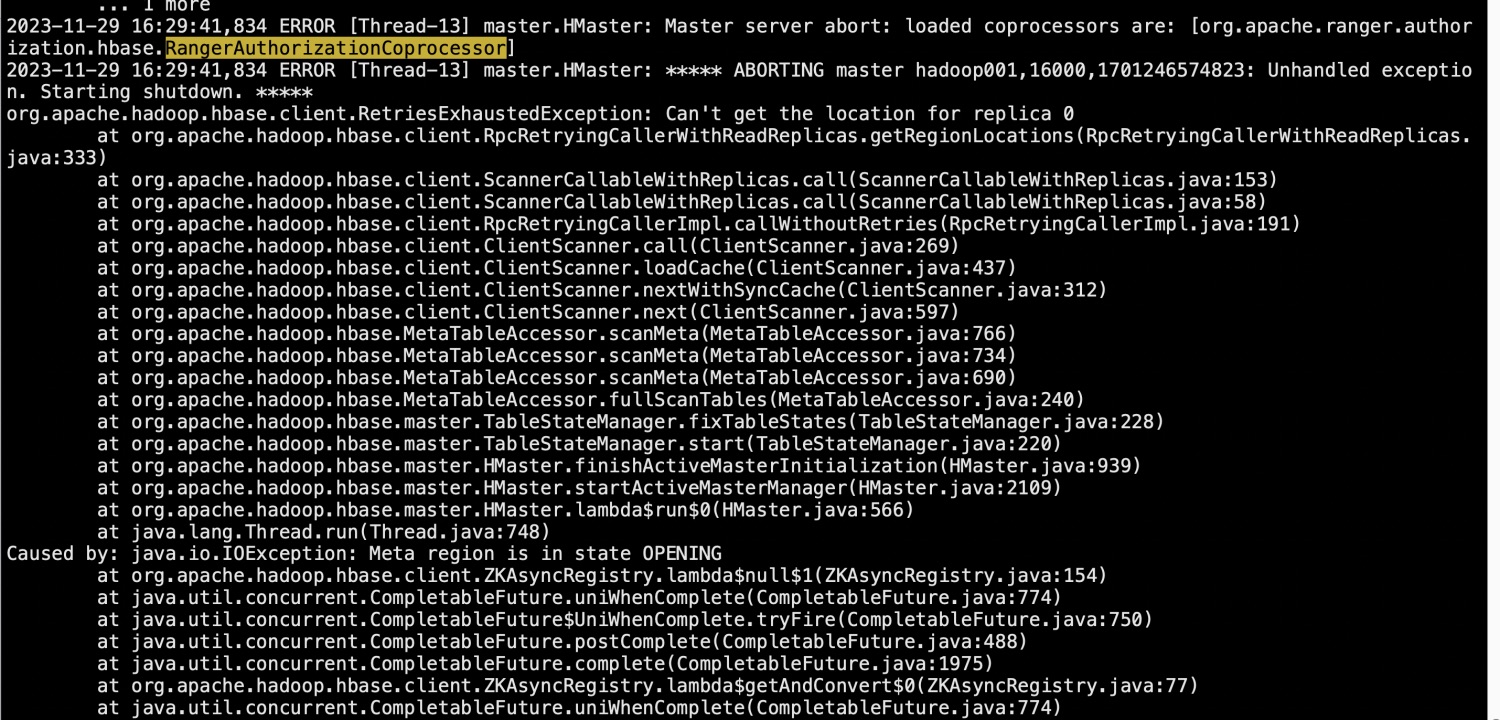
Hbase部署
安装前准备
1.1. 设置环境变量
所有hbase节点都要做
vi /etc/profile
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
1.2. 创建用户及用户组
创建用户组
groupadd hbase
创建用户
useradd hbase -s /bin/bash -m -g hbase
usermod -aG hadoop hbase
安装hbase
1.3. 解压安装包
tar -zxf /opt/hbase-2.1.0.tar.gz -C /opt/
1.4. 分发软件包
分发软件包到别的hbase节点并创建软链接
scp -rp /opt/hbase-2.1.0 xxx.xxx.xxx.222:/opt
scp -rp /opt/hbase-2.1.0 xxx.xxx.xxx.10/opt
scp -rp /opt/hbase-2.1.0 xxx.xxx.xxx.11/opt
scp -rp /opt/hbase-2.1.0 xxx.xxx.xxx.12/opt
ln -s /opt/hbase-2.1.0 /opt/hbase
1.5. 创建目录并修改权限
mkdir -p /log/hbase
chown -R hbase:hbase /opt/hbase /log/hbase
su - hdfs
hdfs dfs -mkdir /hbase
hdfs dfs -chown hbase:hbase /hbase
配置hbase
1.6. 配置hbase-env.sh文件
vim $HBASE_HOME/conf/hbase-env.sh
内容如下:
export HBASE_MANAGES_ZK=false
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
export JAVA_HOME=/opt/jdk1.8
export HBASE_LOG_DIR=/log/hbase
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
1.7. 配置hbase-site.xml文件
vim /opt/hbase/conf/hbase-site.xml
1.8. 配置regionservers文件
vim /opt/hbase/conf/regionservers
内容如下:
xxx.xxx.xxx.10
xxx.xxx.xxx.11
xxx.xxx.xxx.12
1.9. 配置backup-masters文件
vim /opt/hbase/conf/backup-masters
内容如下:
xxx.xxx.xxx.222
1.10. 复制hdfs-site.xml到$HBASE_HOME/conf/下
cp /opt/hadoop/etc/hadoop/hdfs-site.xml /opt/hbase/conf/
启动hbase
su - hbase
cd /opt/hbase/bin
启动
./start-hbase.sh