RabbitMQ 集群部署
1. 两种模式
说到集群,小伙伴们可能第一个问题是,如果我有一个 RabbitMQ 集群,那么是不是我的消息集群中的每一个实例都保存一份呢?
这其实就涉及到 RabbitMQ 集群的两种模式:
1)普通集群
2)镜像集群
1.1 普通集群
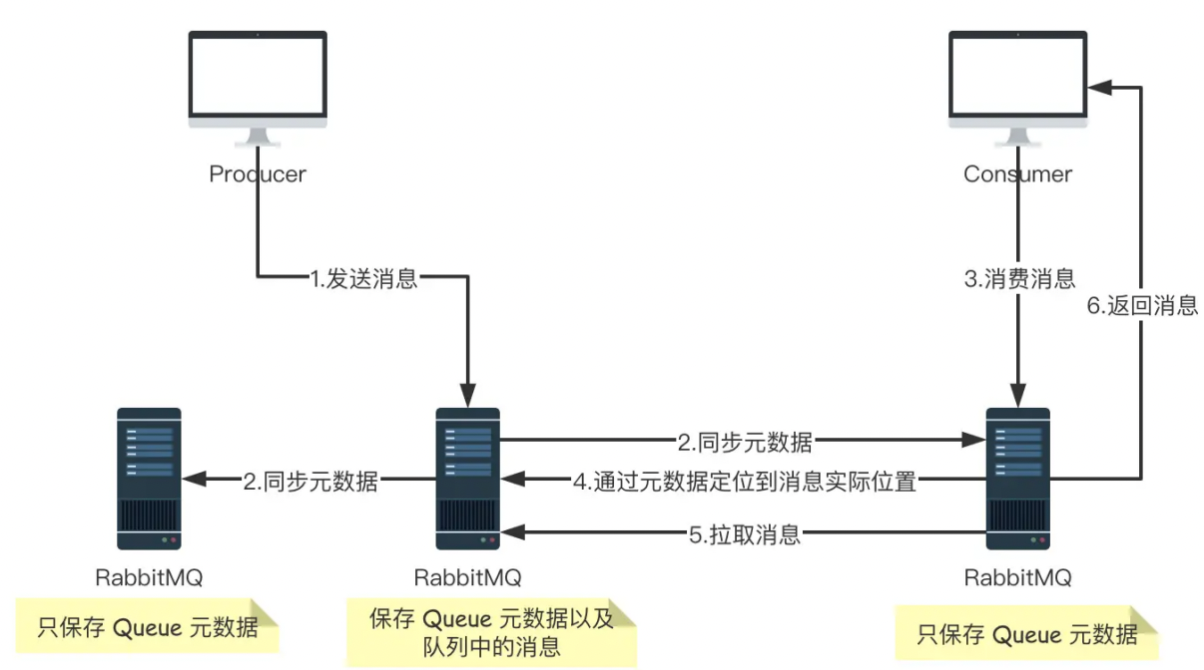
普通集群模式,就是将 RabbitMQ 部署到多台服务器上,每个服务器启动一个 RabbitMQ 实例,多个实例之间进行消息通信。
此时我们创建的队列 Queue,它的元数据(主要就是 Queue 的一些配置信息)会在所有的 RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
当我们消费消息的时候,如果连接到了另外一个实例,那么那个实例会通过元数据定位到 Queue 所在的位置,然后访问 Queue 所在的实例,拉取数据过来发送给消费者。
这种集群可以提高 RabbitMQ 的消息吞吐能力,但是无法保证高可用,因为一旦一个 RabbitMQ 实例挂了,消息就没法访问了,如果消息队列做了持久化,那么等 RabbitMQ 实例恢复后,就可以继续访问了;如果消息队列没做持久化,那么消息就丢了。
大致的流程图如下图:
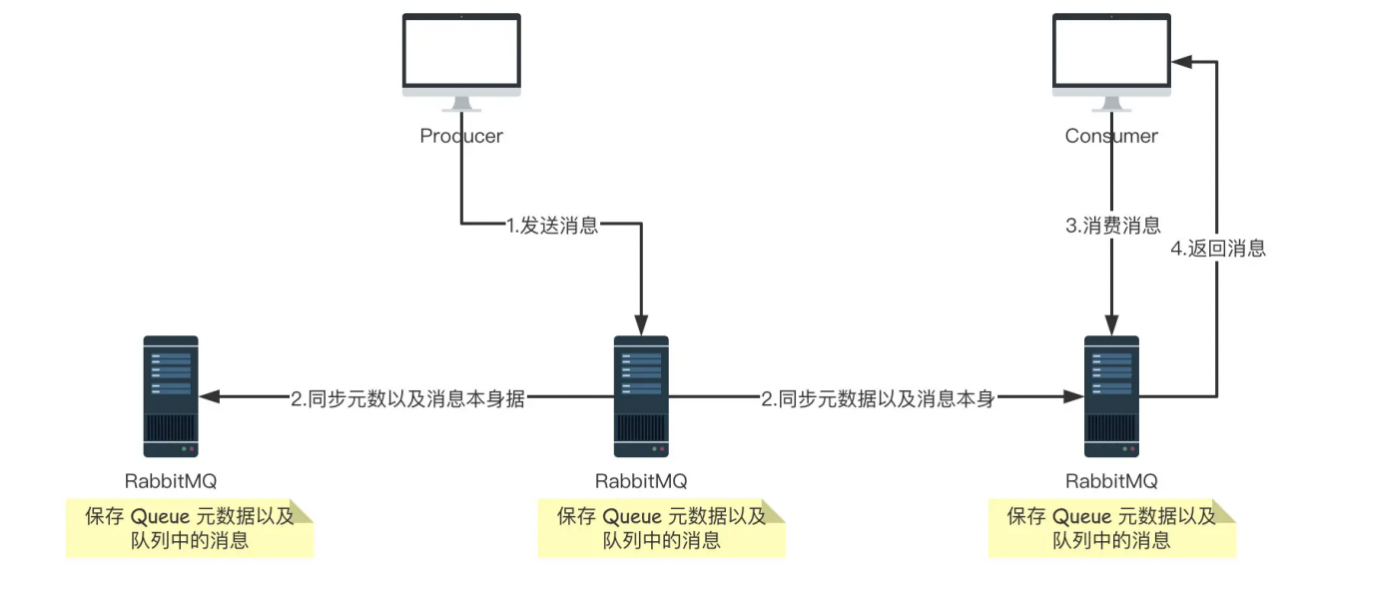
1.2 镜像集群
