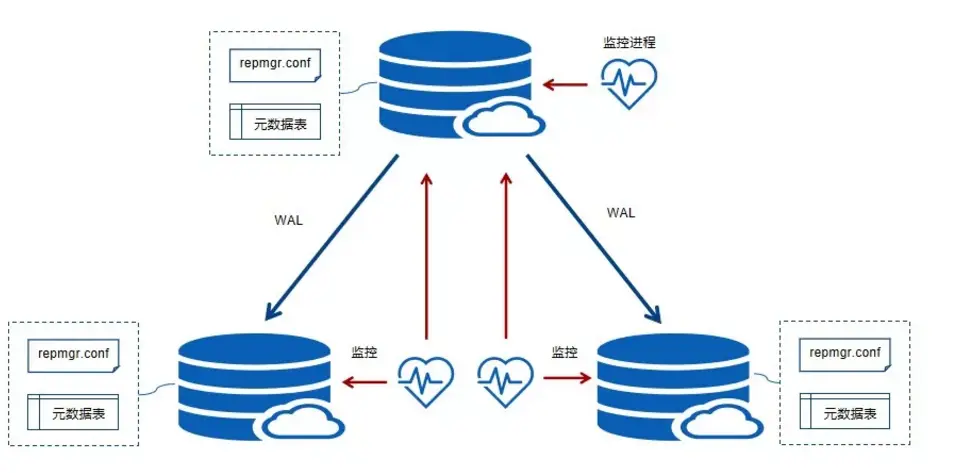
REPMGR-PG高可用搭建(一)
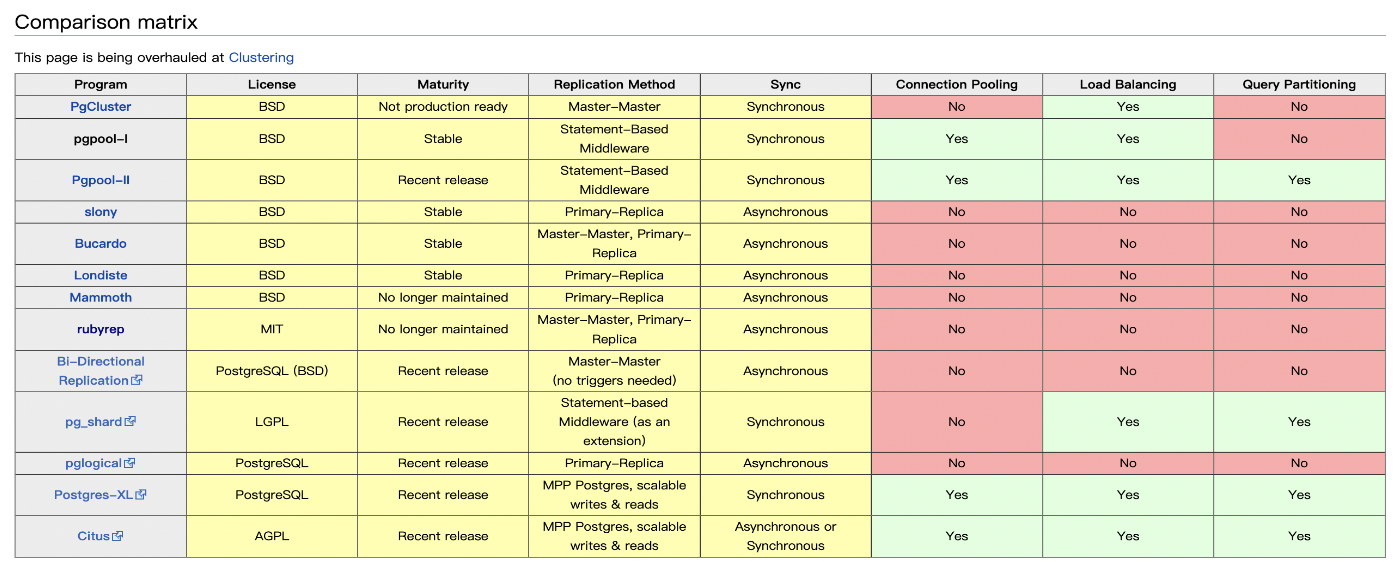
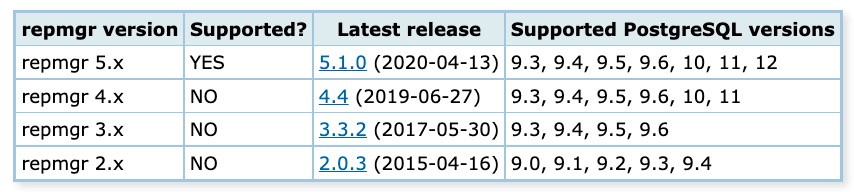
PG高可用对比
数据库复制的术语和定义
这些术语和定义应该有助于讨论复制。在与其他Postgres开发人员进行了大量讨论之后,我编译了它们,但是这些定义应该是普遍可用的,并且也应该适用于其他RDBMS。
复制
对于数据库系统来说,复制是共享事务数据以确保冗余数据库节点之间的一致性的过程。
这提高了容错性,从而提高了整个系统的可靠性。
数据库的复制系统也可以称为分布式数据库,特别是在与下面描述的其他优秀特性结合使用时。
我热切的倾向于只把多主系统算作分布式数据库,因为所有其他系统都会损害ACID原则,并且对应用程序不透明。
负载平衡
复制通常与负载平衡相结合,以提高读取性能。
一些复制解决方案有一个集成了底层系统的负载平衡器。其他复制方案依赖于操作系统或第三方负载平衡器。
复制的方法
数据库可以通过许多不同的方式保持一致性。
一种非常常见和简单的方法是基于语句的复制,其中SQL语句分布在节点之间。非确定性函数,如now()或random(),会给该方法带来一些问题。
另一种非常常见的方法是日志传送。
不幸的是,数据库系统的日志通常不是用于复制的交换格式,因此很难仅对数据库的一部分进行复制。因此,一些复制解决方案有自己的二进制格式,专门为复制而设计。
差异
就网络延迟而言,在多个节点之间保持数据一致是非常昂贵的。
因此,许多系统试图通过允许节点稍微偏离来避免网络延迟,这意味着它们允许提交冲突的事务。
要恢复到一个连贯一致的数据库,需要自动或手动解决这些冲突。
这种冲突违反了数据库系统的ACID属性,因此应用程序需要意识到这一点。
同步复制与异步复制
根据维基百科对同步的定义,数据库复制被认为是数据同步,而不是进程同步。
但是,在数据库系统内部必须同步锁或至少同步事务,这显然被认为是进程同步。
在数据库复制上下文中,同步复制最常见的定义是,一旦确认提交事务,集群的所有节点也必须提交该事务。
在延迟和要发送的消息数量方面,这是非常昂贵的,但它可以防止差异。
在异步复制系统中,其他节点可以在稍后的任何时间点应用事务数据,因此节点可能提供不同的、甚至可能冲突的数据库快照。
急切(Eager)复制与惰性(Lazy)复制
在关于数据库复制的文献中,术语"急切(Eager)"和"惰性(Lazy)"更常用。
有时是同步或异步复制的同义词。
其他时候,有一个很好的区别:不是声明所有节点都需要同步处理事务,而是声明节点或副本最终保持一致就足够了。
