.gitlab-ci.yml 语法
介绍
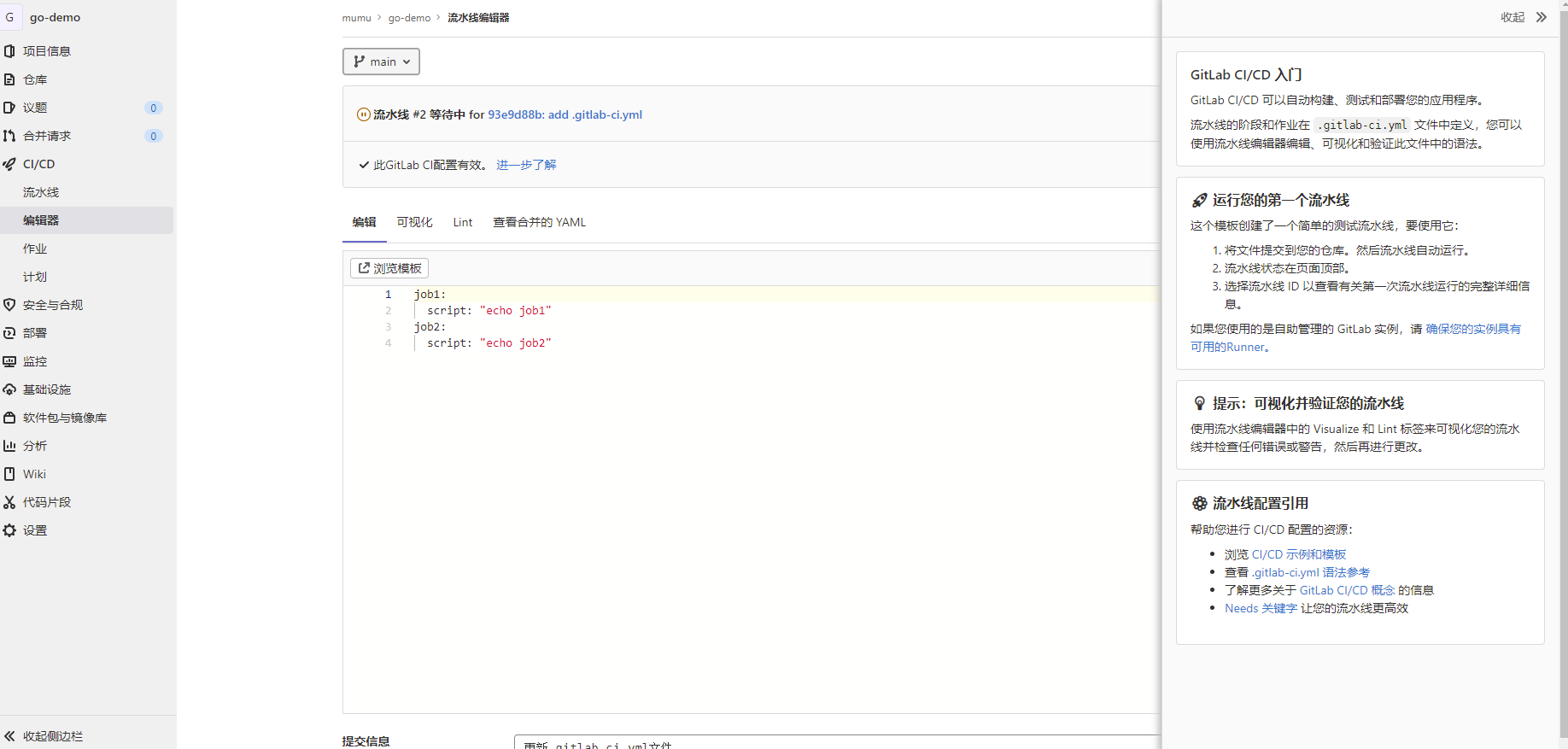
管道配置从作业(job)开始, 作业是 .gitlab-ci.yml 文件的最基本元素。
job是:
定义了约束,指出应在什么条件下执行
具有任意名称的顶级元素,并且必须至少包含 script 子句
不限制,可以定义多个
示例
job1: script: "echo job1" job2: script: "echo job2"
上面是两个简单的job,其中每个 job 都执行不同的命令,在 script 中,可以直接执行命令(/.configure;make;make install)或运行脚本(test.sh)。
验证.gitlab-ci.yml
GitLab CI 的每个实例都有一个称为 Lint 的嵌入式调试工具,该工具可以验证 .gitlab-ci.yml 文件的内容。您可以在 ci/lint 项目名称空间下找到它。
项目 -> CI/CD -> 编辑器
不可用的作业名称
image
services
stages
types
before_script
after_script
variables
cache
include
job配置参数
下表列出 job 了可用的参数
| 关键字 | 描述 |
|---|---|
| script | 由 Runner 执行的 Shell 脚本 |
| image | 使用的 docker 映像。也可用: image:name 和 image:entrypoint |
| services | 使用的 docker 服务映像。也可用:services:name,services:alias,services:entrypoint,和services:command |
| before_script | 重写作业之前执行的一组命令。 |
| after_script | 重写作业后执行的一组命令。 |
| stages | 定义管道中的阶段。 |
| stage | 定义作业阶段(默认:test)。 |
| only | 限制 job 的创建。也可用:only:refs, only:kubernetes, only:variables, and only:changes。 |
| except | 限制什么时候不创建 job。也可用:except:refs, except:kubernetes, except:variables, except:changes。 |
| rules | 用于评估和确定作业的选定属性以及是否创建该作业的条件列表。不可与only/except一起使用。 |
| tags | 用于选择 Runner 的 tags 列表。 |
| allow_failure | 允许作业失败。失败的工作不会影响提交状态。 |
| when | 什么时候开始工作。也可用:when:manual和when:delayed。 |
| environment | 作业部署到环境的名称。 也可用:environment:name,environment:url,environment:on_stop,environment:auto_stop_in和environment:action。 |
| cache | 在后续运行之间应缓存的文件列表。也可用:cache:paths,cache:key,cache:untracked,和cache:policy。 |
