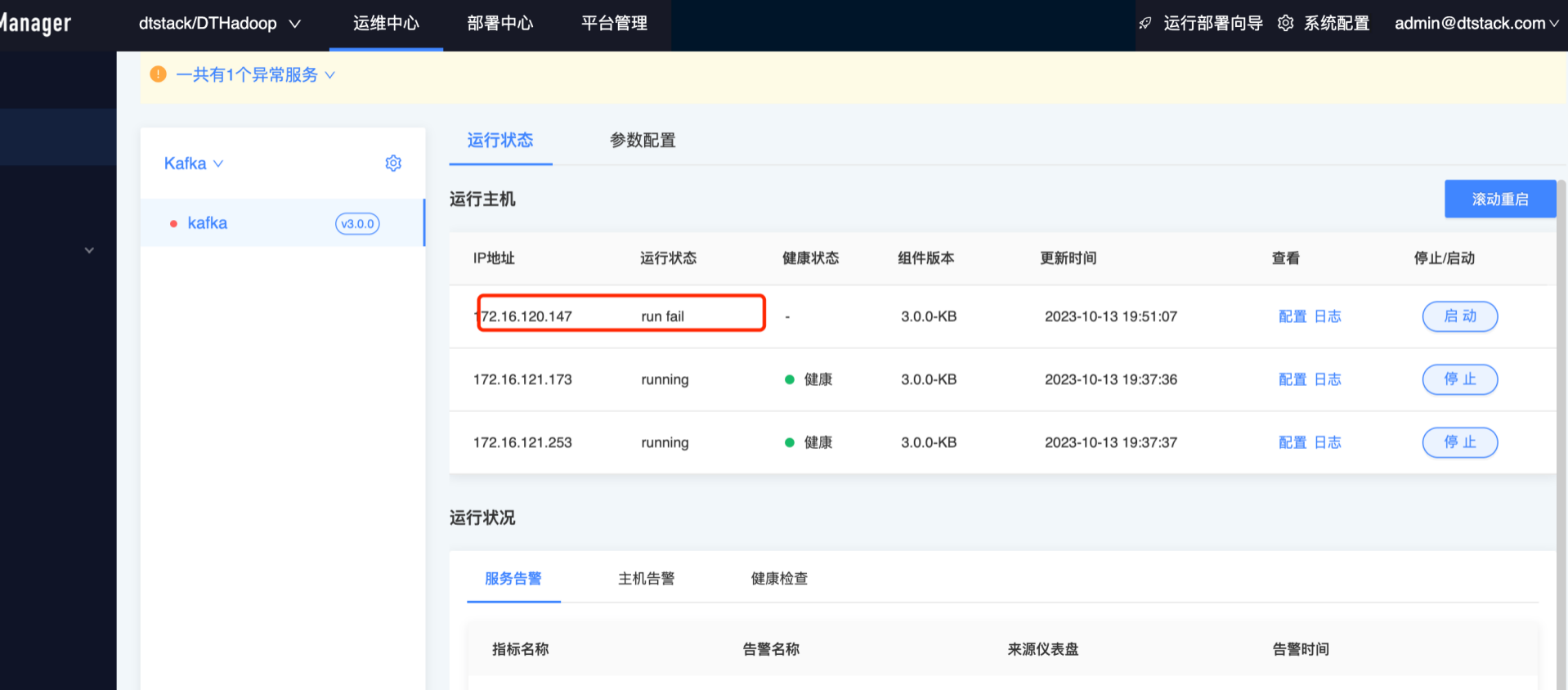
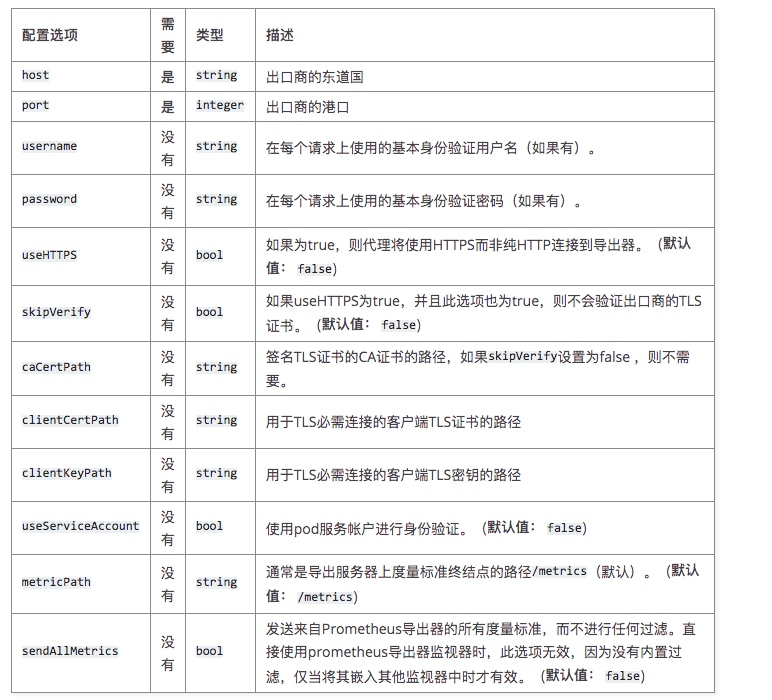
Spark调优方式
(1)资源参数调优
num-executors:设置Spark作业总共要用多少个Executor进程来执行
executor-memory:设置每个Executor进程的内存
executor-cores:设置每个Executor进程的CPU core数量
driver-memory:设置Driver进程的内存
spark.default.parallelism:设置每个stage的默认task数量
(2)开发调优
避免创建重复的RDD
尽可能复用同一个RDD
对多次使用的RDD进行持久化
尽量避免使用shuffle类算子
使用map-side预聚合的shuffle操作
使用高性能的算子
①使用reduceByKey/aggregateByKey替代groupByKey
②使用mapPartitions替代普通map
③使用foreachPartitions替代foreach
④使用filter之后进行coalesce操作
⑤使用repartitionAndSortWithinPartitions替代repartition与sort类操作
(3)广播大变量
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能。
(4)使用Kryo优化序列化性能
(5)优化数据结构
在可能以及合适的情况下,使用占用内存较少的数据结构,但是前提是要保证代码的可维护性。