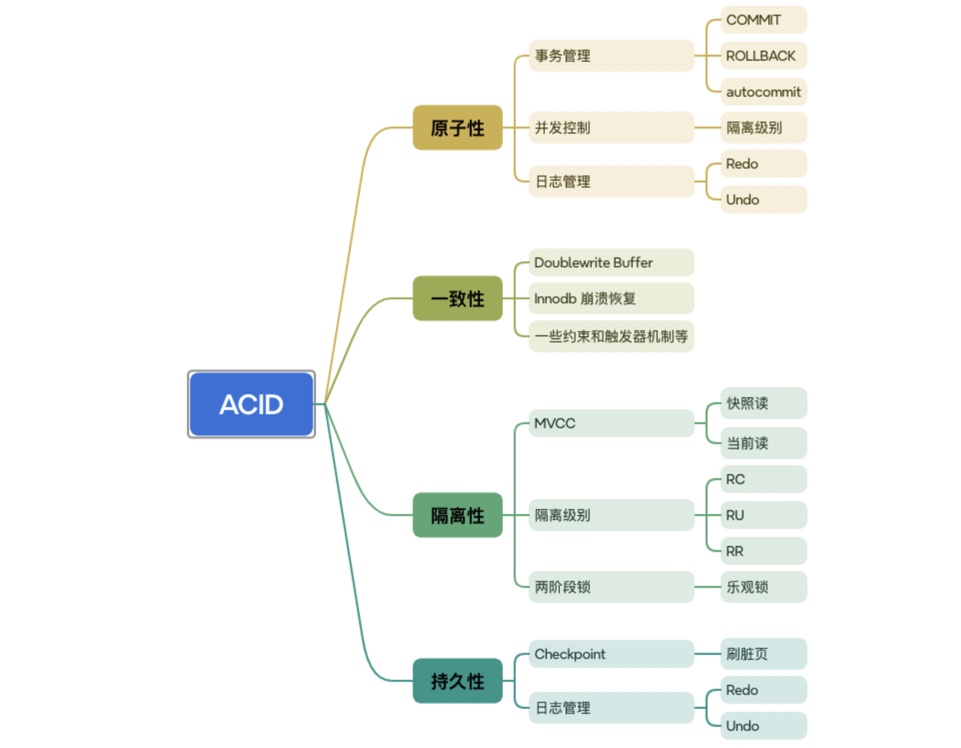
Hbase Rowkey设计方法
良好的 rowkey 设计,应当遵循以上四大原则,并且能让数据分散,从而避免热点问题。下面是几种常用的 rowkey 设计方法。
1 Salt 加盐
这里说的 Salt 加盐方法,是给每一个 rowkey 分配一个前缀,前缀使用一些随机字符,使得它和之前的 rowkey 开头不同,以使数据分散在多个不同的 Region 中,达到负载均衡、避免热点的目的。分配的前缀种类数量应该和需要分散到的不同 Region 的数量一致。下面举例说明这种方法的操作和优缺点。
在一个有 4 个 Region 的 HBase 表中(分区为:[ ,a)、[a,b)、[b,c)、[c, )),加盐前的 rowkey 为:abc001、abc002、abc003,此时,数据会默认分在 [a,b) 这个 Region 中。
现在,我们分别为这几个 rowkey 加上 a、b、c 前缀,加盐后的 rowkey 为:a-abc001、b-abc002、c-abc003,此时,数据就会分布在 3 个 Region 中。
理论上,通过 Salt 加盐处理后的数据的写操作吞吐量会是之前的 3 倍。而由于前缀是随机的,读这些数据时需要耗费更多的时间。所以,加盐的优点是增加了写操作的吞吐量,缺点是同时增加了读操作的开销。
2 Hash 散列或 Mod
使用 Hash 散列来替代随机 Salt 前缀,可以使同一行只用一个前缀,在分散整个集群负载的同时,可以使读操作也能够预测。确定性的 Hash 可以让客户端重构完整的 rowkey,使用 get 操作便能直接准确地获取某一行的数据。下面我们使用加盐中的例子来进一步说明。
将加盐例子中的原始 rowkey 经过 Hash 处理(此处我们采用 md5 散列算法取前 4 位作为前缀),结果如下:9bf0-abc001、7006-abc002、95e6-abc003.
如果以前 4 位的前缀作为不同分区的起止,则这几个 rowkey 的数据会分布在 3 个 Region 中,且读操作能比 Salt 更快速准确。在实际应用场景中,当数据量越来越大,这种设计会使得分区之间更加均衡。
如果 rowkey 是数字类型的,也可以考虑采用 Mod(取模)方法。
3 Reverse 反转
针对固定长度或者数字格式的 rowkey,可以反转后存储。这样就可以使得 rowkey 中经常改变(也是最没有意义)的部分放在最前面,从而生成有效的随机 rowkey。
以手机号码为例,手机号码的开头都是相对比较固定的,但其后几位都是没有规律的随机数字。因此,我们可以将手机号反转后的字符串作为 rowkey,这样就避免了较为固定的起始字符串(如 138、159、189)导致的热点问题。身份证号码也同样适用。
反转的缺点是牺牲了 rowkey 的有序性。
4 时间戳反转
时间戳反转实质上是属于反转方法的应用,只是这个反转较为常用,特单独进行讲解。
由于 HBase 中的 rowkey 是按照 ASCII 字典顺序由低到高排序,因此若使用递增的 rowkey,最新产生的数据会被放到旧数据的后面。因此,如果需要快速获取数据的最新记录,可以使用反转的时间戳作为 rowkey 的一部分。
具体实现方式是,用一个大的数(如 99999999)或者 Long 型的最大值(0x7FFFFFFFFFFFFFFF)减去时间戳,结果放到 rowkey 的后面作为其一部分。这样就可以调整数据的时间排序,将最新的数据放在前面,通过 scan 操作获取第一条记录即为最新的值。但这个方法严格上来说,并没有完全遵循散列原则。
举例来说,需要保存用户的操作记录,就可以使用时间戳反转的方法设计 rowkey:
[userID反转][Long.Max_Value - timestamp]
查询用户的所有操作记录:使用 scan 操作指定范围,STARTROW 为[userID反转][000000000000],ENDROW 为[userID反转][Long.Max_Value - timestamp].
查询用户某段时间的操作记录:使用 scan 操作指定范围,STARTROW 为[userID反转][Long.Max_Value - 起始时间],ENDROW 为[userID反转][Long.Max_Value - 结束时间].
rowkey 的设计除了掌握原理和方法外,还需要多加实践,有些小技巧是需要在实践中摸索和积累的。例如,在 rowkey 中使用|,~等 ASCII码较大的字符来避免排序混乱或人工干预排序等。
在 rowkey 设计完成之后,即可通过使用预分区的方法,来指定按设计好的 rowkey 进行预分区了。