SparkStreaming对接kafka消费模式区别
Sparkstreaming对接kafka使用的消费方式与常规的kafka消费方式完全不同,其中区别主要为消费者的管理方式不同。
Ø 常规消费模式
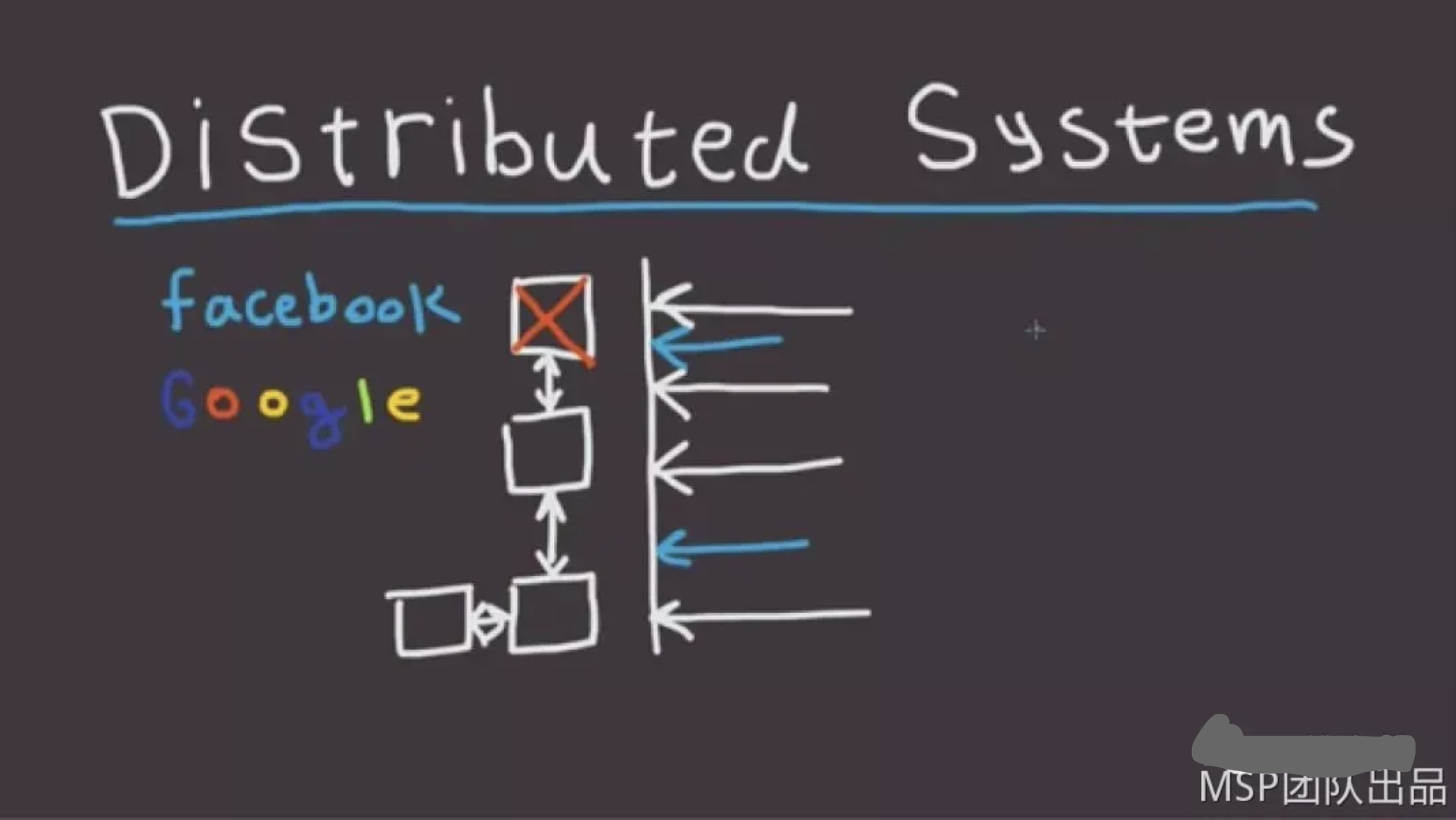
Kafka常规的消费模式以消费者组为消费单元,每个消费者组中有一个或者多个消费者并行消费。如下图,若消费者个数小于topic分区个数,则每个消费者至少对应一个或者多个topic的分区,并且每个消费者分别管理自己的offset。

通过消费者组查看命令查询结果如下:
./kafka-consumer-groups.sh --bootstrap-server kafkaip:port --describe --group DemoConsumer --command-config ../config/consumer.properties |
可以看到,每个不同的消费线程对应一个分区,每个不同的消费者根据offset提交方式(由enable.commit.offset)决定。
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testsparktopic 6 181196454 181209277 12823 consumer-1-b565f214-7520-43ea-kc90-aa7413nchd8 /192.168.x.5 consumer-1
testsparktopic 0 181356668 181374425 17757 consumer-1-b565f214-7520-43ea-mk88-kiu188790kak /192.168.x.5 consumer-1
testsparktopic 7 181239524 181257314 17790 consumer-1-b565f214-7520-43ea-51cb-lcjksui13ioop3 /192.168.x.5 consumer-1
testsparktopic 3 181239304 181259594 20290 consumer-1-b565f214-7520-43ea-3hjk -scasd9878789 /192.168.x.5 consumer-1
testsparktopic 4 181239259 181252050 12791 consumer-1-b565f214-7520-43ea-kh87-kihhdu876561 /192.168.x.5 consumer-1
testsparktopic 5 181239743 181252534 12791 consumer-1-b565f214-7520-43ea-09ij-lkdk1948jc82jd /192.168.x.5 consumer-1
testsparktopic 2 181458361 181471151 12790 consumer-1-b565f214-7520-43ea-4d5h-09dikc78dj19d /192.168.x.5 consumer-1
testsparktopic 1 180555802 180568625 12823 consumer-1-b565f214-7520-43ea-7u8s-opo398834kc1 /192.168.x.5 consumer-1
Ø SparkStreaming的消费模型
Sparkstreaming作为微批处理的实时流处理引擎,对kafka的数据获取方式有一些差别,在每个job里面运行了两组driver consumer和 executor consumer,driver端consumer负责分配和提交offset到初始化好的KafkaRDD当中去,KafkaRDD内部会根据分配到的每个topic的每个partition初始化一个CachedKafkaConsumer客户端通过assgin的方式订阅到topic拉取数据(assgin模式:精确获取到每个分区中要消费的offset值的范围,并且消费)。如下图

如果在sparkStreaming中设置了enable.commit.offset为true,也可以从后台看到driver consumer的提交信息。如下
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testsparktopic 6 181196454 181209277 12823 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 0 181356668 181374425 17757 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 7 181239524 181257314 17790 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 3 181239304 181259594 20290 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 4 181239259 181252050 12791 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 5 181239743 181252534 12791 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 2 181458361 181471151 12790 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
testsparktopic 1 180555802 180568625 12823 consumer-1-b565f214-7520-43ea-a695-cc94a4ccd47c /192.168.184.5 consumer-1
由于只有driver consumer提交offset,因此这里的消费线程只有一个。
与sparkstreaming各个模块的对应关系如下,每个sparkjob中会启动一个driver,每个driver会对应多个excutor中可以启动多个task,通常情况下excutor consumer与task应该是一一对应的。