MSP服务为客户交出满意答卷
运维背景
浙江创创鱼信息科技有限公司与我们MSP运维团队已合作了三年以上,随着创创鱼业务系统的稳步发展,业务规模和数据量持续增长,对IT运维体系和能力的要求也不断提高。
在MSP技术团队和创创鱼研发团队的紧密合作和共同努力下,我们在运维能力和流程管理上取得了显著进展,成功保障了创创鱼云上系统的平稳运行。
MSP服务目标
01
整体的IT规划,实现自动化,实现云原生
我们致力于帮助客户制定并实施全面的IT规划,确保其IT战略与业务需求紧密结合。具体措施包括:
自动化:通过引入和实施自动化工具和流程,减少手动操作,提高效率和准确性,实现无缝运维。
云原生:帮助客户实现向云原生架构的转型,充分利用云计算的弹性、可扩展性和高可用性,增强业务灵活性和创新能力。
02
提供专业的IT技能,延伸企业的IT能力
我们的专业团队为客户提供全面的IT支持,扩展其内部IT能力,确保其在竞争激烈的市场中保持技术领先。具体服务包括:
专业技能支持:提供专家级的技术支持和咨询服务,覆盖网络管理、网络安全、数据库管理、应用开发等多个领域。
技能培训:为客户的IT团队提供定期的技能培训和知识更新,提升其技术水平和问题解决能力,使其能够应对快速变化的技术环境。
03
持续优化成本
通过精细化的成本管理和优化策略,我们帮助客户有效控制和降低IT支出,实现资源的最佳利用。具体措施包括:
资源优化:通过全面的资源审计和优化,确保IT资源的高效利用,避免资源浪费。
成本管理:实施严谨的成本管理策略,优化IT采购和运营成本,确保每一笔IT支出都物有所值。
云成本优化:运用云成本管理工具和优化策略,帮助客户降低云服务费用,同时提升使用效率和效果。
MSP服务总结
在过去的一年中,我们的MSP运维团队为客户提供了卓越的服务,确保客户业务的稳定高效运行。以下是我们重点完成的事项总结:
01
专业团队配置
在整个运维服务周期内,我们为客户配备了3位专业的运维工程师,包括2名主力工程师和1名备份工程师,全天候为客户业务保驾护航。
02
服务领域覆盖
我们从多个关键方向展开工作,全面提升客户的IT环境:
服务性能优化:通过系统调优和资源管理,提升系统性能和响应速度。
成本优化:优化资源使用和成本管理,帮助客户有效降低IT支出。
运维效能提升:引入自动化运维工具和流程,显著提高运维效率和响应速度。
数据迁移:成功实施多次数据迁移,确保数据安全和业务连续性。
数据恢复:提供快速数据恢复服务,保障客户在数据丢失或损坏时的业务连续性。
数据备份:实施并管理可靠的数据备份策略,确保数据安全和可恢复性。
SQL优化:优化数据库查询和操作,提升数据库性能和稳定性。
03
重点案例成果展示
在过去一年中,我们累计完成了超过400+次的运维事件,涵盖了上述各个方向的具体工作内容,显著提升了客户的IT运营水平。
云资源成本优化
去年运维周期内协助客户完成若干次费用优化,已完成云资源降本20w+,具体如下:
在过去的一年中,我们通过一系列优化措施,帮助客户实现了显著的成本节约和性能提升。以下是几个具体案例:
ECS节点替换降本
阿里云发布实例规格大幅降价公告后,我们对客户现有实例规格进行了评估,确认了ECS成本优化方案。由于旧的k8s节点在不支持新规格的可用区,我们采购了新的节点并逐步替换。
服务配置优化降本
通过优化Java类微服务和Kafka服务配置,k8s集群负载大幅下降,节约了大量CPU资源。在确保资源健康的前提下,新增了约40个前后端应用,相当于节省了2台8C 64G配置的ECS服务器,实现了将近 2万元的成本节约。
审计日志调整降本
针对RDS数据库费用进行分析,发现审计占用较多费用。与客户运维团队沟通后,关闭了部分非必要的实例审计,服务周期内节省了20w+。优化前后费用对比如下:
优化前
优化后
服务性能优化
最近的Kafka版本升级后,虽然ECS资源使用率有所下降,但是我们注意到仍然存在负载过高、服务启动时间过长以及系统响应较慢等问题。经过深入排查和分析,我们发现了以下关键问题,并通过运维优化措施取得了显著的成效:
1)资源调度优化
首先,我们发现order服务和share-stock服务占用了大量的CPU资源。为了有效分散负载,我们通过k8s的反亲和性调度功能,将这两个服务分别调度到不同的k8s节点上。这一步骤显著降低了资源的集中使用,有效提升了系统的稳定性和性能。
2)心跳探针配置修正
进一步分析中,我们发现Java类微服务与kafka服务之间的心跳探针配置存在异常。原本配置的心跳间隔为7秒,但由于参数命名转换失误,实际生效的却是7毫秒,这导致了不必要的CPU资源浪费。针对这一问题,我们及时修正了配置,将心跳间隔调整为正确的7秒。此举大幅度降低了k8s集群的负载,并显著减少了CPU资源的消耗。
本次优化效果对比图如下:
通过以上优化措施,我们不仅有效解决了系统性能问题,还提升了服务的响应效率。这些措施不仅改善了用户体验,也展示了我们在运维管理和系统优化方面的专业能力和价值。
系统稳定性优化
1)问题诊断与定位
2)Bug修复过程
3)新问题发现与处理
K8S监控系统优化
1)技术选型与系统部署
2)数据集成与可视化展示
3)完善监控覆盖和应用
运维效能提升
1)手动计算扩容节点数优化
2)制作Excel模板自动化计算
3)编写脚本实现自动化扩容
4)提供详细的操作步骤和文档
数据库恢复演练
1)确定恢复类型和时间点
2)预演练和预检测
3)新实例开通和恢复操作
4)模拟灾难场景
5)业务验证和总结
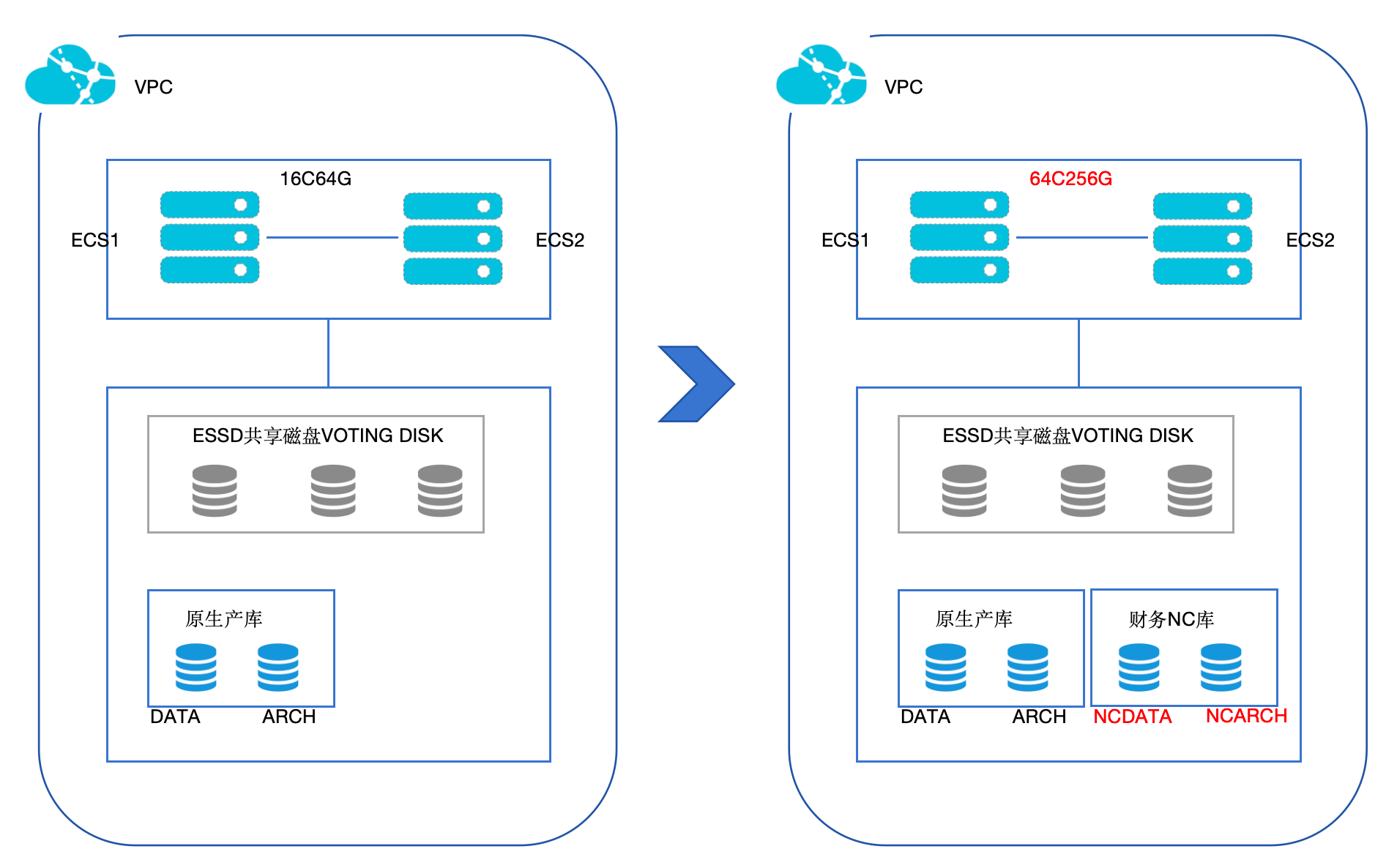
数据库异构迁移
1)需求分析与规划
2)全量数据迁移
3)自研开发脚本优化
为了进一步优化迁移效率和适应性,我们开发了自动化脚本。该脚本实现了以下功能:
对迁移的表名进行驼峰转换为下划线命名规范,提高了数据库结构的统一性和可读性。
修改表字段的默认值,将原先的
NOT NULL修改为NULL,符合目标数据库的设计和业务需求。
我们通过成功的数据库异构迁移案例,为客户的业务运作和数据管理提供了可靠的技术支持和保障,展示了我们在数据库迁移和自动化脚本开发方面的专业能力和创新优势。
来自客户的声音