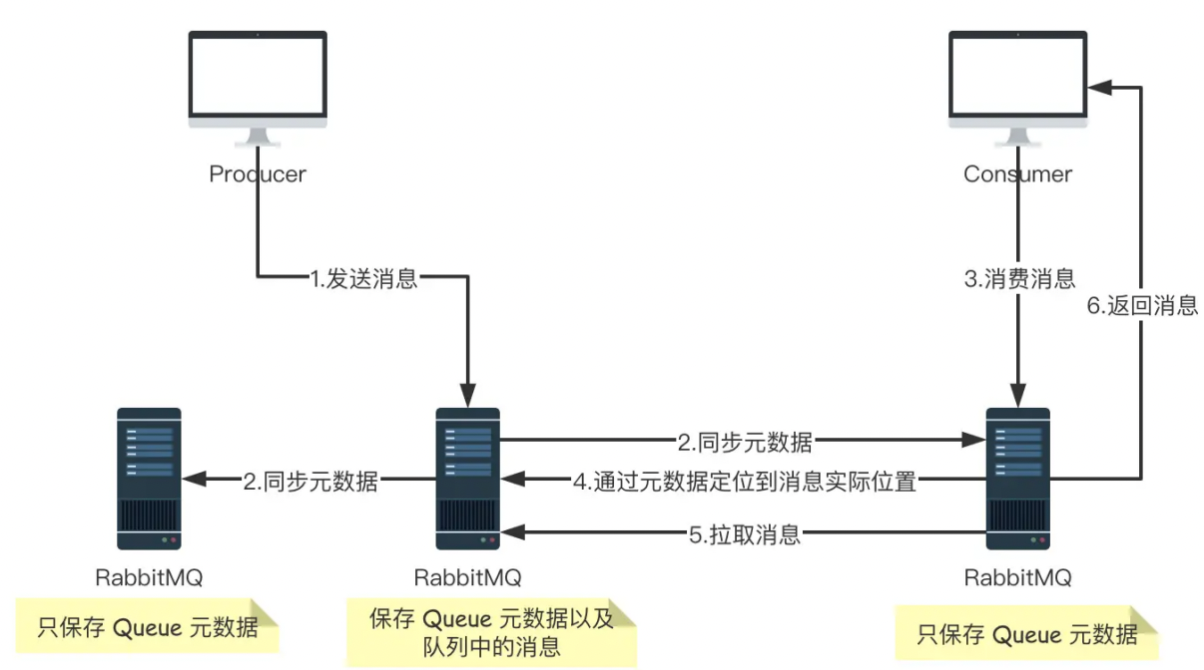
flink sql 批处理
进入flink sql命令行
sql-client.sh
Source 表
与所有 SQL 引擎一样,Flink 查询操作是在表上进行。与传统数据库不同,Flink 不在本地管理静态数据;相反,它的查询在外部表上连续运行。
Flink 数据处理流水线开始于 source 表。source 表产生在查询执行期间可以被操作的行;它们是查询时 FROM 子句中引用的表。这些表可能是 Kafka 的 topics,数据库,文件系统,或者任何其它 Flink 知道如何消费的系统。
可以通过 SQL 客户端或使用环境配置文件来定义表。SQL 客户端支持类似于传统 SQL 的 SQL DDL 命令。标准 SQL DDL 用于创建,修改,删除表。Flink 支持不同的连接器和格式相结合以定义表。
# Source表 -- hdfs source -- 将数据上传到hdfs hadoop dfs -mkdir -p /data/peoples hadoop dfs -put student.txt /data/peoples CREATE TABLE student ( id STRING, name STRING, age INT, gender STRING, clazz STRING ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/data/peoples', 'format' = 'csv' );
连续查询
虽然最初设计时没有考虑流语义,但 SQL 是用于构建连续数据流水线的强大工具。Flink SQL 与传统数据库查询的不同之处在于,Flink SQL 持续消费到达的行并对其结果进行更新。
一个连续查询永远不会终止,并会产生一个动态表作为结果。动态表是 Flink 中 Table API 和 SQL 对流数据支持的核心概念。连续流上的聚合需要在查询执行期间不断地存储聚合的结果。
select clazz,count(1) as c from student group by clazz;
Sink 表
当运行此查询时,SQL 客户端实时但是以只读方式提供输出。存储结果,作为报表或仪表板的数据来源,需要写到另一个表。这可以使用 INSERT INTO 语句来实现。本节中引用的表称为 sink 表。INSERT INTO 语句将作为一个独立查询被提交到 Flink 集群中。
# sink表(保存查询数据) -- hdfs sink CREATE TABLE clazz_num ( clazz STRING, c BIGINT ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/data/clazz_num', 'format' = 'csv' ); # 将连续查询的结果插入到sink表中 batch是输出最终的结果,streamg模式输出连续结果 -- 如果连续查询的返回的动态表是一个更新的表 -- 插入语句的返回的字段和类型和sink表一致 SET 'execution.runtime-mode' = 'batch'; 使用批处理模式写入hdfs insert into clazz_num select clazz,count(1) as c from student group by clazz; hadoop dfs -ls /data/clazz_num hadoop dfs -cat /data/clazz_num/*
提交后,它将运行并将结果直接存储到 sink 表中,而不是将结果加载到系统内存中。