它和普通集群最大的区别在于 Queue 数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上。也就是说每个 RabbitMQ 实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用。
大致流程图如下图:
1.3 节点类型
RabbitMQ 中的节点类型有两种:
1)RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得交换机和队列声明等操作速度更快。
2)Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启 RabbitMQ 的时候,丢失系统的配置信息
RabbitMQ 要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。为了确保集群信息的可靠性,或者在不确定使用磁盘节点还是内存节点的时候,建议直接用磁盘节点。
2. 搭建基础集群
2.1 环境准备
系统系统:CentOS7 64位
三台服务器:10.90.0.9/10/11
服务器规划
服务器用途主机名节点类型
10.90.0.11 | RabbitMQ 集群节点 1 | dev-big-data01 | 磁盘节点 |
10.90.0.9 | RabbitMQ 集群节点 2 | dev-big-data02 | 磁盘节点 |
10.90.0.10 | RabbitMQ 集群节点 3 | dev-big-data03 | 磁盘节点 |
2.2 erlang 安装
# 下载erlang软件包源
wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
sudo yum install epel-release -y
# 安装erlang软件包源
sudo rpm -Uvh erlang-solutions-1.0-1.noarch.rpm
# 安装erlang环境
sudo yum install erlang -y
验证:

2.3 rabbitmq 安装
# 下载介质源
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.9.16/rabbitmq-server-3.9.16-1.el7.noarch.rpm
# 安装介质源
yum install -y rabbitmq-server-3.9.16-1.el7.noarch.rpm
# 打开开启动
systemctl enable rabbitmq-server
# 启动服务
systemctl start rabbitmq-server
# 查看服务状态
systemctl status rabbitmq-server
验证:
3. 创建集群
3.1 配置 erlang cookie
RabbitMQ 集群是基于 erlang 进行同步的,在 erlang 的集群中各节点同步需要一个相同的 cookie,所以必须保证各节点 cookie 一致,不然节点之间就无法通信,,这个 cookie 默认存放在 /var/lib/rabbitmq/.erlang.cookie 中。
在任意一个节点中 copy .erlang.cookie 文件到其它所有节点,如在 node1 上进行 copy :

注意:
各节点都必须停止MQ服务
拷贝过去之后权限要进行修改,否则rabbitmq服务会无法启动
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie //属主,属组
chmod 400 /var/lib/rabbitmq/.erlang.cookie // 修改文件权限
重启所有服务
systemctl restart rabbitmq-server
3.2 将节点加入到集群中
将 node2、node3 节点加入 node1 节点集群中,在 node2、node3中分别执行以下命令:
# rabbitmqctl stop_app
# rabbitmqctl join_cluster rabbit@node1
# rabbitmqctl start_app
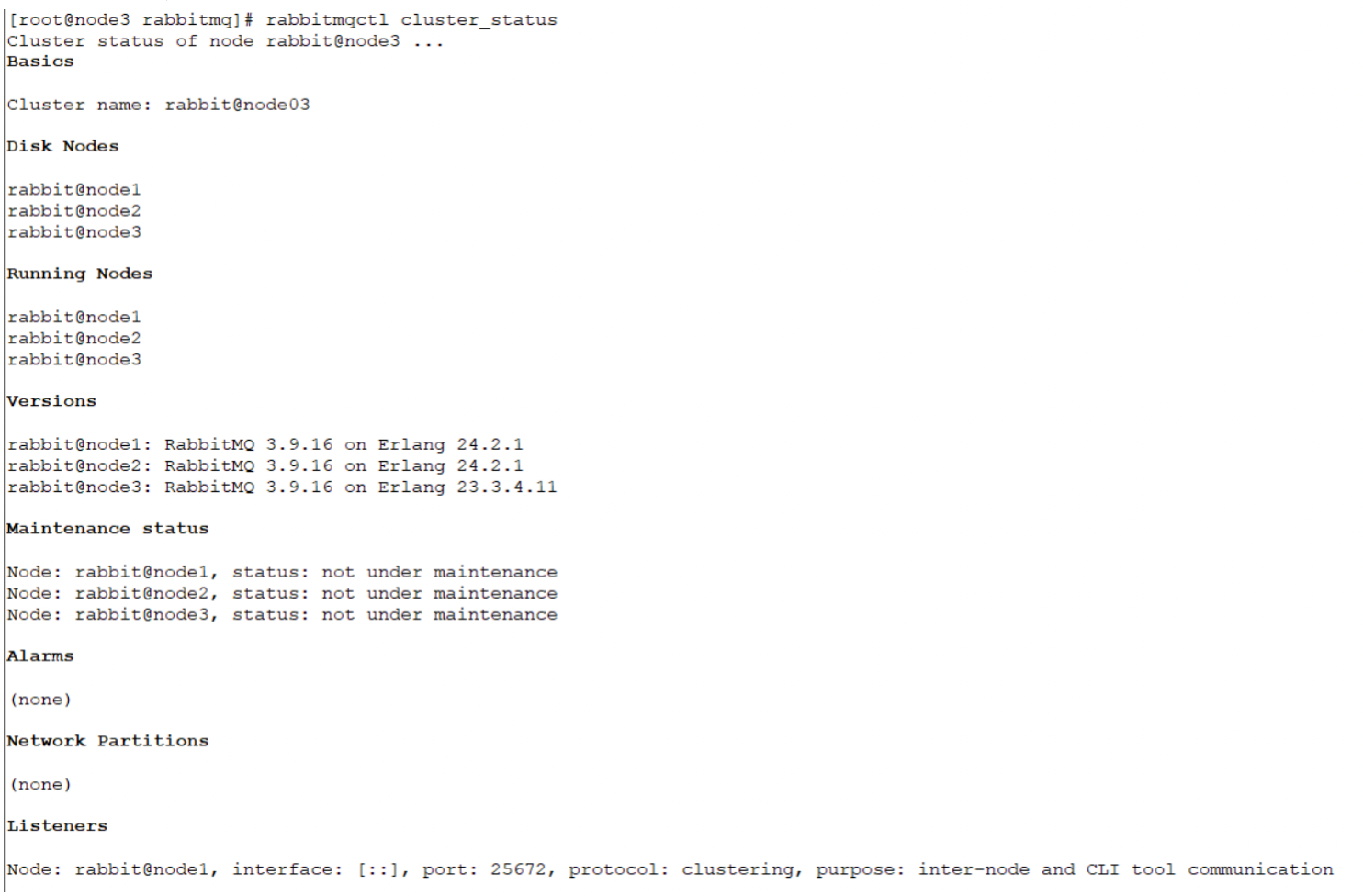
默认 RabbitMQ 启动后是磁盘节点,在这个 cluster 下,node1、node2 和 node3 都是是磁盘节点。
如果要使 node2、node3 都是内存节点,加上 --ram 参数即可,如 rabbitmqctl join_cluster --ram rabbit@node1。
