace: monitoring You have mail in /var/spool/mail/root
[root@test-master-65 pushgateway]# cat pushgateway-service.yaml apiVersion: v1 kind: Service metadata: annotations: prometheus.io/probe: pushgateway labels: k8s-app: prometheus-pushgateway name: prometheus-pushgateway namespace: monitoring spec: ports: - name: http port: 9091 protocol: TCP targetPort: 9091 nodePort: 31014 selector: k8s-app: prometheus-pushgateway component: "prometheus-pushgateway" # type: LoadBalancer # NodePort
参考文章: https://github.com/prometheus/pushgateway
查看grafana监控数据
1、登陆grafana
2、核查已接入数据源
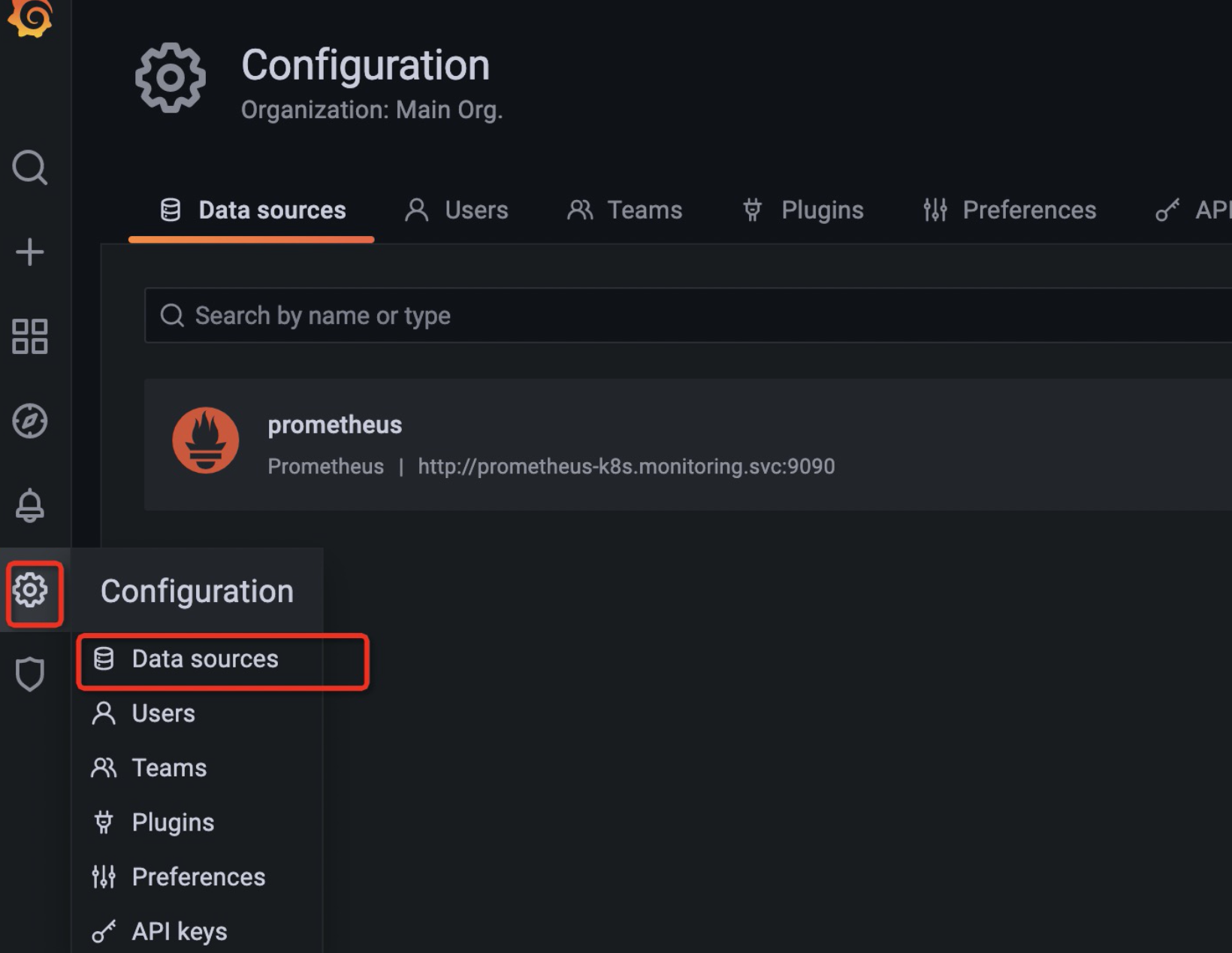
默认已将prometheus数据源接入
3、单击 Home 下拉菜单,选择已配置好的 dashboard。
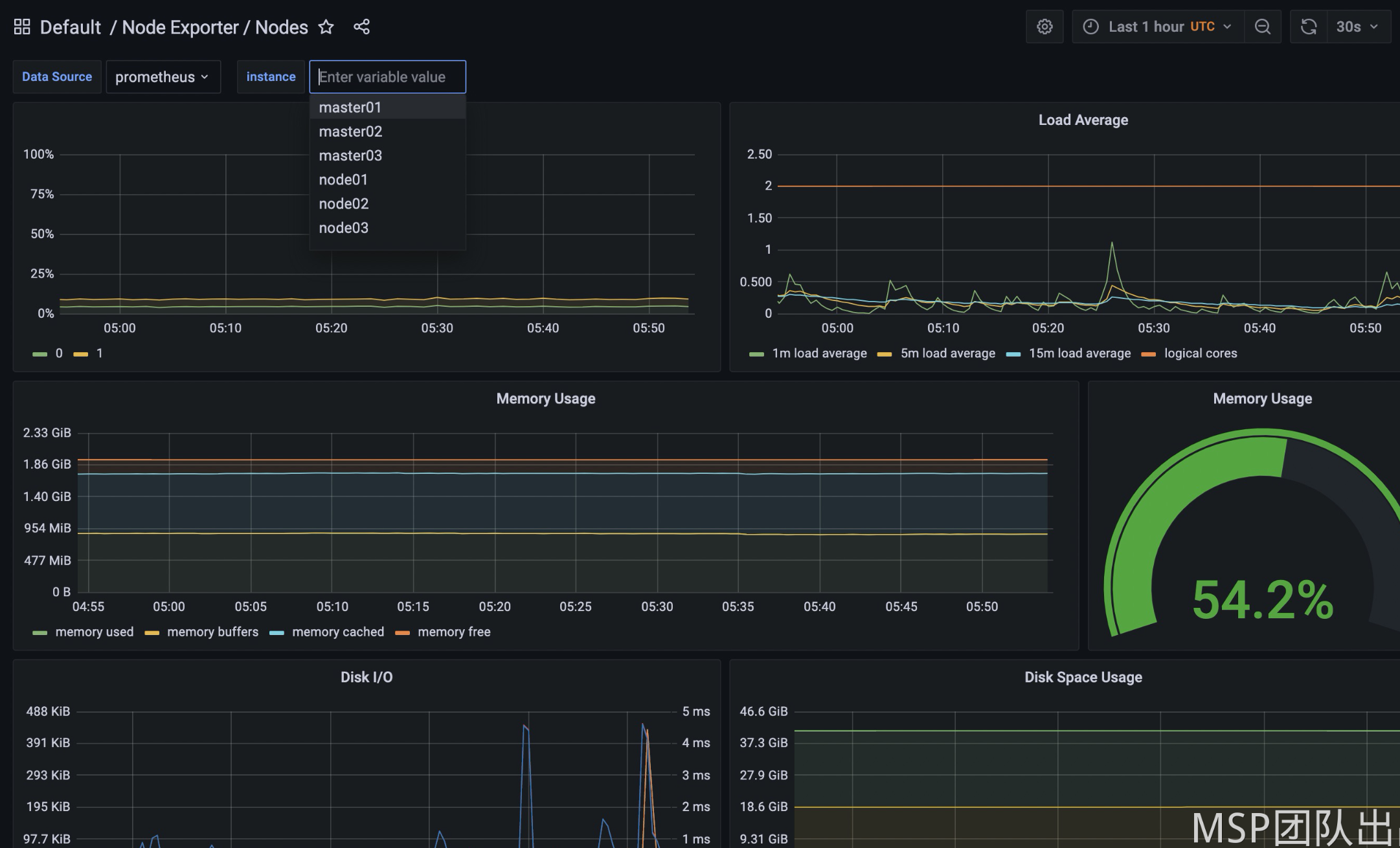
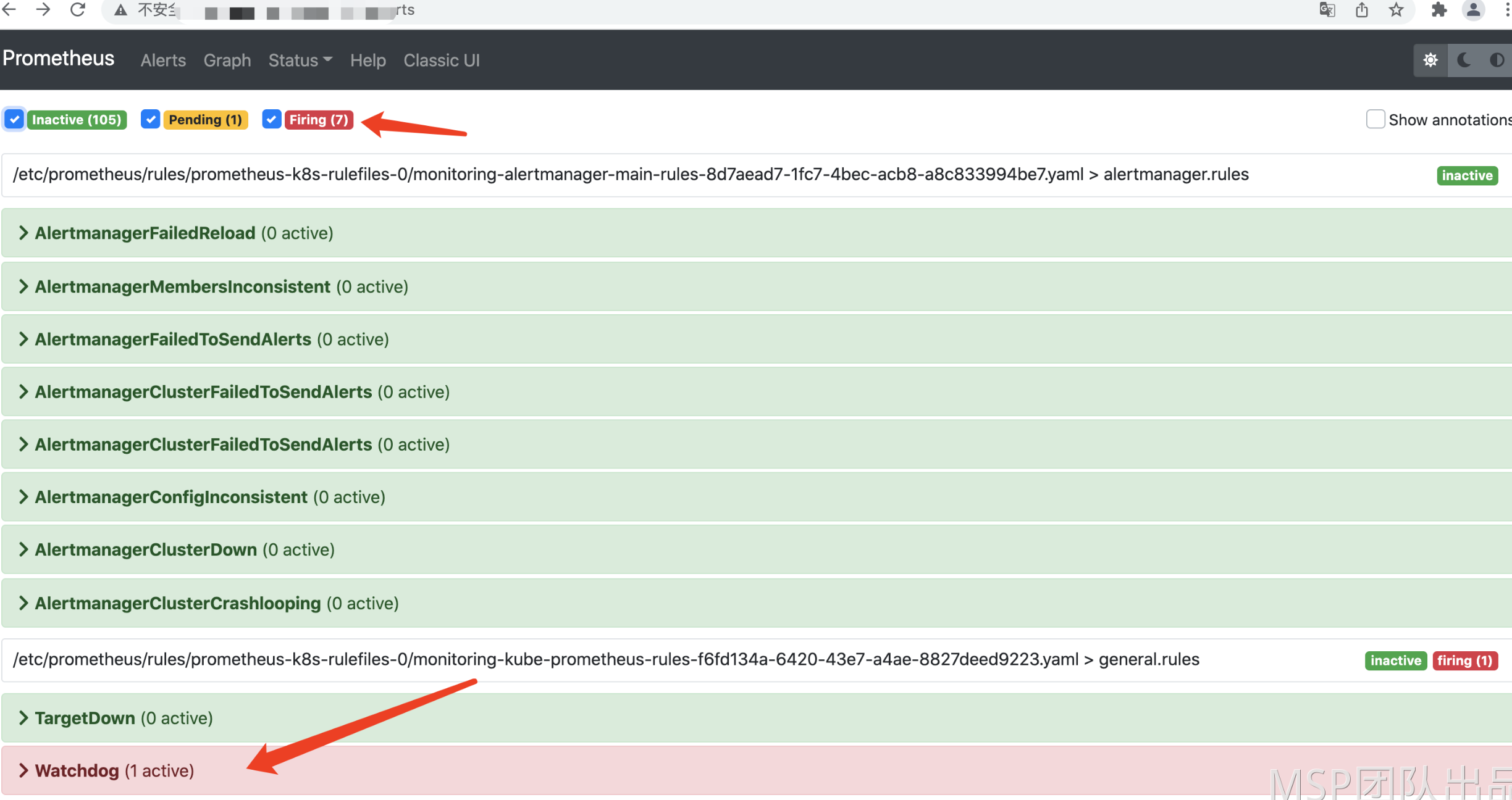
查看 Alertmanager 告警
查看AlertManager service资源,会发现当前为ClusterIP类型
[root@master01 manifests]# kubectl get svc -A | grep alertmanager-main monitoring alertmanager-main ClusterIP 10.254.30.198 <none> 9093/TCP,8080/TCP 6d17h
先临时修改为NodePort类型
kubectl edit svc -n monitoring alertmanager-main 将type: NodePort 修改为type: NodePort
再次查看AlertManager service资源