这意味着事务必须以相同的顺序应用,但不一定是同步的。
根据这个定义,渴望复制介于同步和异步之间:它允许节点落后于其他节点,同时仍然防止差异。
考虑这种区别的另一种方式是,急切系统必须在确认提交之前复制事务数据,而懒惰系统在提交之后的某个时间复制该数据,因此可能会产生冲突。
惰性复制始终是异步的,并且不避免差异。
由于这个微小但重要的区别,我更喜欢术语"惰性(Lazy)"而不是异步
无论如何,交换数据以检测和解决冲突的过程称为和解
调和的频率是在允许的延迟时间和调和的负载之间的权衡。
同样重要的是要知道,懒惰系统可以通过更频繁地协调来减少分歧的可能性,但分歧的可能性不能完全消除(否则系统将是渴望的)。
分布式查询
分布式查询允许单个查询使用多个服务器。
这提高了长时间运行的只读事务的性能。
简短的查询最好由单个节点来处理。
Postgres文档提到了“多服务器并行查询执行”。
数据分区
一个常见的区别是垂直分区和水平分区。
垂直分区将分成列更少的多个表,这与规范化过程非常相似。
当进行水平分区时,数据库系统将不同的行存储在多个不同的表中。
在多主系统中,这两种方法都可以用于跨多个节点拆分数据,以便每个节点只保存完整数据库的一部分。
这显然降低了可靠性,因为存储相同元组的节点更少。
并且它需要某种分布式查询,以便能够访问事务所需的所有数据。
但它确实提高了集群的总容量,并减少了写事务的总负载。
Shared-disk vs. Shared-nothing Clusters(共享磁盘vs.无共享集群)
共享磁盘集群描述了一堆节点,它们共享一个公共磁盘子系统,但在其他方面是独立的硬件。虽然这个术语有道理,但“无共享”常常让人感到困惑。这意味着集群的节点不共享任何东西,甚至不共享磁盘。当然,这两种类型通常是通过某种类型的分组交换网络连接起来的。无共享集群主要由商用硬件组成,而共享磁盘集群通常使用专用且昂贵的存储系统。
共享磁盘系统可以为具有故障转移功能的单主复制解决方案提供良好的基础。在无共享环境中使用集群文件系统是一种廉价的替代方案。
一个常见的误解是,共享磁盘集群允许比无共享磁盘集群更快的多主复制系统。理由是,需要传输的数据更少。但这不是问题所在,因为重要的不是网络吞吐量,而是延迟。换句话说:使用CPU、内存和网络进行冲突检测比使用CPU、内存和共享磁盘更快。
Clustering(聚集)
虽然集群是一个非常流行的术语,但对于数据库系统来说,它没有一个明确定义的含义。
有很多不同的技术,比如复制、负载平衡、分布式查询等等。被称为聚类。
Grids(网格)
关于数据库复制,同样适用于"grids",只是增强了。在我看来,这是一个简单的营销术语,IMO.
详见:https://postgres-r.org/documentation/terms
PG高可用方案对比