Doris性能测试
1.性能测试
(1)环境信息
硬件环境

软件环境
l Doris 部署 3BE 3FE;
l 内核版本:Linux version 5.5.0-96-generic
l 操作系统版本:CentOS Linux release 7.6.1810 (Core)
l Doris 软件版本: Apache Doris 2.0.0
l JDK:java version "1.8.0_311"
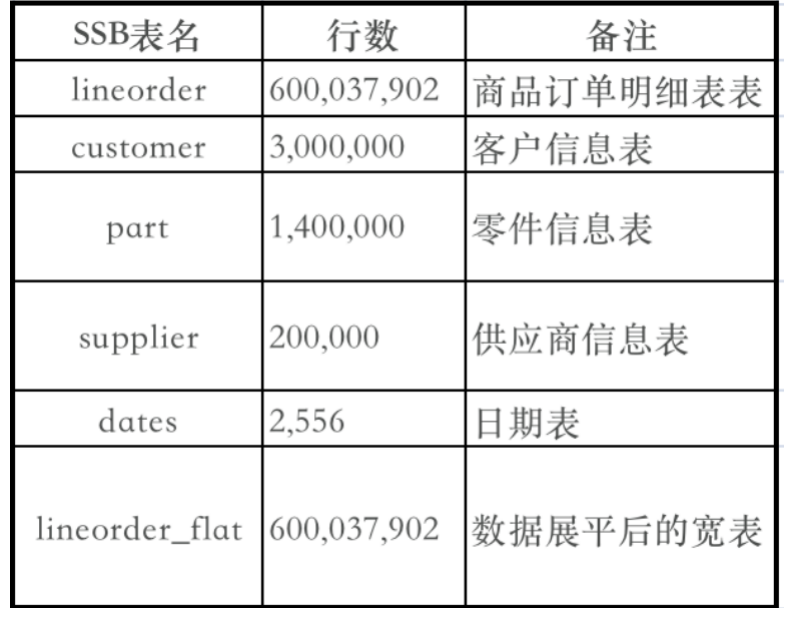
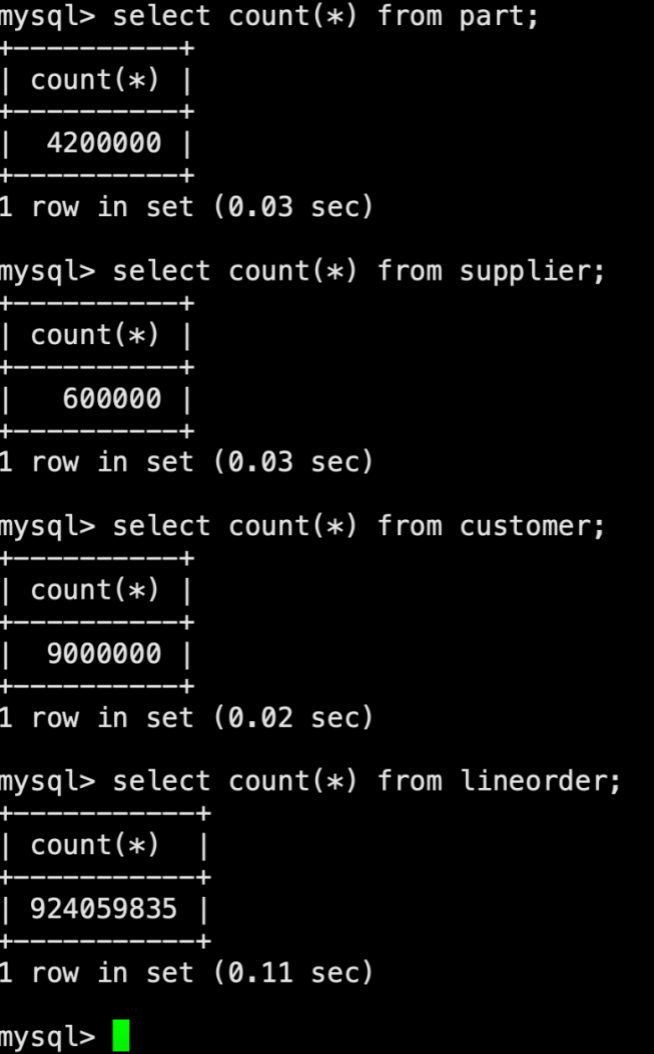
