MySQL性能优化(一)索引缺失引起的全表扫描
索引缺失是引起数据库性能问题的第一大原因。
一个例子
这是一个非常简单的SQL,
SELECT * FROM template WHERE templet_id = 2 AND status = 1
执行计划
我们来看一下这个SQL的执行计划
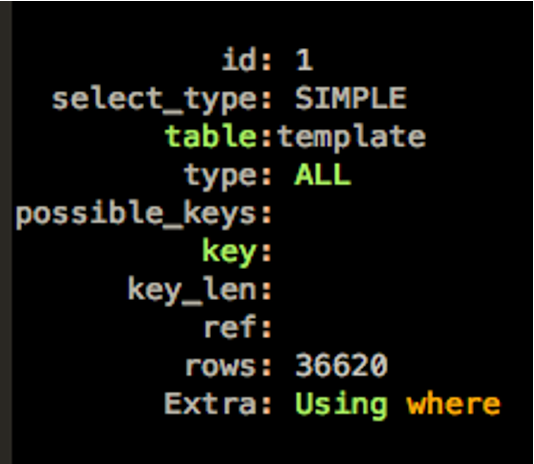
这是一个简单的执行计划,我们需要关注的信息主要包括:
table: 访问的表,这里是template表
type: ALL,表示全表扫描
possible_keys: 该查询可选的索引。这里没有任何索引可以使用
key: 使用的索引。这里没有使用索引
key_len: 使用到的索引长度。
rows: 预估需要访问的数据。
从这里的执行计划可以得到的信息:该查询每次执行都需要扫描3.6万行数据,没有任何索引可以使用。
优化
对于这种场景,我们可以给过滤性高的条件建立索引
alter table template add key idx_templateid_status(templet_id, status);
这里的关键是过滤性,如果过滤性不高,那么建了索引也不一定能提升性能。
过滤性
过滤性可以理解为使用给定where条件过滤出来的记录数占总记录数的比例,这个比例越小,则使用索引的效果越好。
可以使用如下的SQL来分析一个字段或多个字段的过滤性:
select 1 / count(distinct c) from tab;
字段的唯一值越多,则上述SQL的查询值约小,过滤性越高。
数据倾斜
在有些业务场景下,存在数据倾斜,也就是字段有的值的数据量特别大。可以通过如下SQL来判断是否存在数据分布不均匀的问题。
Select col, count(*) From tab Group by col order by count(*) desc limit 10
对于存在数据倾斜的场景,则索引是否有效,取决于where条件中的值的过滤性,过滤性高的就可以通过索引来提升查询效率。
组合索引
在本案例中,我们建立了一个组合索引:
idx_templateid_status(templet_id, status)
组合索引中字段的顺序很重要,需要根据业务的查询场景来设计。关于组合索引中字段顺序的问题,我们后续再来详细分析。