MySQL运维实战之ProxySQL(9.1)ProxySQL介绍
mysql通过复制技术实现了数据库高层面的可用,但是对于应用来说,当后端MySQL发生高可用切换时,应该怎么处理?
我们考虑几种方案:
1、使用域名绑定。应用通过dns连接后端实例,当后端发生切换后,将dsn指向新的主库。
使用域名存在几个问题:dns缓存的问题。端口问题,如果主库备库的端口不一样,就无法直接通过dns解决。
2、在客户端解决。将组成mysql高可用集群的实例信息都配置到应用,应用检测当前主库。
这给应用开发带来额外的编码工作。
3、引入proxy,应用只访问proxy,proxy将应用请求转发给后端mysql。proxy的作用,和在web高可用架构中的负载均衡器作用类似。
本文介绍开源的proxysql。proxysql支持mysql传统主备复制架构、group replication架构。
proxysql的核心功能:
1、高可用
后端节点出现故障时,可自动屏蔽异常节点。
当后端数据库发生主备切换时,proxysql可自动识别
2、读写分离
根据用户SQL,将读的SQL分发到只读节点,降低主库压力。
3、sharding
通过灵活配置路由规则,可以实现数据库sharding。
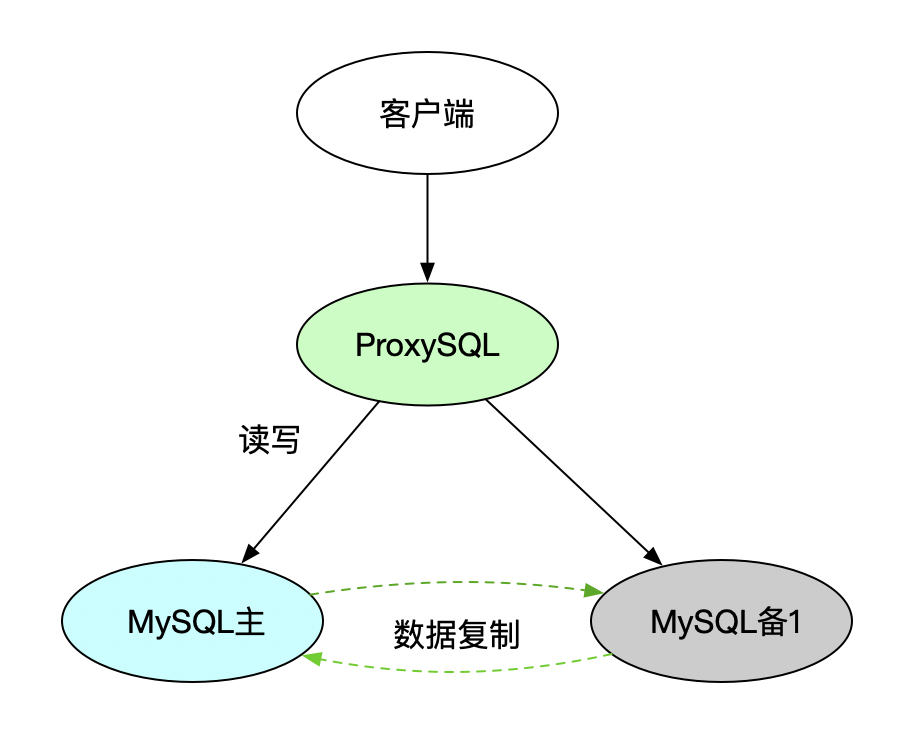
下图是一个简单的ProxySQL架构示意图:

引入proxysql后,客户端不需要直接连接后端mysql。proxysql本身支持mysql协议,对客户端而言,proxysql本身就是一台mysql。
使用proxysql的流程大致如下:
1、客户端连接到proxysql实例。proxysql和mysql协议完全兼容。
2、客户端发起SQL语句。
3、proxysql接收和解析SQL语句。根据语句内容和发起语句的会话的上下文,选择一台后端MySQL服务器,将SQL转发到后端执行。
4、后端SQL执行完成后,ProxySQL将后端返回的数据发送给客户端。
在这个架构下,客户端并不需要知道连接的是proxysql,对客户端而言,他连接的是一台标准的mysql服务器。在proxysql后端,可以是一个使用mysql复制技术搭建的集群,或者是一个group replication集群。如果后端mysql集群发生了主备切换,proxysql可以自动感知到,客户端不用做特殊处理,就能实现数据访问高可用。