测试数据量
(2)数据准备
步骤1. SSB 数据生成工具前准备
复制如下链接中的脚本内容并执行
https://github.com/apache/doris/blob/master/tools/ssb-tools/bin/build-ssb-dbgen.sh
sh build-ssb-dbgen.sh
步骤2. 生成 SSB 测试集
复制如下链接中的脚本内容并执行
https://github.com/apache/doris/blob/master/tools/ssb-tools/bin/gen-ssb-data.sh
sh gen-ssb-data.sh -s 100 -c 100
说明:-s 100 表示测试集大小系数为 100,-c 100 表示并发100个线程生成 lineorder 表的数据。-c 参数也决定了最终 lineorder 表的文件数量。参数越大,文件数越多,每个文件越小。
步骤3. 建表
在主FE节点用mysql客户端执行如下两个链接中的sql语句
https://github.com/apache/doris/blob/master/tools/ssb-tools/ddl/create-ssb-tables.sql
https://github.com/apache/doris/blob/master/tools/ssb-tools/ddl/create-ssb-flat-table.sql
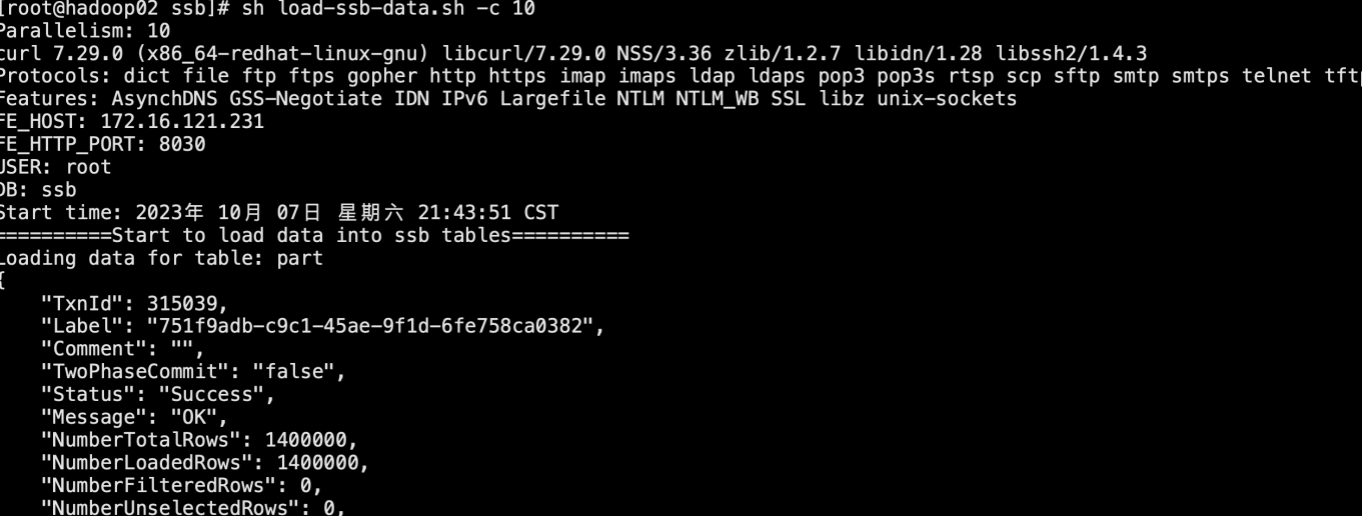
步骤4. 导入数据
在ssb目录的上级目录下新建conf目录并编辑doris-cluster.conf文件
内容如下:
export FE_HTTP_PORT="8030"
export FE_QUERY_PORT="9030"
export USER="root"
export PASSWORD=' '
