借助cwRsync工具迁移
服务端
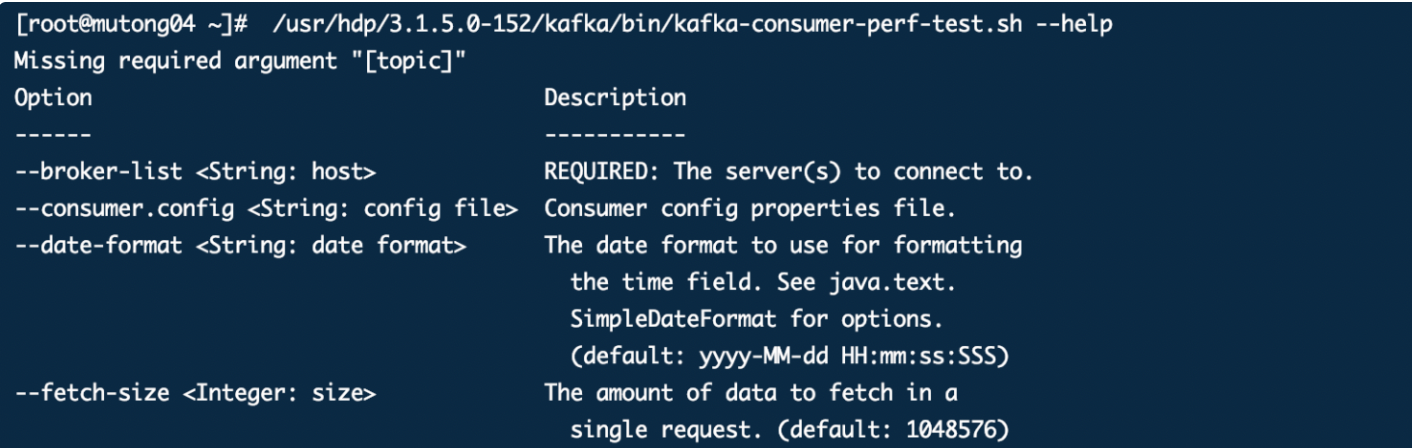
安装服务端软件
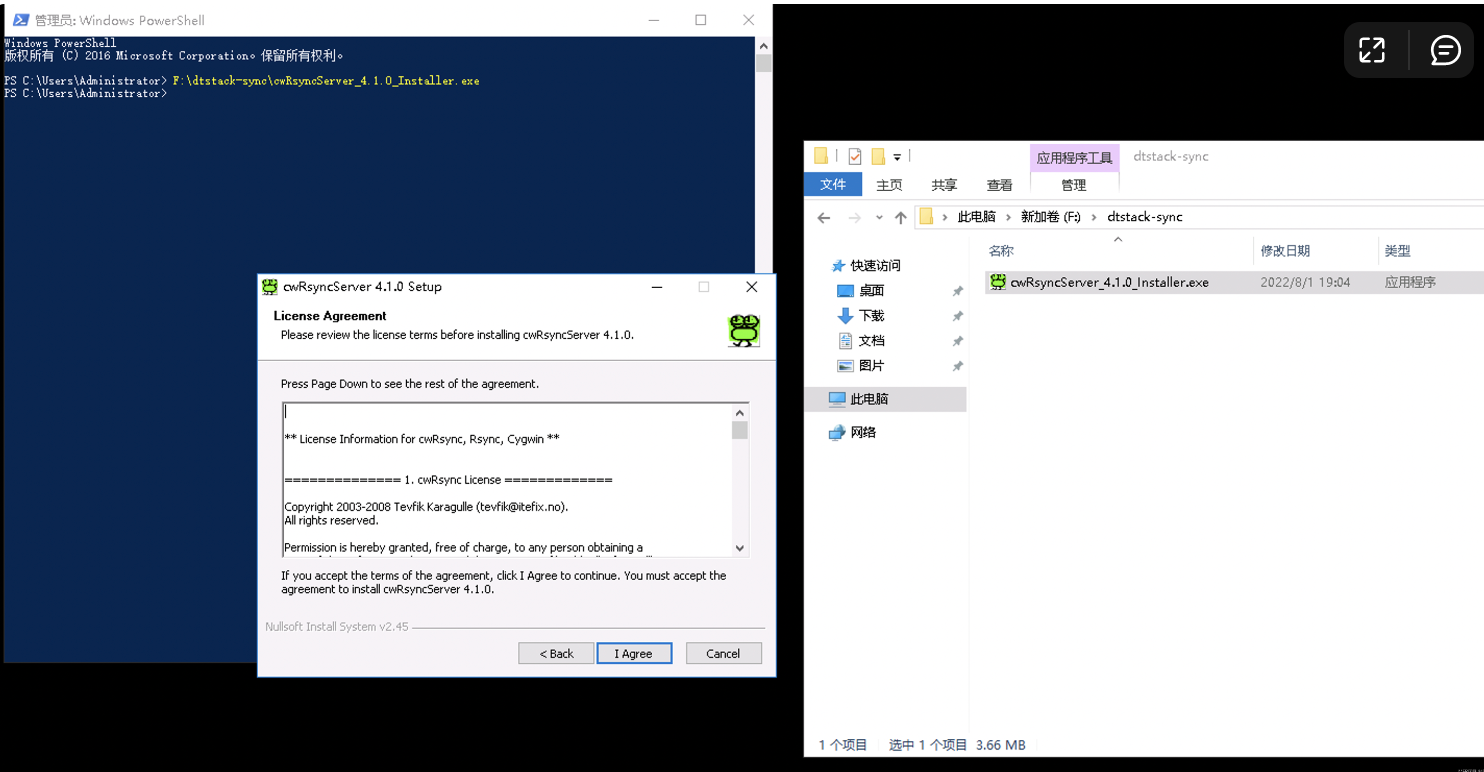
![]()
如下,会自动在系统内创建一个系统用户,用户名为:xxx ,密码为:xxx
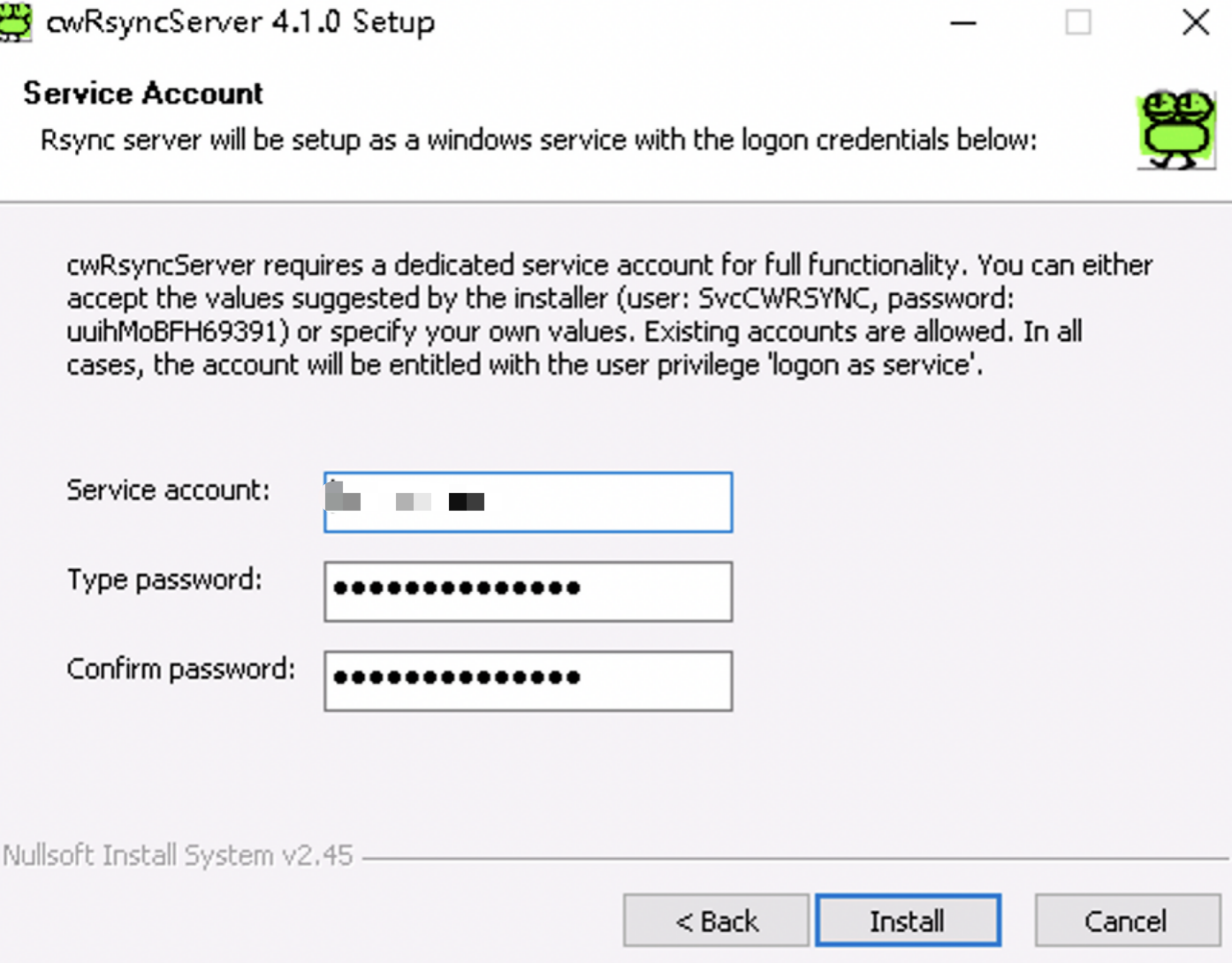
查看系统用户,会发现自动创建了如下用户:
修改配置文件:rsyncd.conf
use chroot = false
strict modes = false
hosts allow = *