[root@master01 manifests]# kubectl get svc -n monitoring alertmanager-main NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main NodePort 10.254.30.198 <none> 9093:30407/TCP,8080:30024/TCP 6d17h
浏览器访问AlertManager ,查看AlertManager 的配置信息
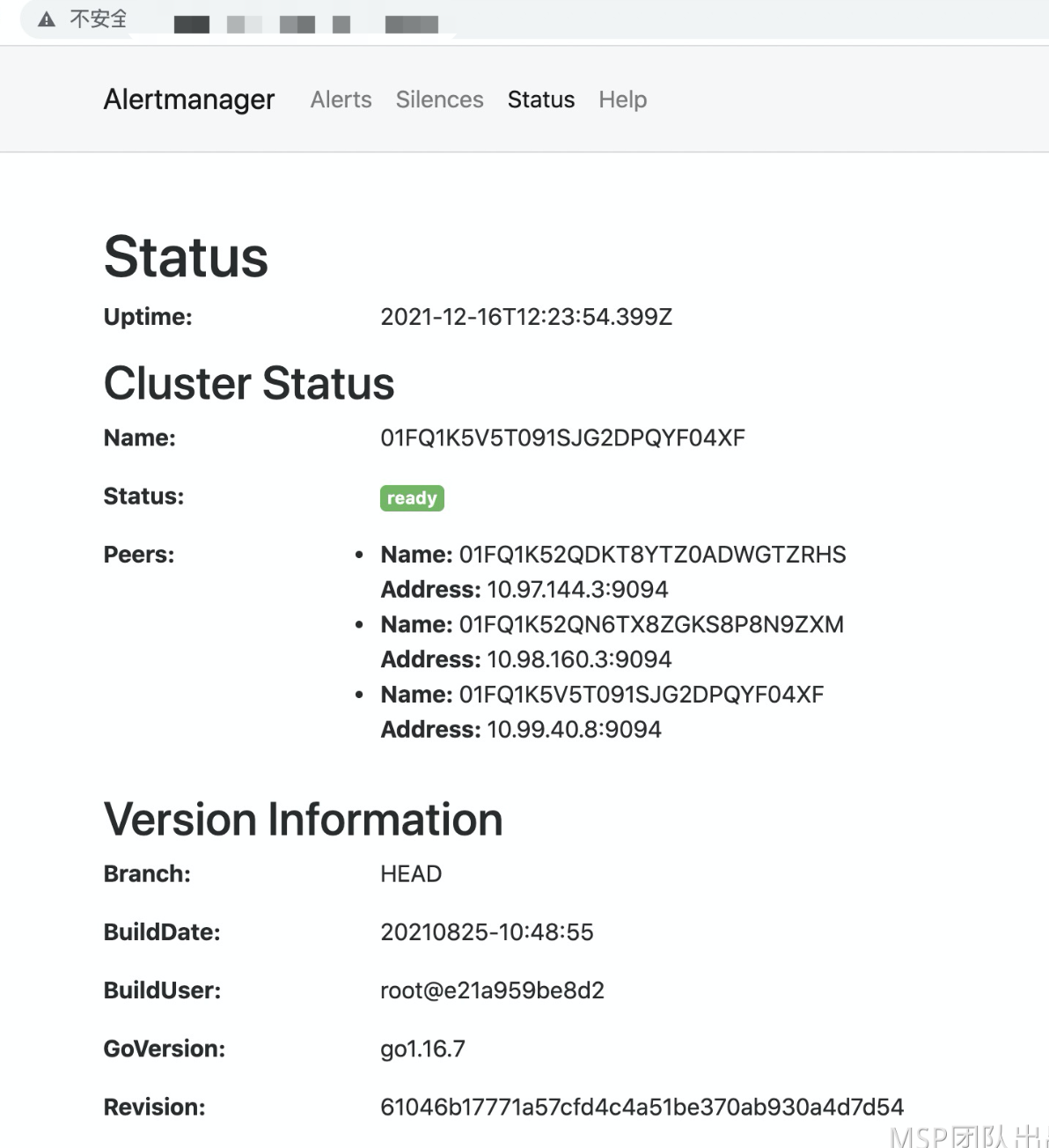
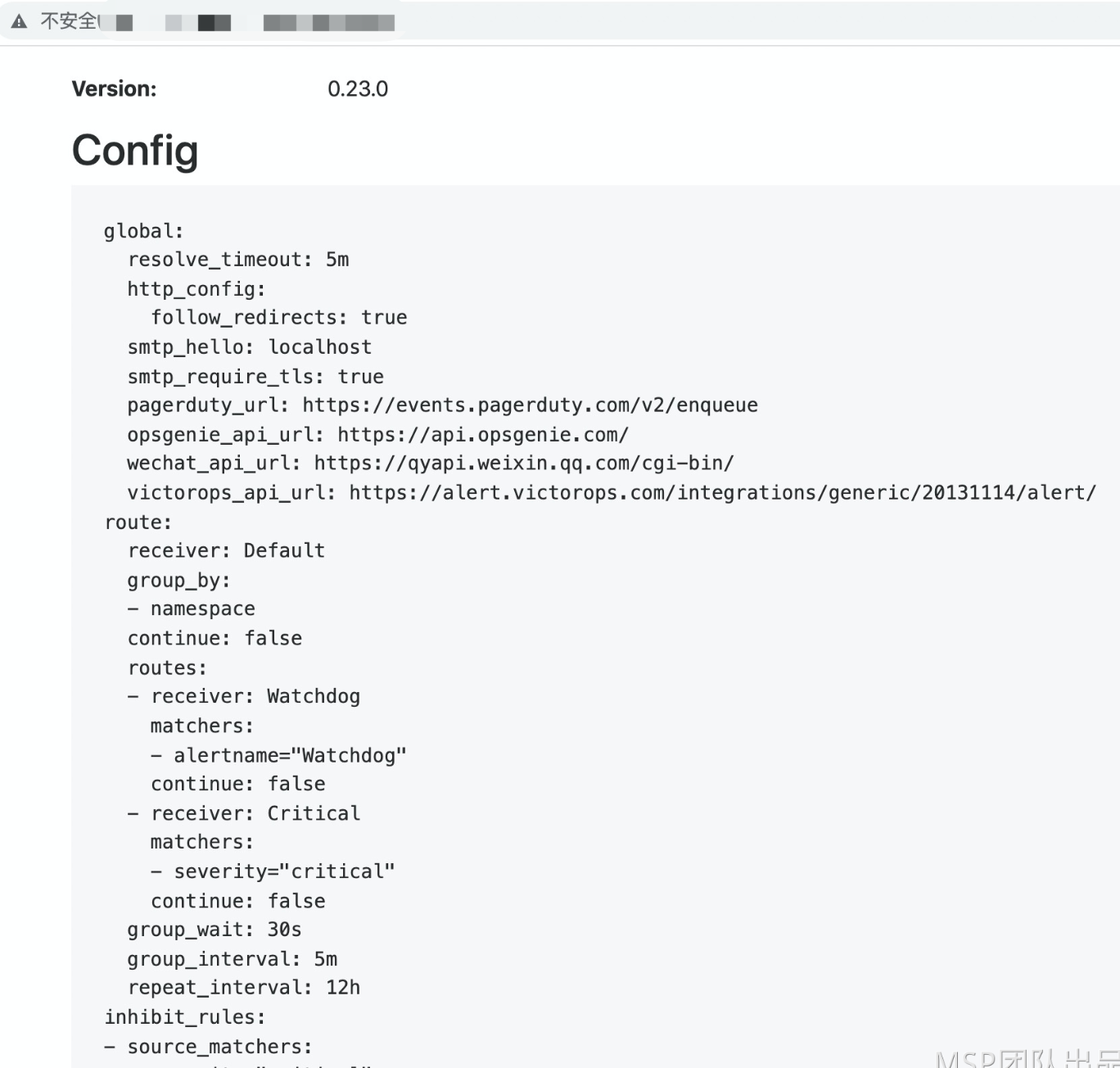
这些配置信息实际上是来自于我们之前在kube-prometheus/manifests目录下面创建的 alertmanager-secret.yaml 文件:
[root@master01 manifests]# cat alertmanager-secret.yaml apiVersion: v1 kind: Secret metadata: labels: app.kubernetes.io/component: alert-router app.kubernetes.io/instance: main app.kubernetes.io/name: alertmanager app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 0.23.0 name: alertmanager-main namespace: monitoring stringData: alertmanager.yaml: |- "global": "resolve_timeout": "5m" "inhibit_rules": #告警抑制规则 - "equal": - "namespace" - "alertname" "source_matchers": - "severity = critical" "target_matchers": - "severity =~ warning|info" - "equal": - "namespace" - "alertname" "source_matchers": - "severity = warning" "target_matchers": - "severity = info" "receivers": # 接收器指定发送人以及发送渠道 - "name": "Default" - "name": "Watchdog" - "name": "Critical" "route": "group_by": # 报警分组 - "namespace" "group_interval": "5m" # 如果组内内容不变化,合并为一条警报信息,5m后发送。 "group_wait": "30s" # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现 "receiver": "Default" "repeat_interval": "12h" # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。 "routes": - "matchers": #根据 标签进行匹配,走不同的接收规则 - "alertname = Watchdog" "receiver": "Watchdog" - "matchers": - "severity = critical" "receiver": "Critical" type: Opaque
但是目前告警只是在prometheus告警系统内可见