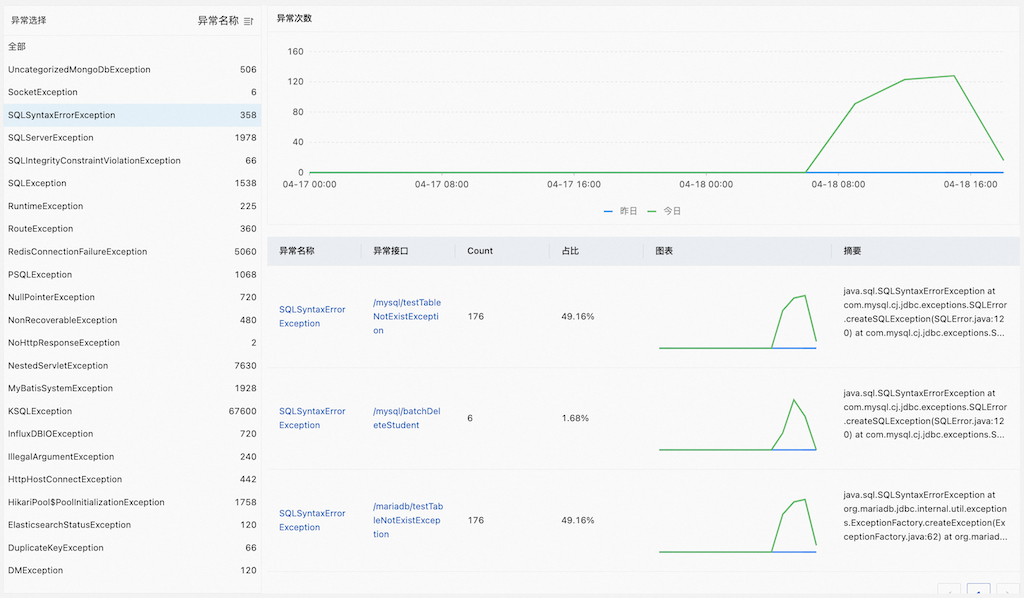
Hbase 存储相关知识
1.Hbase的写流程
Client 写入-> 存入MemStore,一直到MemStore 满-> Flush 成一个StoreFile,直至增长到一定阈值-> 触发Compact 合并操作-> 多个StoreFile 合并成一个StoreFile,同时进行版本合并和数据删除-> 当StoreFiles Compact 后,逐步形成越来越大的StoreFile -> 单个StoreFile 大小超过一定阈值后(默认10G),触发Split 操作,把当前Region Split 成2 个Region,Region 会下线,新Split出的2个子Region 会被HMaster 分配到相应的HRegionServer 上,使得原先1 个Region的压力得以分流到2 个Region 上
由此过程可知,HBase 只是增加数据,没有更新和删除操作,用户的更新和删除都是逻辑层面的,在物理层面,更新只是追加操作,删除只是标记操作。
用户写操作只需要进入到内存即可立即返回,从而保证I/O 高性能。
2.Hbase 的存储结构
Hbase 中的每张表都通过行键(rowkey)按照一定的范围被分割成多个子表(HRegion),默认一个HRegion 超过256M 就要被分割成两个,由HRegionServer管理,管理哪些HRegion 由Hmaster 分配。HRegion 存取一个子表时,会创建一个HRegion 对象,然后对表的每个列族(Column Family)创建一个store 实例, 每个store 都会有0 个或多个StoreFile 与之对应,每个StoreFile 都会对应一个HFile,HFile 就是实际的存储文件,一个HRegion 还拥有一个MemStore 实例。
3.HDFS 和HBase 各自使用场景
首先一点需要明白:Hbase 是基于HDFS 来存储的。
HDFS:
1. 一次性写入,多次读取。
2. 保证数据的一致性。
3. 主要是可以部署在许多廉价机器中,通过多副本提高可靠性,提供了容错和恢复机制。
HBase:
1. 瞬间写入量很大,数据库不好支撑或需要很高成本支撑的场景。
2. 数据需要长久保存,且量会持久增长到比较大的场景。
3. HBase 不适用与有join,多级索引,表关系复杂的数据模型。
4. 大数据量(100s TB 级数据)且有快速随机访问的需求。如:淘宝的交易历史记录。数据量巨大无容置疑,面向普通用户的请求必然要即时响应。
5. 业务场景简单,不需要关系数据库中很多特性(例如交叉列、交叉表,事务,连接等等)。