| artifacts | 成功时附加到作业的文件和目录列表。也可用:artifacts:paths,artifacts:expose_as,artifacts:name,artifacts:untracked,artifacts:when,artifacts:expire_in,artifacts:reports,artifacts:reports:junit,和artifacts:reports:cobertura。在GitLab 企业版,这些都是可供选择:artifacts:reports:codequality,artifacts:reports:sast,artifacts:reports:dependency_scanning,artifacts:reports:container_scanning,artifacts:reports:dast,artifacts:reports:license_management,artifacts:reports:performance和artifacts:reports:metrics。 |
| dependencies | 通过提供要从中获取工件的作业列表,限制将哪些工件传递给特定作业。 |
| coverage | 给定作业的代码覆盖率设置。 |
| retry | 发生故障时可以自动重试作业的时间和次数。 |
| timeout | 定义自定义作业级别的超时,该超时优先于项目范围的设置。 |
| parallel | 多少个作业实例应并行运行。 |
| trigger | 定义下游管道触发器。 |
| include | 允许此作业包括外部YAML文件。也可用:include:local,include:file,include:template,和include:remote。 |
| extends | 该作业将要继承的配置条目。 |
| pages | 上载作业结果以用于GitLab页面。 |
| variables | 在作业级别上定义作业变量。 |
| interruptible | 定义在通过新的运行使其冗余时是否可以取消作业。 |
| resource_group | 限制作业并发。 |
构建
为了组织我们的构建、测试和部署配置,我们需要知道如何将作业放入各个阶段。
查看默认的构建阶段
声明自定义构建阶段和顺序
指定使用特定的 Runner
默认的构建阶段
默认的构建阶段有三个阶段:
build
test
deploy
阶段的执行顺序按照上面的排序执行。所有未指定的阶段默认为 test 阶段
job1: stage: test script: echo "test" job2: stage: build script: echo "build" job3: stage: deploy script: echo "deploy" job4: script: echo "job4"
声明自定义阶段和顺序
每个阶段(stage)包含一个或多个 Jobs
阶段按其声明的顺序运行
任何作业失败都将阶段标记为失败
stages: - build - test - review - deploy job1: stage: test script: echo "test" job2: stage: build script: echo "build" job3: stage: deploy script: echo "deploy" job4: script: echo "job4" job5: stage: review script: echo "review"
使用特定的runner
如果Runner 有多个可用,会使用轮询的方式。如果需要使用指定的 Runner 运行,可以使用 tag 标签。
stages: - build - test - review - deploy job1: stage: test script: echo "test" tags: - aishangwei-group - docker job2: stage: build script: echo "build" ...