export DB="ssb"
接着复制如下链接中的脚本内容并执行
https://github.com/apache/doris/blob/master/tools/ssb-tools/bin/load-ssb-data.sh
-c 5 表示启动 10 个并发线程导入(默认为 5)。在单 BE 节点情况下,由 sh gen-ssb-data.sh -s 100 -c 100 生成的 lineorder 数据,同时会在最后生成ssb-flat表的数据,如果开启更多线程,可以加快导入速度,但会增加额外的内存开销。
(3)测试
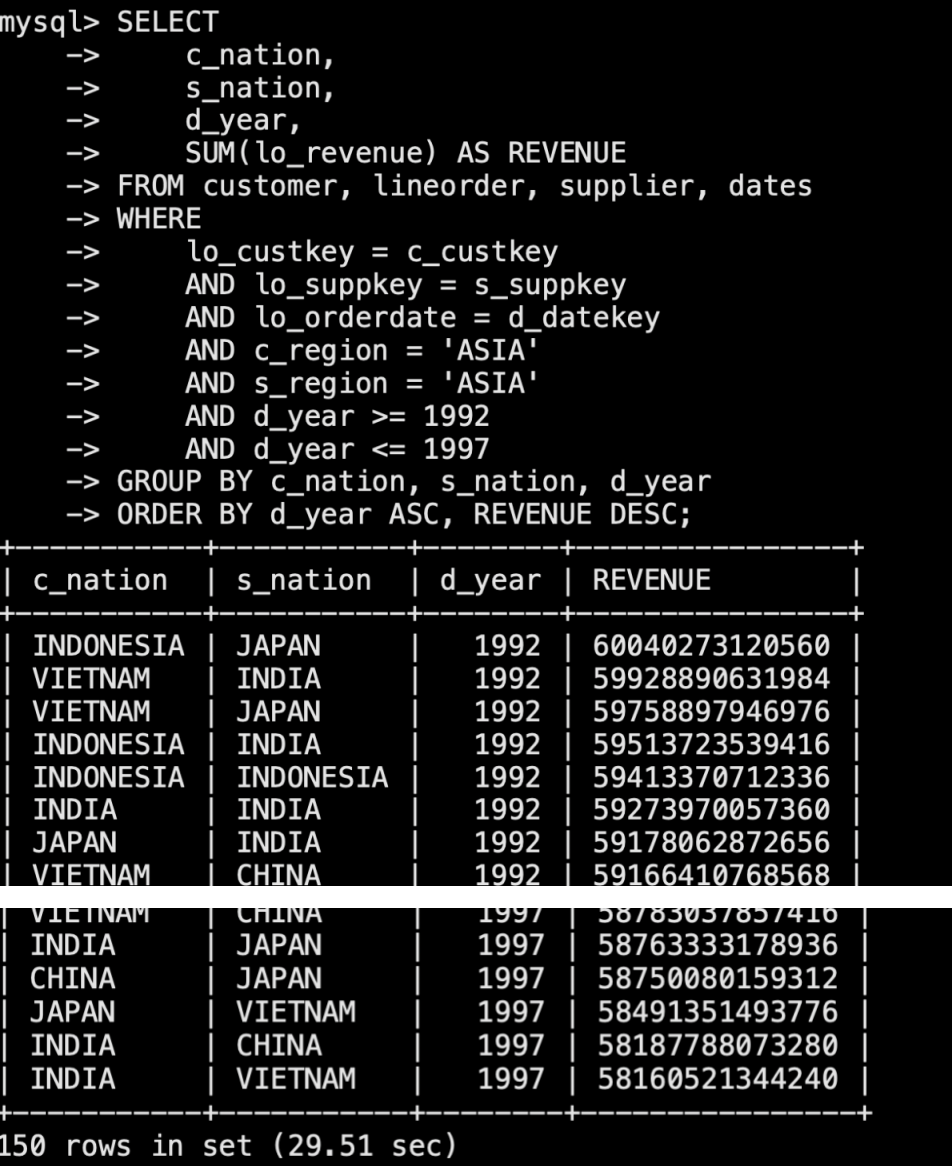
标准 SSB 查询语句结果如下:
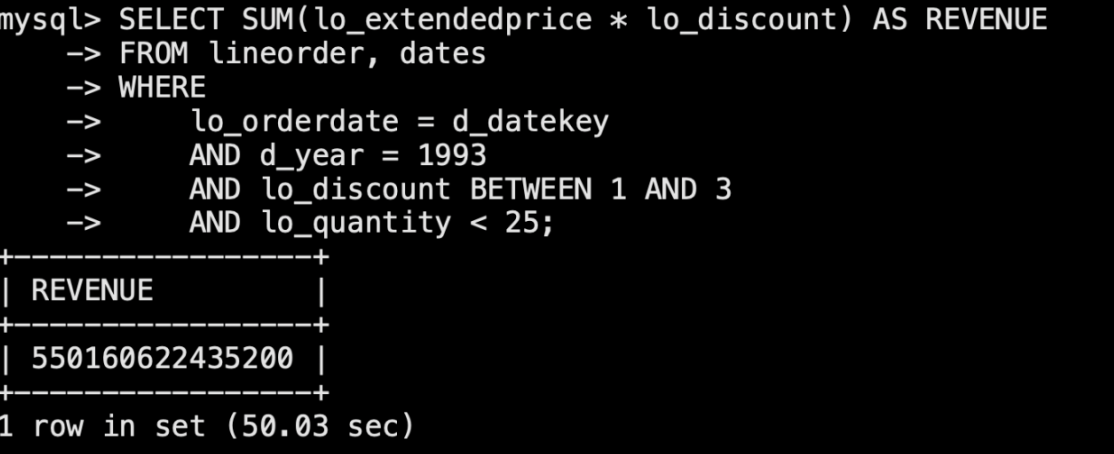
sql1:
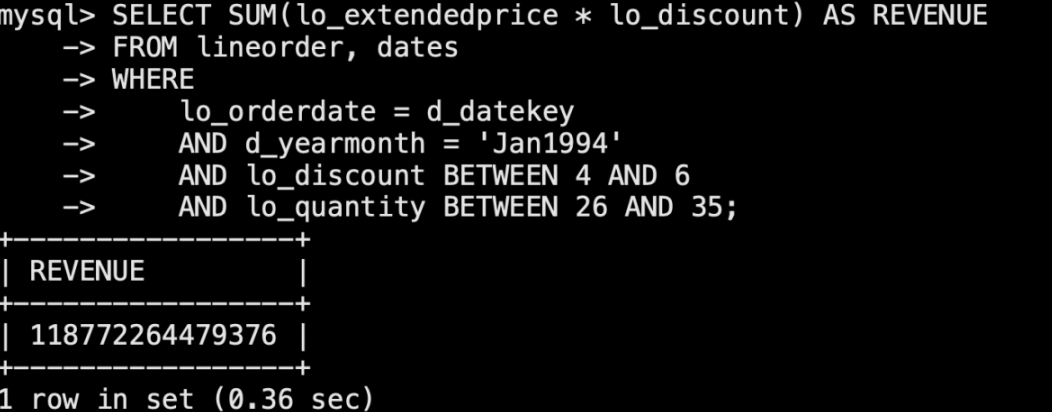
sql2:
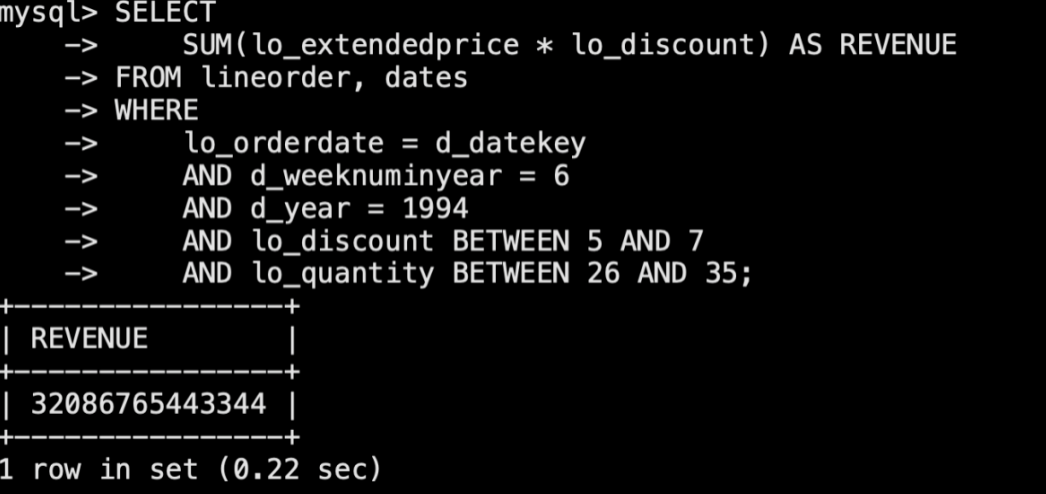
sql3:
sql4:
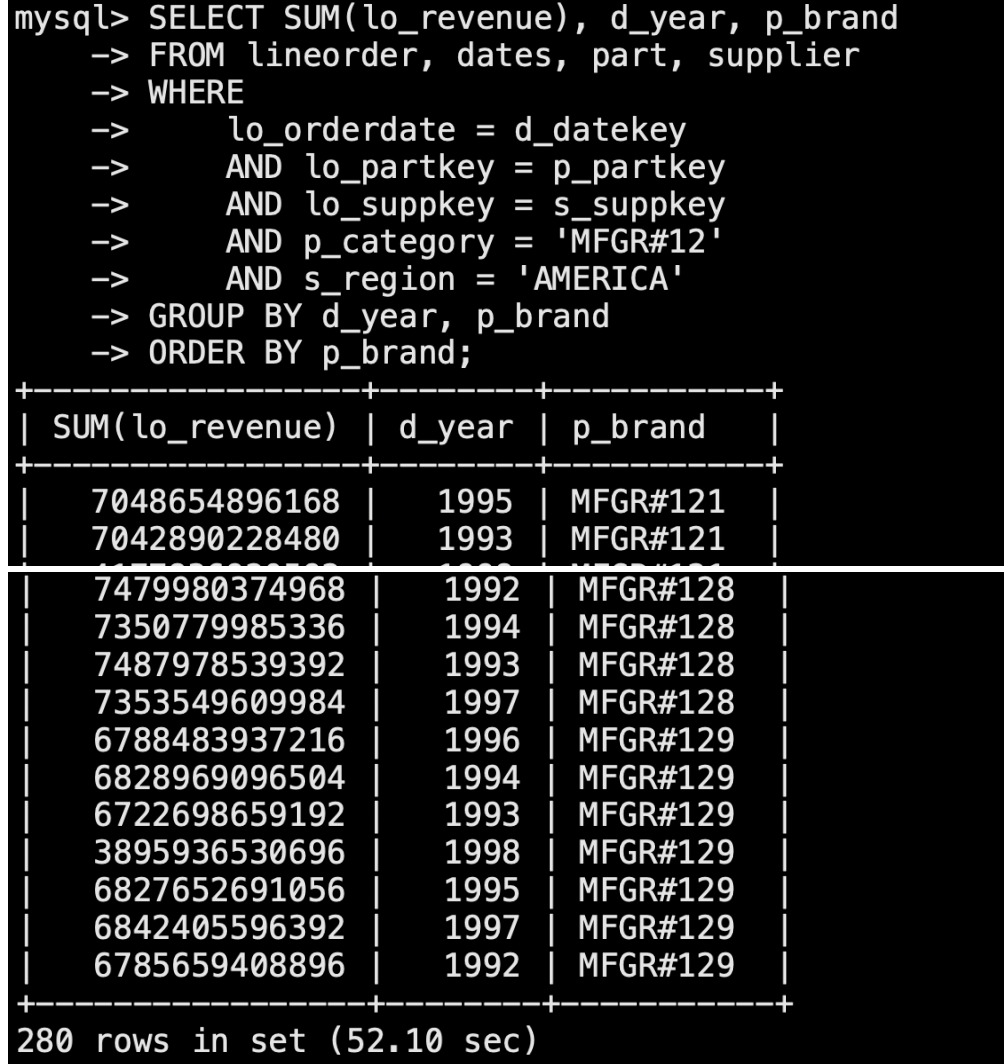
sql5:
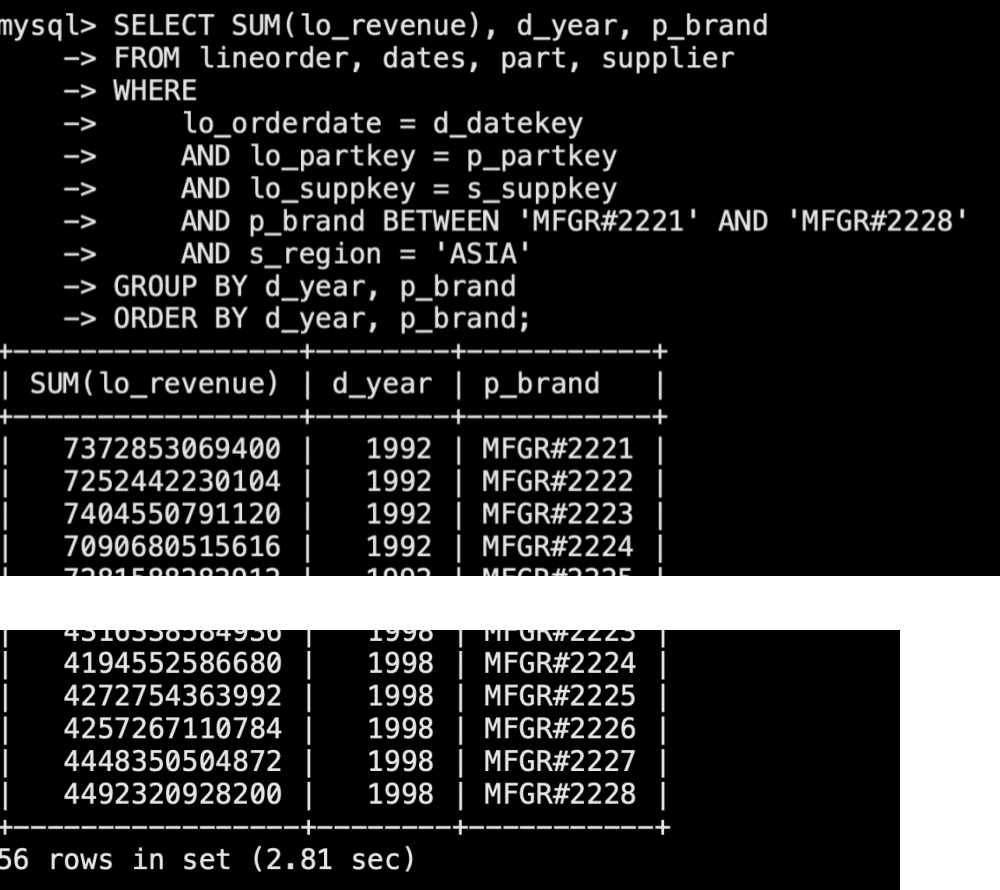
sql6: