nginx分发算法
如何将用户请求按照一定的规律分发给业务服务器。主要分为Nginx集群默认算法和基于请求头分发算法。
二、nginx集群默认算法
nginx的upstream 目前支持4种方式的分配
轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。用于处理静态页面
weight 指定权重,数值大的服务器,获得的请求的数量越多,用于后端服务器性能不均的情况。用于处理静态页面
ip_hash 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务,好处是可以解决session的问题。可以处理动态网站。
url_hash(第三方) 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务 ,后端服务器为缓存时比较有效。
nginx有很多第三方模块,各位可以去下载使用
https://www.nginx.com/resources/wiki/modules/
三、nginx业务服务器状态
每个设备的状态设置参数:
down 表示当前的server暂时不参与负载;
weight 默认为1,weight越大,负载的权重就越大;
max_fails 允许请求失败的次数默认为1,当超过最大次数时,返回proxy_next_upstream模块定义的错误;
fail_timeout 失败超时时间,在连接Server时,如果在超时时间之内超过max_fails指定的失败次数,会认为在fail_timeout时间内Server不可用,默认为10s
backup 其他所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
四、nginx集群默认算法测试
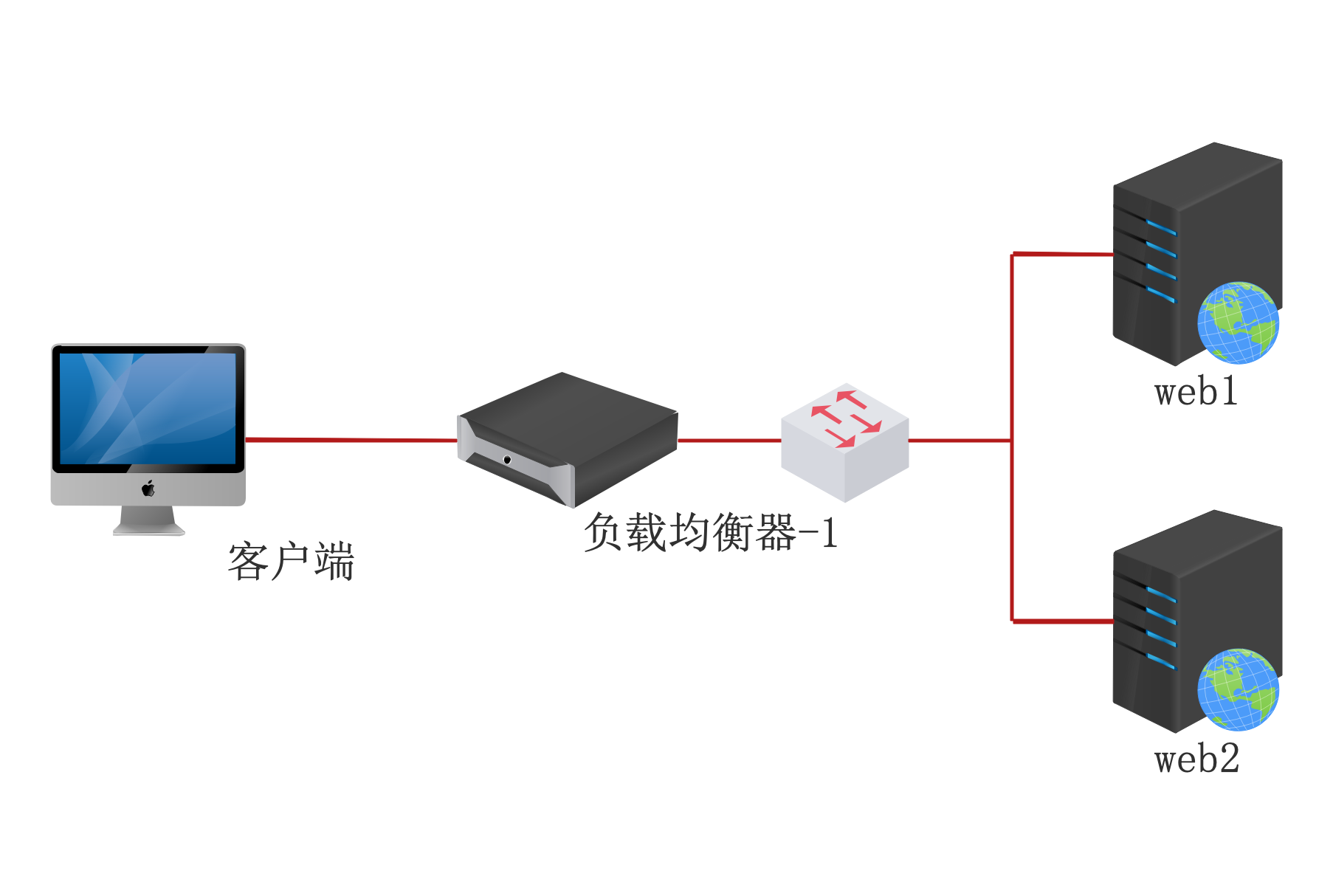
实验环境
实验机 :四台虚拟机,一台测试机,一台分发器,两台web服务器。
网卡:vmnet4
系统:CentOS8.0
SELinux&防火墙:关闭
网段:192.168.0.0/24
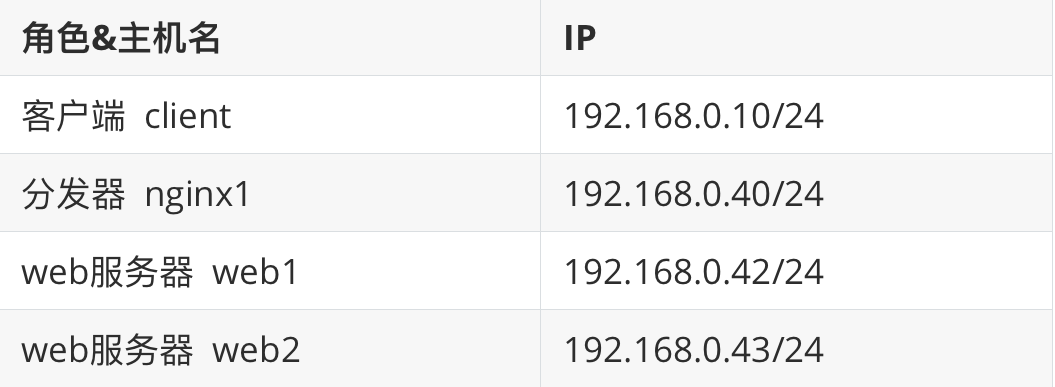
实验拓扑
4.1、轮询算法
upstream web {
server 192.168.0.42;
server 192.168.0.43;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
}
}
前面已经测试验证了轮询算法分发。
配置backup参数
upstream web {
server 192.168.0.42;
server 192.168.0.43 backup;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
}
}
先正常访问测试
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web1
关停第一个节点情况,访问尝试:
[root@web1 ~]# systemctl stop httpd
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
启动第一个节点测试
[root@web1 ~]# systemctl start httpd
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web1
4.2、基于权重
通过配置权重,可以让性能好的服务器承担更多的负载
upstream web {
# 设置权重比例1:2
server 192.168.0.42 weight=1;
server 192.168.0.43 weight=2;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
}
}
测试
