Flink sql 集成hive metastore
1、前置条件
**确认hive metastore版本(本次版本3.1.2) **
hive metastore 部署成功
hive依赖jar包分发到每个flink节点:
/flink-1.13.6 /lib // Flink's Hive connector flink-connector-hive_2.11-1.13.6.jar //在https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/hive/overview/ 下载 // Hive dependencies hive-exec-3.1.0.jar libfb303-0.9.3.jar // libfb303 is not packed into hive-exec in some versions, need to add it separately // add antlr-runtime if you need to use hive dialect antlr-runtime-3.5.2.jar // hadoop jar包 flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
如果需要适配s3,请检查flink目录的plugin是否存在
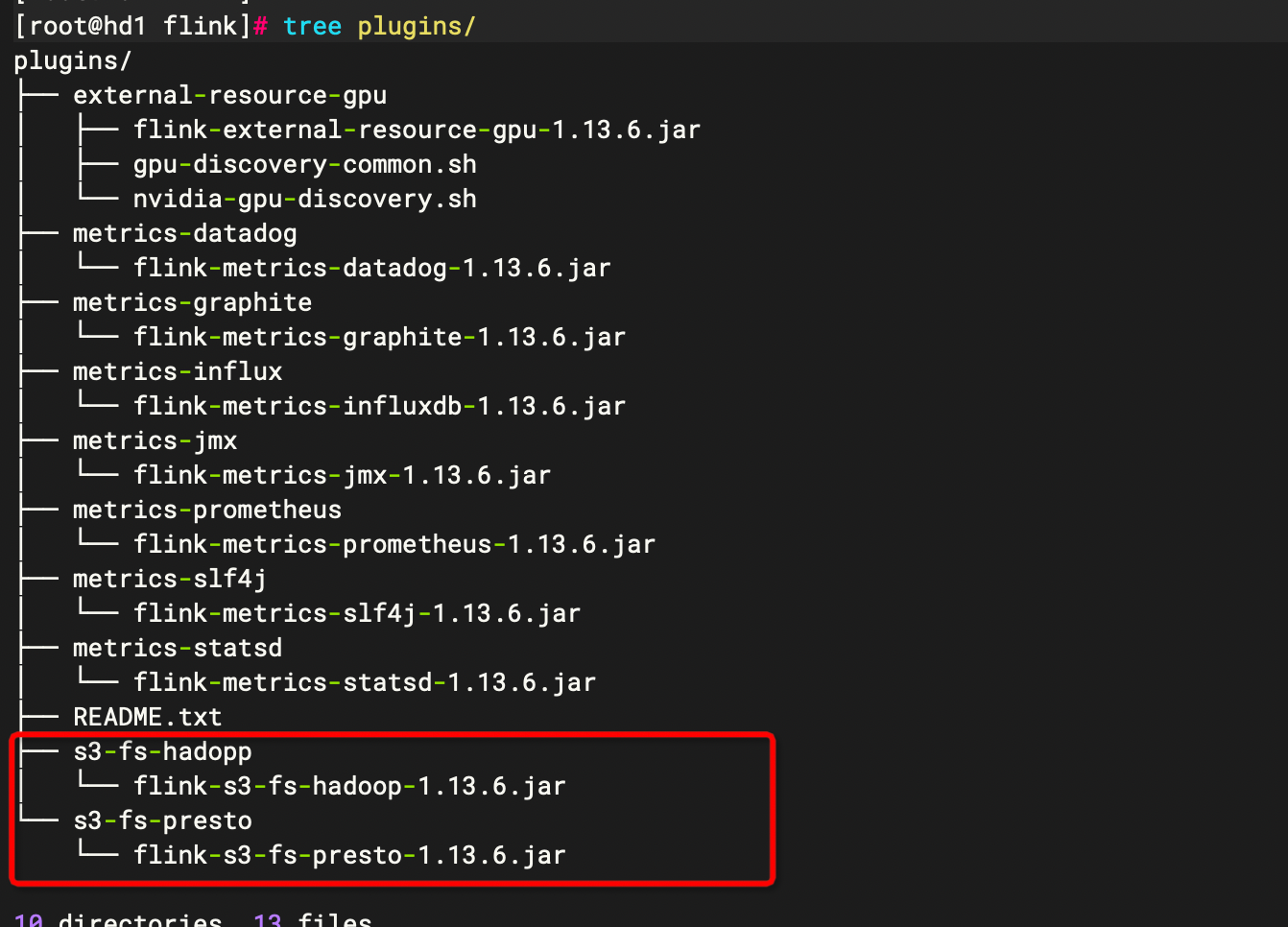

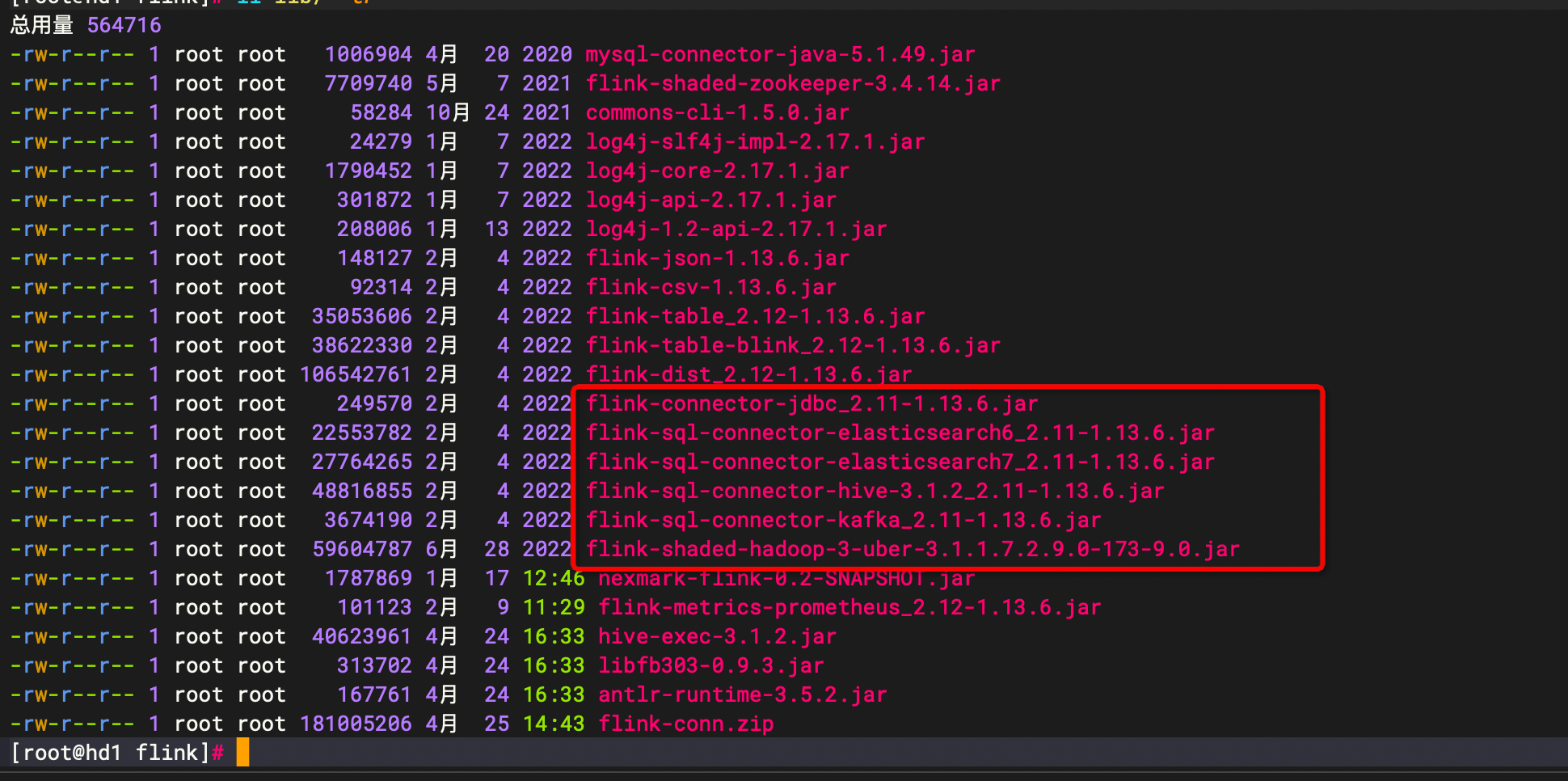
如果要支持如mysql ,es,kafka,也如上的hive依赖jar包分发
对应jar包下载地址,请查看此链接的对应模块
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/jdbc/



2、配置flink
1、flink sql 配置
jobmanager.rpc.address: localhost jobmanager.rpc.port: 6123 jobmanager.memory.process.size: 1600m taskmanager.memory.process.size: 1728m taskmanager.numberOfTaskSlots: 1 parallelism.default: 1 jobmanager.execution.failover-strategy: region classloader.check-leaked-classloader: false
2、sql client 配置
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
# This file defines the default environment for Flink's SQL Client.
# Defaults might be overwritten by a session specific environment.
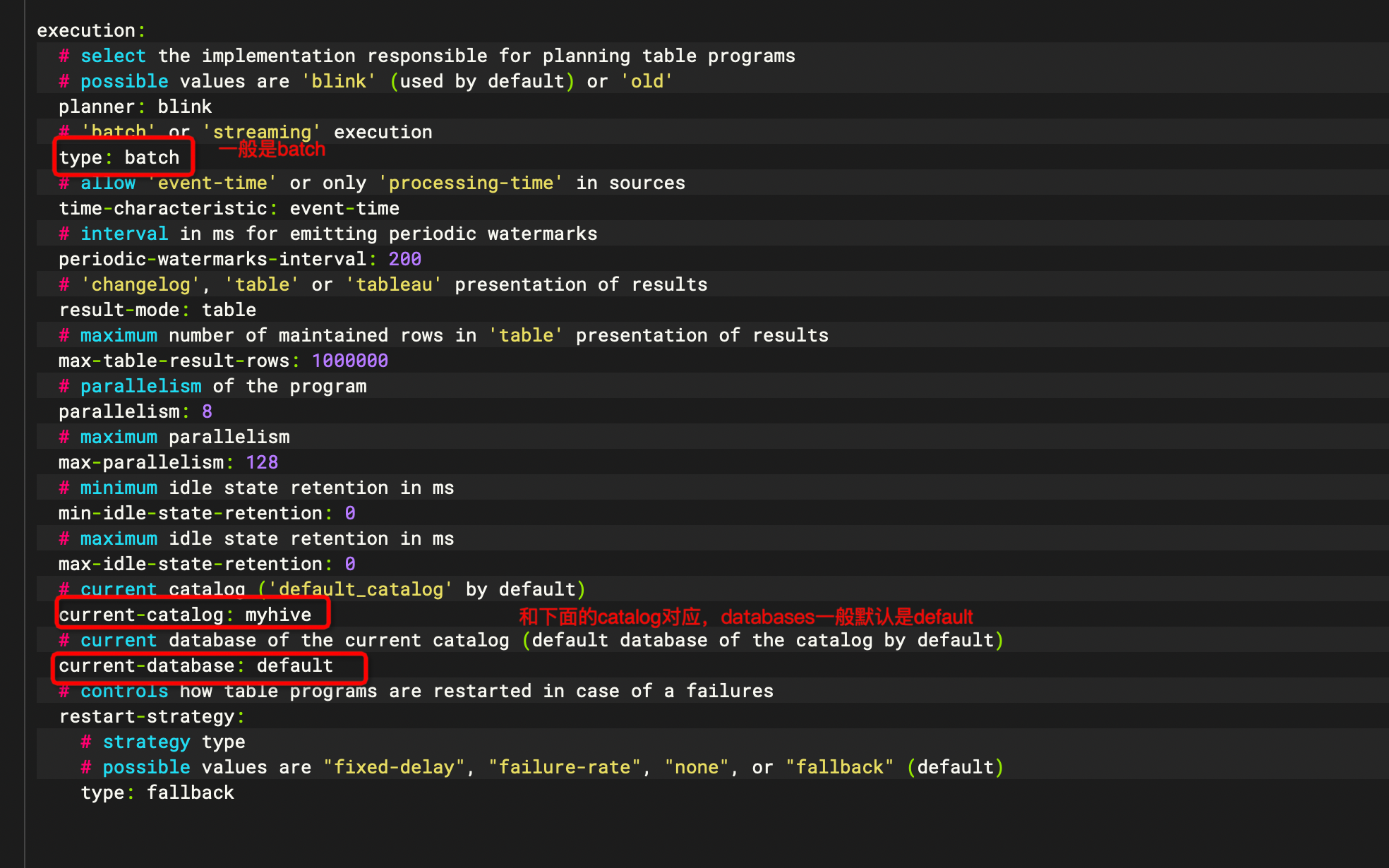
execution:
# select the implementation responsible for planning table programs
# possible values are 'blink' (used by default) or 'old'
planner: blink
# 'batch' or 'streaming' execution
type: batch
# allow 'event-time' or only 'processing-time' in sources
time-characteristic: event-time
# interval in ms for emitting periodic watermarks
periodic-watermarks-interval: 200
# 'changelog', 'table' or 'tableau' presentation of results
result-mode: table
# maximum number of maintained rows in 'table' presentation of results
max-table-result-rows: 1000000
# parallelism of the program
parallelism: 8
# maximum parallelism
max-parallelism: 128
# minimum idle state retention in ms
min-idle-state-retention: 0
# maximum idle state retention in ms
max-idle-state-retention: 0
# current catalog ('default_catalog' by default)
current-catalog: default_catalog
# current database of the current catalog (default database of the catalog by default)
current-database: default_database
# controls how table programs are restarted in case of a failures
restart-strategy:
# strategy type
# possible values are "fixed-delay", "failure-rate", "none", or "fallback" (default)
type: fallback
#==============================================================================
# Configuration options
#==============================================================================
# Configuration options for adjusting and tuning table programs.
# A full list of options and their default values can be found
# on the dedicated "Configuration" web page.
# A configuration can look like:
configuration:
table.exec.mini-batch.enabled: true
table.exec.mini-batch.allow-latency: 2s
table.exec.mini-batch.size: 50000
table.optimizer.distinct-agg.split.enabled: true
# table.sql-dialect: hive
#catalogs:
# - name: myhive
# type: hive
# hive-conf-dir: /opt/flink/conf
# hive-version: 3.1.2
# hadoop-conf-dir: /opt/flink/conf
#==============================================================================
# Deployment properties
#==============================================================================
# Properties that describe the cluster to which table programs are submitted to.
deployment:
# general cluster communication timeout in ms
response-timeout: 5000
# (optional) address from cluster to gateway
gateway-address: ""
# (optional) port from cluster to gateway
gateway-port: 0