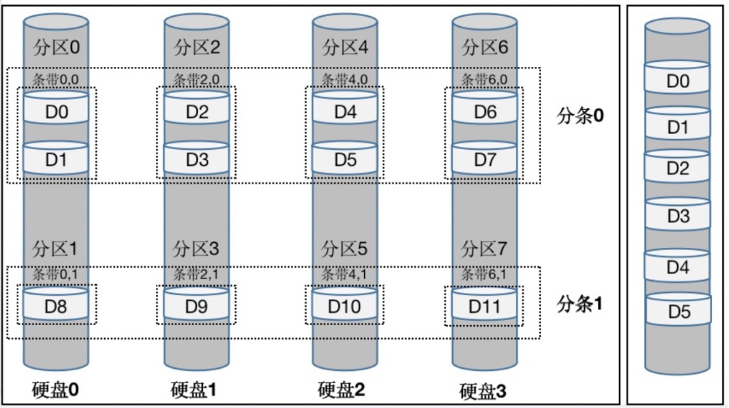
Kafka数据恢复
一、增量恢复
增量恢复需要使用 MirrorMaker 来实现,下面是 MirrorMaker 的用法示例:
# 创建MirrorMaker 配置文件
cat > /tmp/mirror-maker.properties <<EOF
consumer.bootstrap.servers=backup-host:9092
producer.bootstrap.servers=localhost:9092
EOF# 运行MirrorMaker
kafka-run-class.sh kafka.tools.MirrorMaker \--consumer.config
\ /tmp/mirror-maker.properties
\--producer.config /tmp/mirror-maker.properties \--whitelist $RESTORE_TOPIC
上述代码中创建一个 MirrorMaker 配置文件将备份端的数据同步到目标端 $RESTORE_TOPIC
主题中
注意:增量恢复会将备份端数据的变化同步到目标端,因此恢复时必须先将备份端数据同步完整
二、全量恢复
# 指定恢复的主题
RESTORE_TOPIC=test# 指定备份文件路径
BACKUP_FILE=/tmp/backup/$RESTORE_TOPIC.txt# 恢复主题数据
kafka-console-producer.sh \--broker-list localhost:9092 \--topic
$RESTORE_TOPIC \--new-producer \< $BACKUP_FILE
将$BACKUP_FILE 文件中的数据恢复到 $RESTORE_TOPIC 主题中
注意:该脚本也是同步操作,恢复时间较长时建议使用异步操作