如果想要更改节点类型,可以使用命令 rabbitmqctl change_cluster_node_type disc(ram),修改节点类型前需要先 rabbitmqctl stop_app。
(Note: disk and disc are used interchangeably)
验证是否加入:
3.3 将集群设为镜像模式
镜像模式参数
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: exchanges或queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual。automatic:新增加节点自动同步全量数据。manual: 新增节点只同步新增数据,全量数据需要手工同步。
Priority:可选参数,policy的优先级
设置实例
# 所有队列exchangess 或者 queue都为镜像模式
[root@rabbitmq-01 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
# 对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
[root@rabbitmq-01 ~]# rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^queue_" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
3.3 集群验证
3.3.1 开启插件
所有机器执行命令: rabbitmq-plugins enable rabbitmq_management
设置账户:
rabbitmqctl add_user admin 密码 // 添加用户名
rabbitmqctl set_user_tags admin administrator // 提升管理员
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*" // 为 admin 用户配置所有权限
在浏览器中访问 http://10.90.0.11:15672
3.3.2镜像集群验证
上面我们已经设置过策略,全部队列都做镜像模式,这里我们创建一个队列
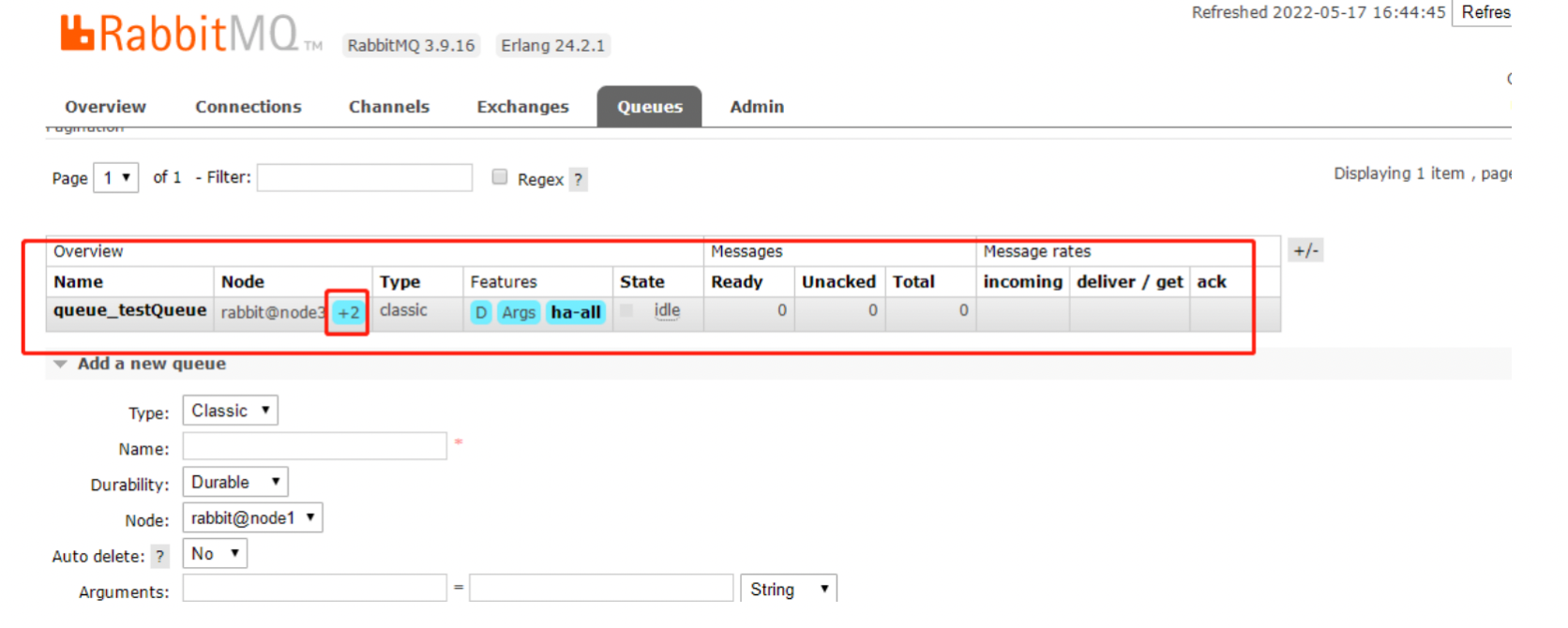
可以看到我们创建了queue_testQueue队列,Node中的+2表示备份,下图中的Mirrors就是备份的节点,若node3宕机了node1,node2就会代替node3继续提供服务
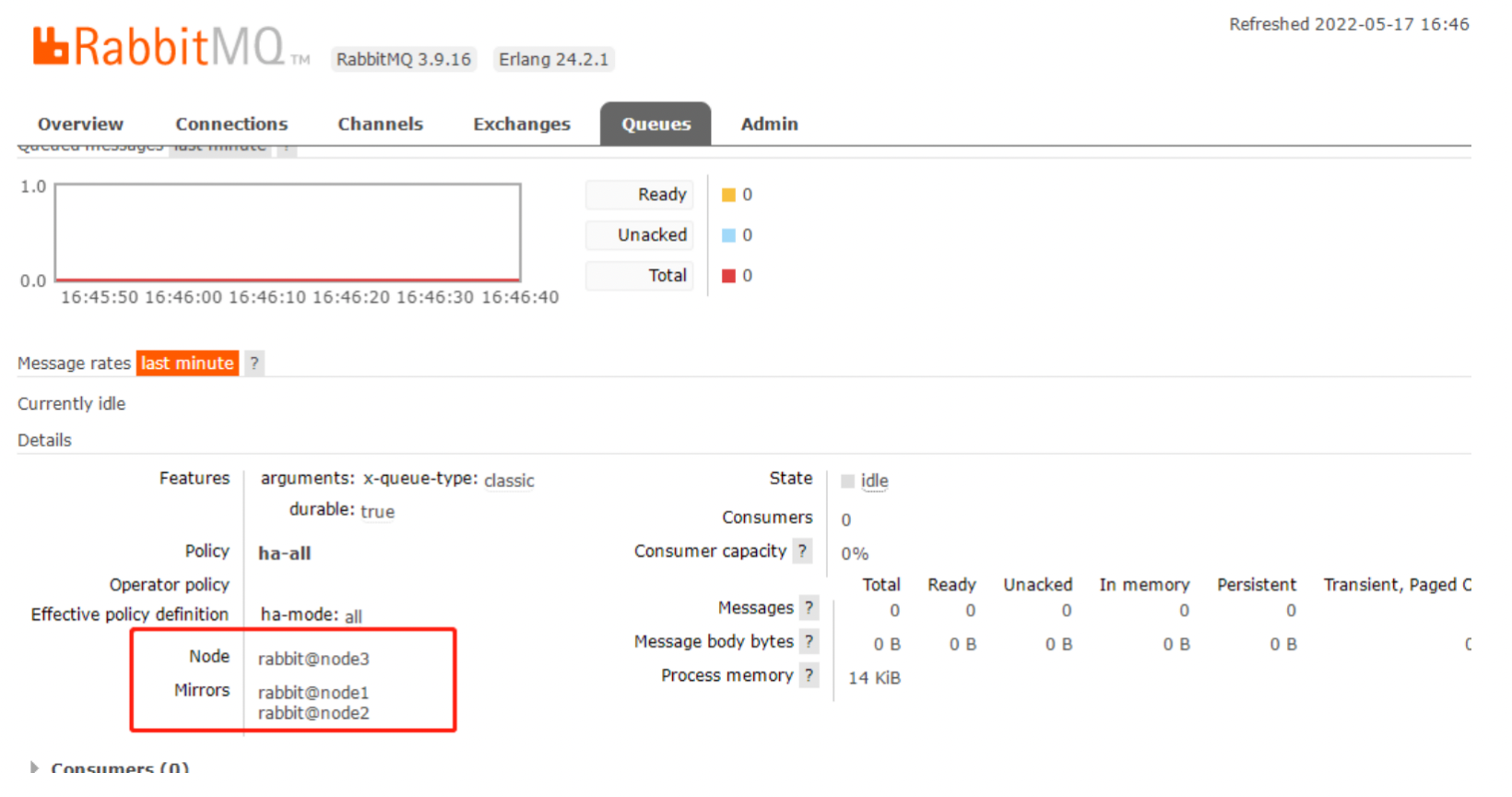
测试:首先关闭node3 节点
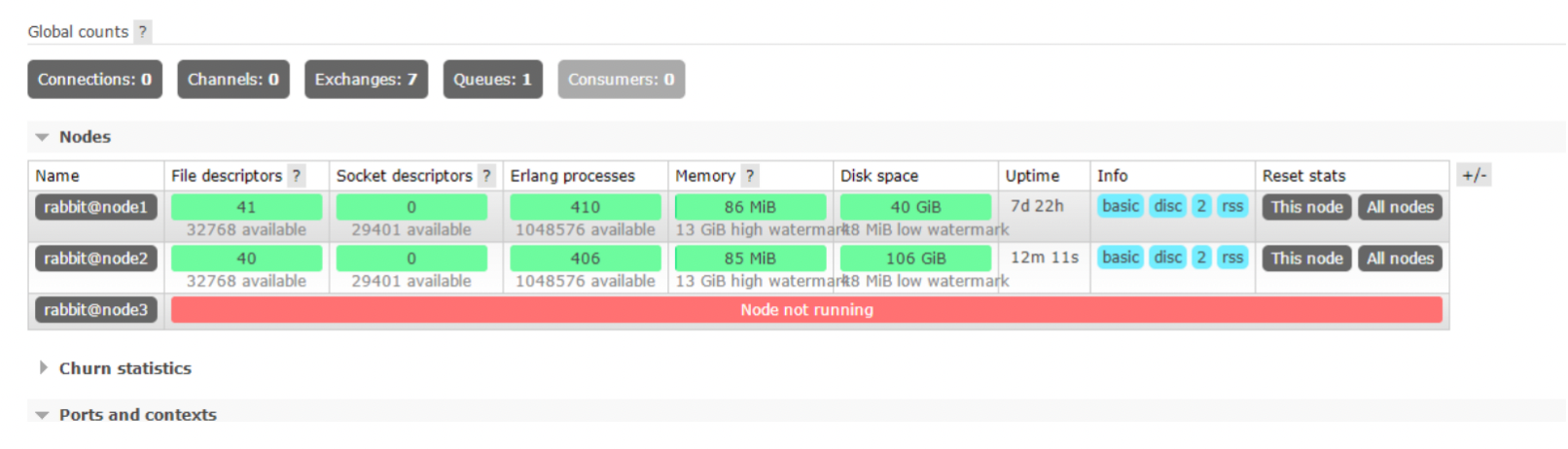
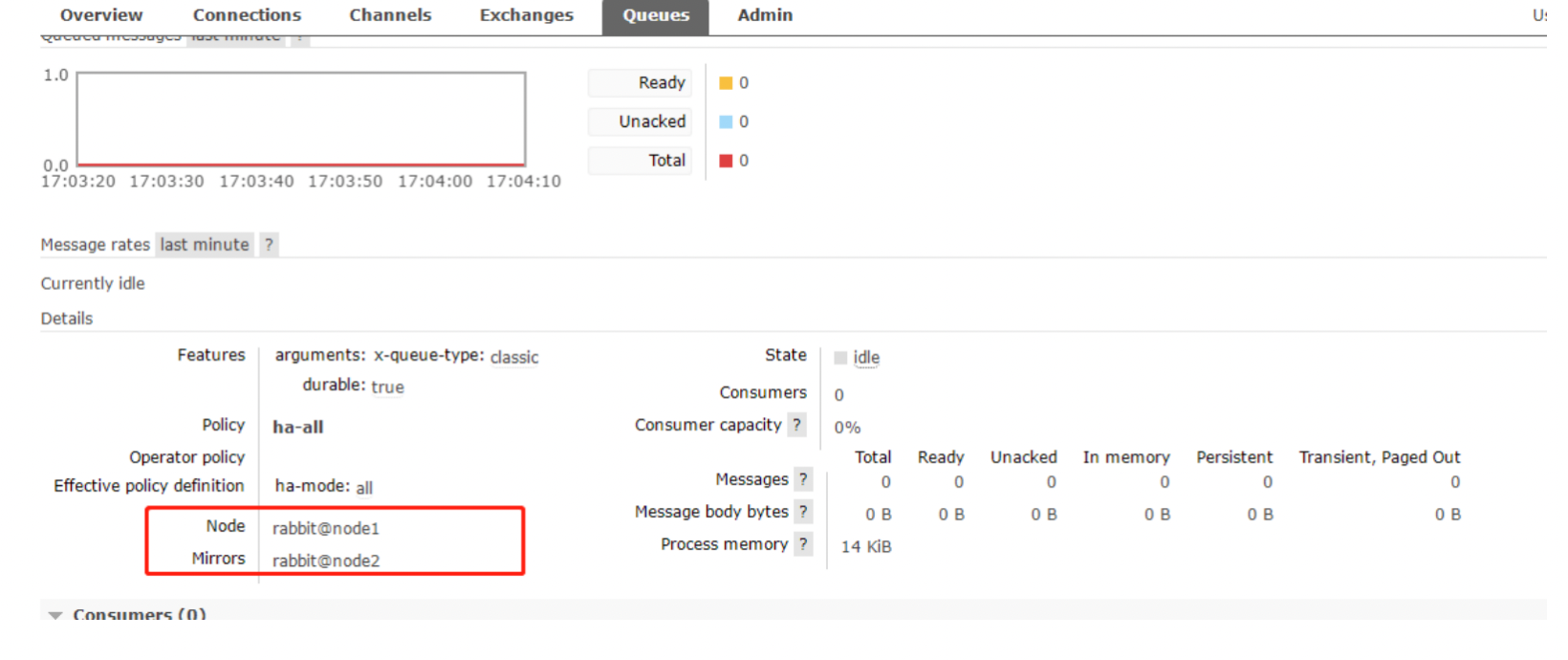
然后查看node1,node2 节点上的镜像状态,发现在node1,node2 节点也进行了备份,以此说明:就算整个集群只剩下一台机器了,依然能消费队列里面的消息
4 负载均衡
4.1 安装haproxy
yum install haproxy -y
4.2 配置haproxy
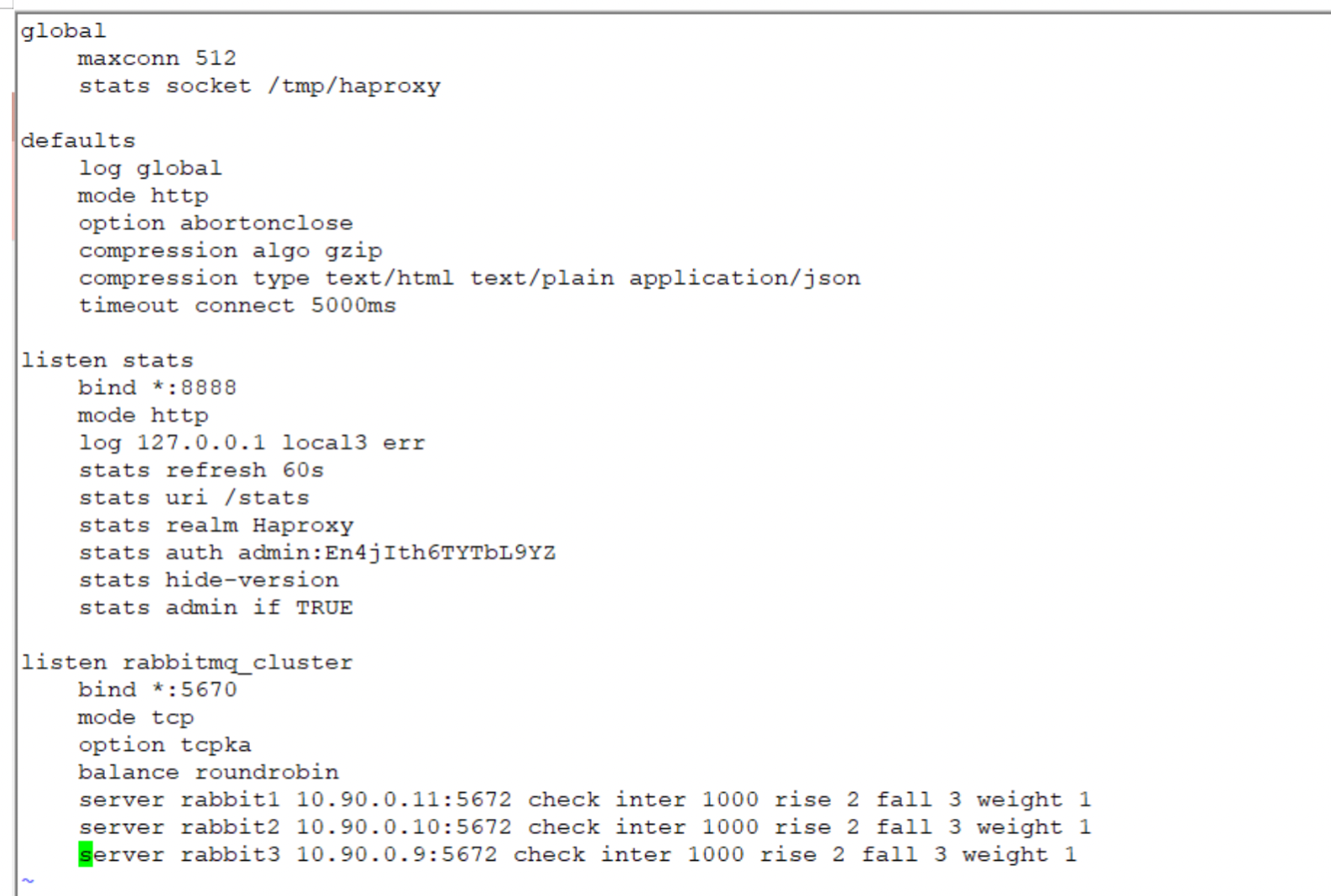
vim /etc/haproxy/haproxy.cfg 编辑 haproxy 配置文件,修改如下
4.3 运行haproxy
systemctl restart haproxy //运行 haproxy
systemctl status haproxy //查看状态
浏览器访问 http://10.90.0.9:8888/stats,输入配置中的用户名和密码登录
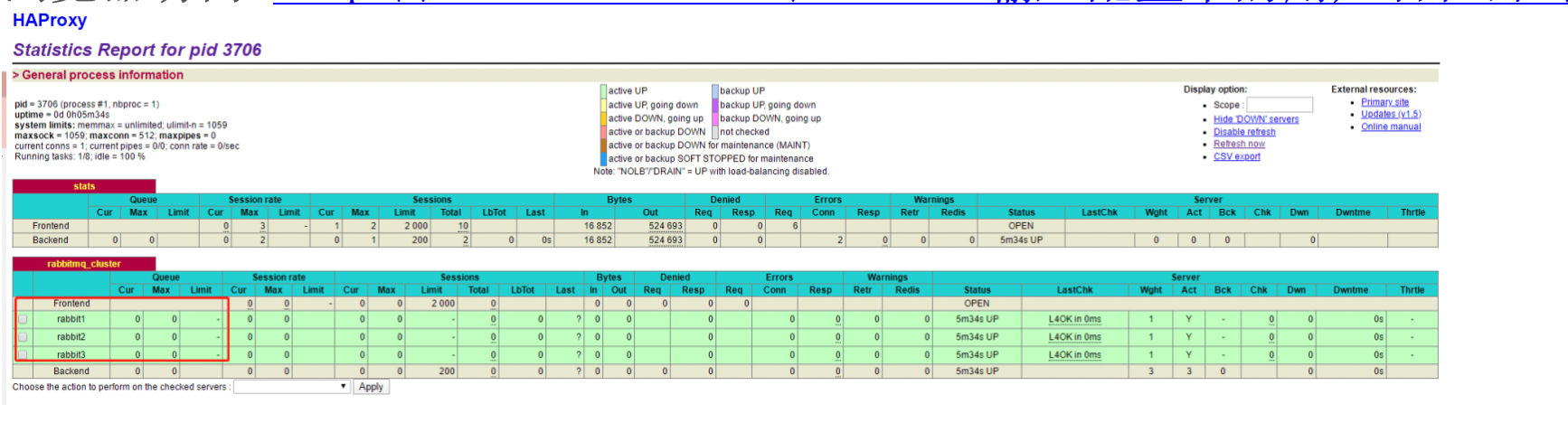
5 集群启动和关闭
5.1 停止集群
集群是不能通过一个命令完全停止的,它必须对各个节点依次停止才能最终停止集群,而且基准节点要作为最后一个停止,先停止其它加入到基准节点的节点.
例如,我们上述将node2机器和node3机器的节点加入到node1机器的基准节点,那么停止时需要先停止node2机器和node3机器的节点,最后再停止node1机器节点(注:集群启动时就与此顺序相反,先启动node1机器的节点,再启动node2和node3的节点),按照顺序执行如下:
./rabbitmqctl stop
按照node3、node2、node1的顺序执行此条命令即可停止整个集群。
5.2 重启/重置节点
重启某一个节点执行步骤如下:
./rabbitmqctl stop
./rabbitmq-server -detached
注:重启节点实际上就是先执行停止,再启动即可,不需要再次加入到集群节点中,启动之后节点自动会加入到集群中(初次加入集群就需要加入某一个节点)。重置某一个节点,就是先停止该节点,然后执行reset命令清除所有数据,接着加入到集群中并启动,如下/rabbitmqctl stop_app
./rabbitmqctl reset
./rabbitmqctl join_cluster rabbit@NodeName
./rabbitmqctl start_app
注:重启过程中,节点停止后主节点同步过来的数据将无法保存在此节点,同理重置过程中,节点停止后也将无法获取同步的数据,reset重置还会将此节点原来所有的数据(队列、交换器、虚拟机、用户和同步过来的消息等)全部清除,直到重新加入集群、重启节点后可再次同步数据。
5.3 创建内存节点
前面说到内存节点和磁盘节点的区别,当我们把一个节点加入到集群中时,默认是以磁盘节点加入集群的,如果要以内存节点加入集群,只需要在加入集群时带上–ram参数就行了,如下:
./rabbitmqctl join_cluster --ram rabbit@NodeName1
5.4 改变节点类型
通过改变节点类型可以将磁盘节点改为内存节点,也可以将内存节点改为磁盘节点,如下:
./rabbitmqctl stop_app
./rabbitmqctl change_cluster_node_type disc
# disc是磁盘节点,ram是内存节点
./rabbitmqctl start_app