数仓主流架构简介之二
一、流批一体
数据批流一体是一种云计算架构模式,它结合了批处理和流处理的特点,以实现更高效、灵活和可扩展的数据处理能力。在这种模式下,数据可以同时进行批处理和流处理,以满足不同场景下的需求

流批一体:是指将流式处理和批处理统一在一个运行时框架中,进行一体化的处理。
1、实时数据流和历史数据批量处理可以使用同一组数据处理工具和技术,例如Apache Spark、Apache Flink等。流批一体架构可以将实时数据和历史数据进行统一的处理和分析,以简化数据处理的复杂性和提高数据处理的效率。
2、实时数据流和历史数据批量处理可以使用同一套数据处理代码。这意味着,数据处理人员可以使用同一种编程语言、框架和工具来处理实时数据和历史数据。这样可以减少数据处理人员的学习和使用成本,并提高数据处理的效率和精度。
3、实时数据和历史数据存储在同一套数据存储系统中,这样可以简化数据存储的管理和维护,并提高数据的可用性和可靠性。
综述:流批一体是一种将流数据处理和批数据处理整合在一起的数据处理架构,它可以简化数据处理的复杂性和提高数据处理的效率。流批一体架构可以在实时数据处理和历史数据批量处理之间实现无缝切换,以满足不同的数据处理需求。主要使用Spark,Flink等。
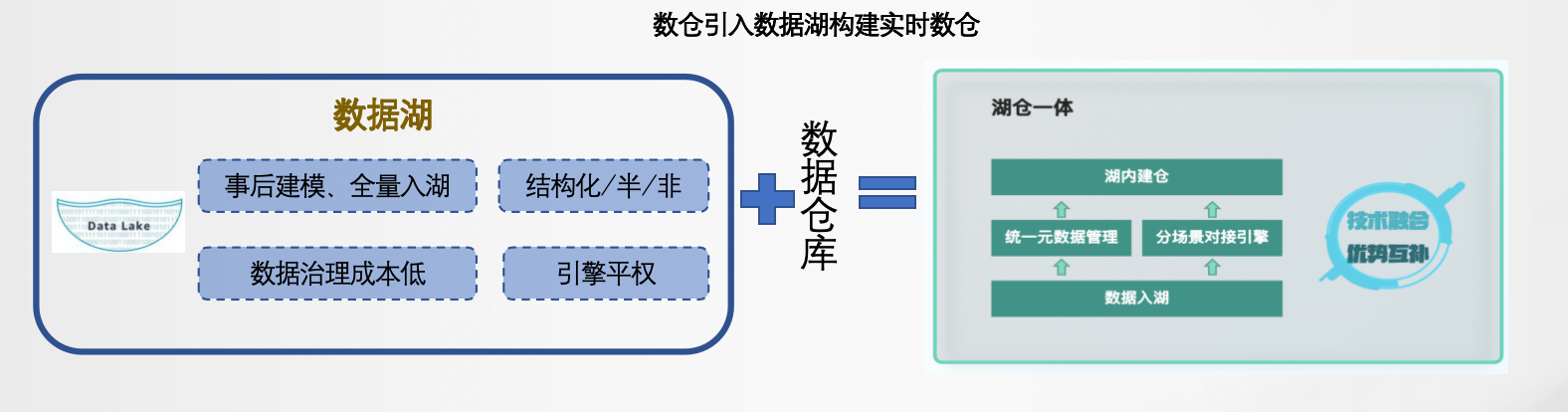
二、湖仓一体
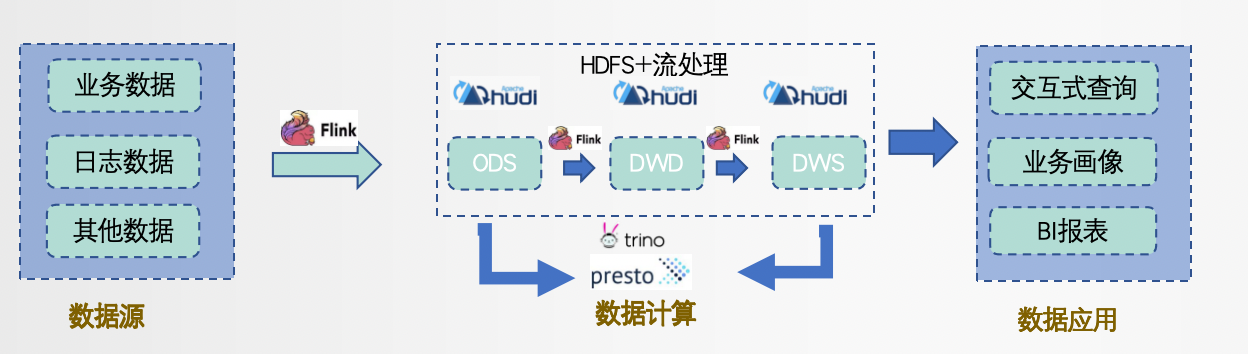
数据湖解决了Kappa架构痛点
利用存储替换Kappa架构中的消息队列,保证数据高效回溯能力。
支持读写分离,支持Streaming read,可以在系统的中间层做流批任务,把中间结果输出到下游,中间层支持 OLAP 分析。
支持SQL查询,支持添加、删除、更新数据。
统一元数据管理和数据生命周期管理。