log file = rsyncd.log
uid = 0 #不指定uid,不加该选项无法使用任何账户
gid = 0 #不指定gid
# Module definitions
# Remember cygwin naming conventions : c:\work becomes /cygwin/c/work
#[test]
path = /cygdrive/d #需要迁移d盘数据
read only = false
transfer logging = yes
auth users = rsync
secrets file = /cygdrive/f/dtstack-rsync/rsync.password
纯文本
创建存放校验用户名密码的文件:
#格式为用户名:密码
纯文本
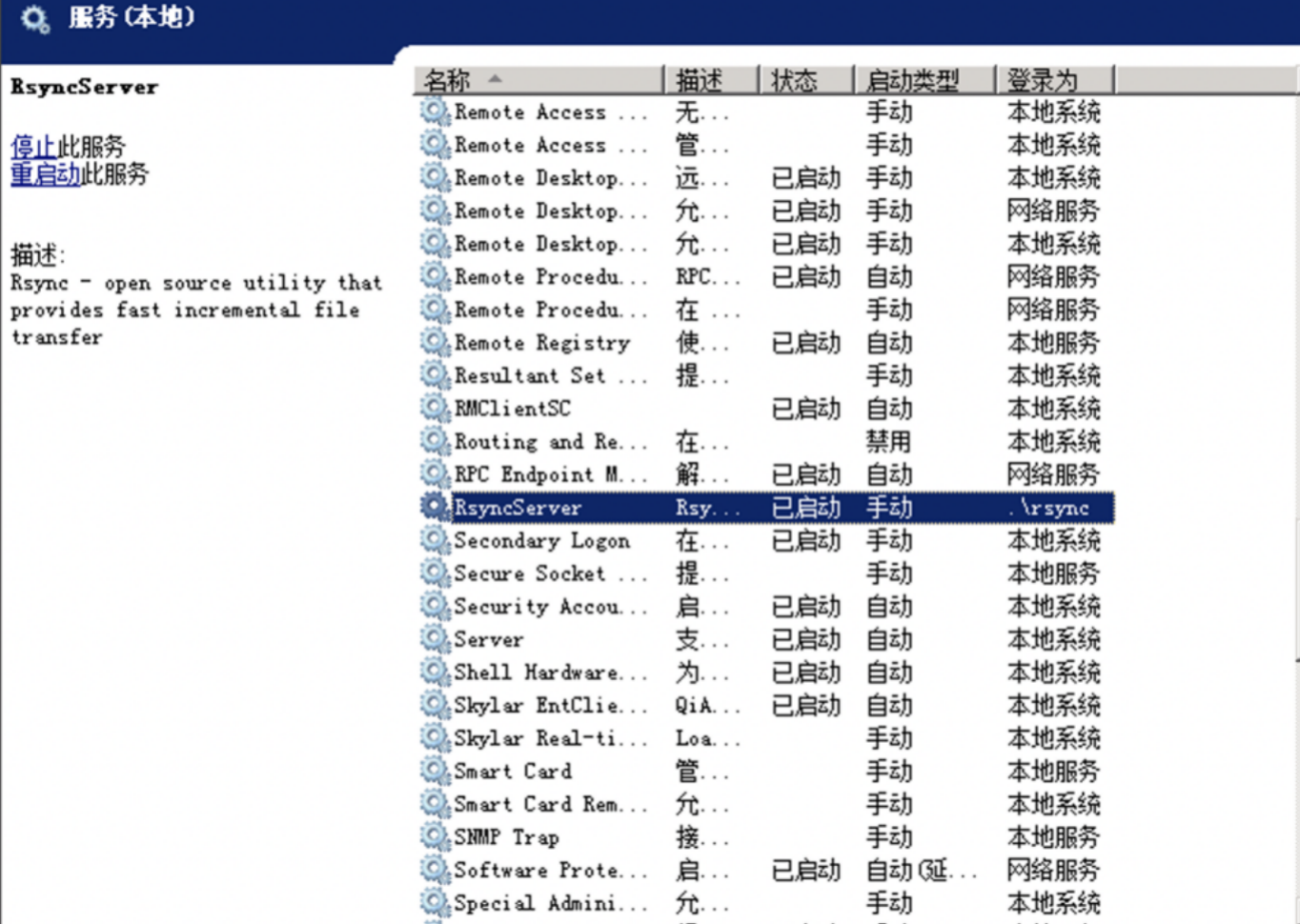
启动服务
客户端
下载并解压压缩包
📌建议客户端部署完成之后,先测试下到服务端873端口的链接情况
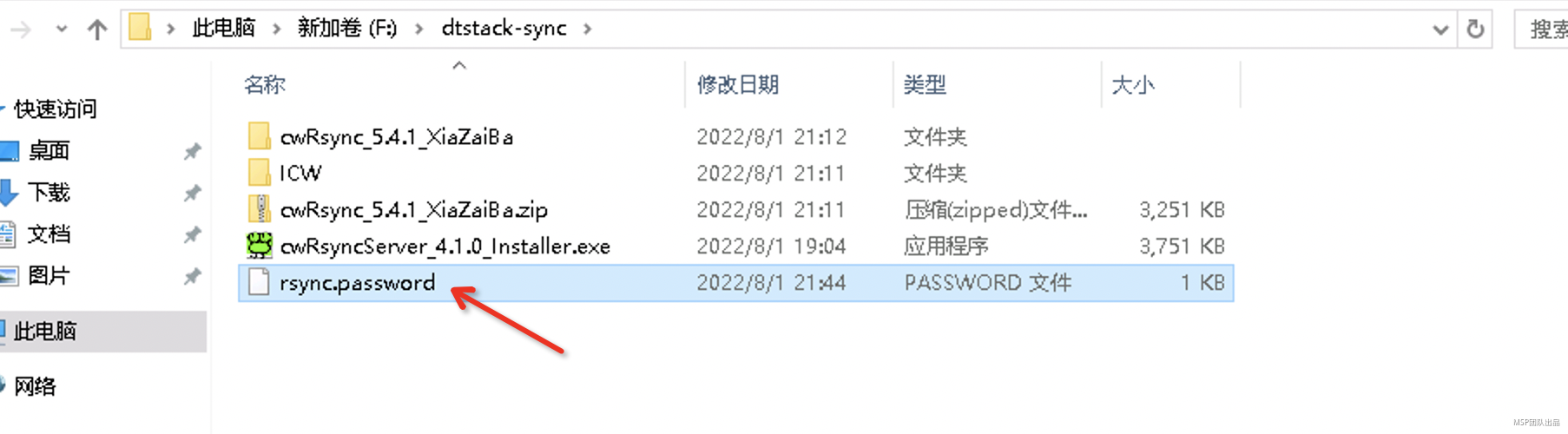
在客户端磁盘中创建一个rsync.password文件,文件中需要写入服务端同步用户密码
纯文本
在客户端启动同步命令:
📌这里注意,--password-file指定的路径中不能有空格,不然会造成命令解析错误的
rsync.exe --port=873 -vzrtopg --progress --password-file=/cygdrive/f/dtstack-sync/rsync.password rsync@ip地址::test /cygdrive/d
rsync:就是对应在服务端配置文件中指定的身份验证的用户名。
test:就是在服务端配置文件中指定的模块名称。/cygdrive/d:指定将服务端文件同步到客户端的目录,这里是直接将服务端的d盘同步到客户端所在服务器的d盘。--password-file 指明客户端的身份验证密码文件,跟服务端的那个密码文件是对应的。
纯文本