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web1
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
4.3、基于ip_hash分发
ip_hash算法能够保证来自同样源地址的请求都分发到同一台主机。 需要注意:ip_hash算法不支持backup、weight设置。默认权重为1。
upstream web {
ip_hash; # 指定ip_hash即可,默认weight权重比例1: 1
server 192.168.0.42;
server 192.168.0.43;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
}
}
测试
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
[root@client ~]# curl 192.168.0.40
web2
切换到另外一台不同网段的主机
MacBook-Pro:~ hello$ ifconfig
vmnet8: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:50:56:c0:00:08
inet 172.16.121.1 netmask 0xffffff00 broadcast 172.16.121.255
MacBook-Pro:~ hello$ curl 172.16.121.134
web1
MacBook-Pro:~ hello$ curl 172.16.121.134
web1
MacBook-Pro:~ hello$ curl 172.16.121.134
web1
4.4、基于url的hash
不同的URL我去找不同的机器访问,就是把url计算出一个值然后除以机器的数量取余 ,需要安装第三方插件
nginx分发器上,将nginx主程序包和下载好的第三方软件包放在同一个目录下解压
[root@master ~]# cd nginx-1.15.12/
[root@master ~]# ./configure --prefix=/usr/local/nginx --add-module=/root/ngx_http_consistent_hash-master
第三方模块的安装方法
[root@master ~]# make & make install
[root@master ~]# vim /usr/local/nginx/conf/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream web {
consistent_hash $request_uri;
server 192.168.0.42 ;
server 192.168.0.43 ;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
[root@master ~]# /usr/local/nginx/sbin/nginx
在web主机上生成测试页面
[root@web1 ~]# for i in `seq 1 10`; do echo "web1_$i" > /var/www/html/$i.html; done
[root@web2 ~]# for i in `seq 1 10`; do echo "web2_$i" > /var/www/html/$i.html; done
这样我们就知道测试的时候访问的是哪台机器的页面文件了
测试访问
[root@client ~]# for i in `seq 1 10`; do curl http://192.168.0.40/$i.html; done
web1_1
web1_2
web1_3
web2_4
web2_5
web1_6
web2_7
web1_8
web2_9
web2_10