案例分享|某医院数据上云性能优化
01
前言
之前在和小伙伴在做技术分享的时候,分享了他们做的某医院数据上云方案。该医院因为数据延迟问题,病人无法及时看到检验报告。
当时大致了解了一下这个案例的情况:客户的数据是存储在共享存储上面的,通过samba协议进行共享读写访问。且这个数据还要上传到云上进行读取,但因为有部分用户需要从公网拉取此数据,再加上IDC机房的存储设备有其存储量上限,按照国家规定,相关数据也要保留一定的年限,所以必须要进行数据上云备份和访问。
由于使用的是samba协议,我们平常所用的inotify+rsync的方式是无法实现的。他们之前试过直接采用rsync进行全量数据推送,但是由于数据量太大了,推送一次就需要12个小时左右,而这期间新增的文件可能会被遗漏,也就是说最大可能存在12个小时的数据延迟,这显然是无法接受的。后续也使用了Python、ossutil 进行了尝试,发现性能都无法满足客户要求(客户要求半个小时以内)。
最终选择使用golang进行数据上传后,发现数据延迟在10分钟以内,虽然我觉得延迟还是很大,但已经能满足客户的性能要求了。性能优化是无止境的,所以现阶段能满足要求就可以了。当时我也提出过是否可以加大并发,小伙伴反馈说是加大并发会导致应用崩溃。
02
发现问题
后面发现延迟问题并没有先前讲的那么简单,我之后经常会看到医院方反馈说数据延迟过大。这反映出里面的性能还是存在较大的问题的,实际上大概率并不能满足客户的要求。因此我们仔细地研究了一下看是否存在问题。经过了解可知:大致的架构图如图所示:
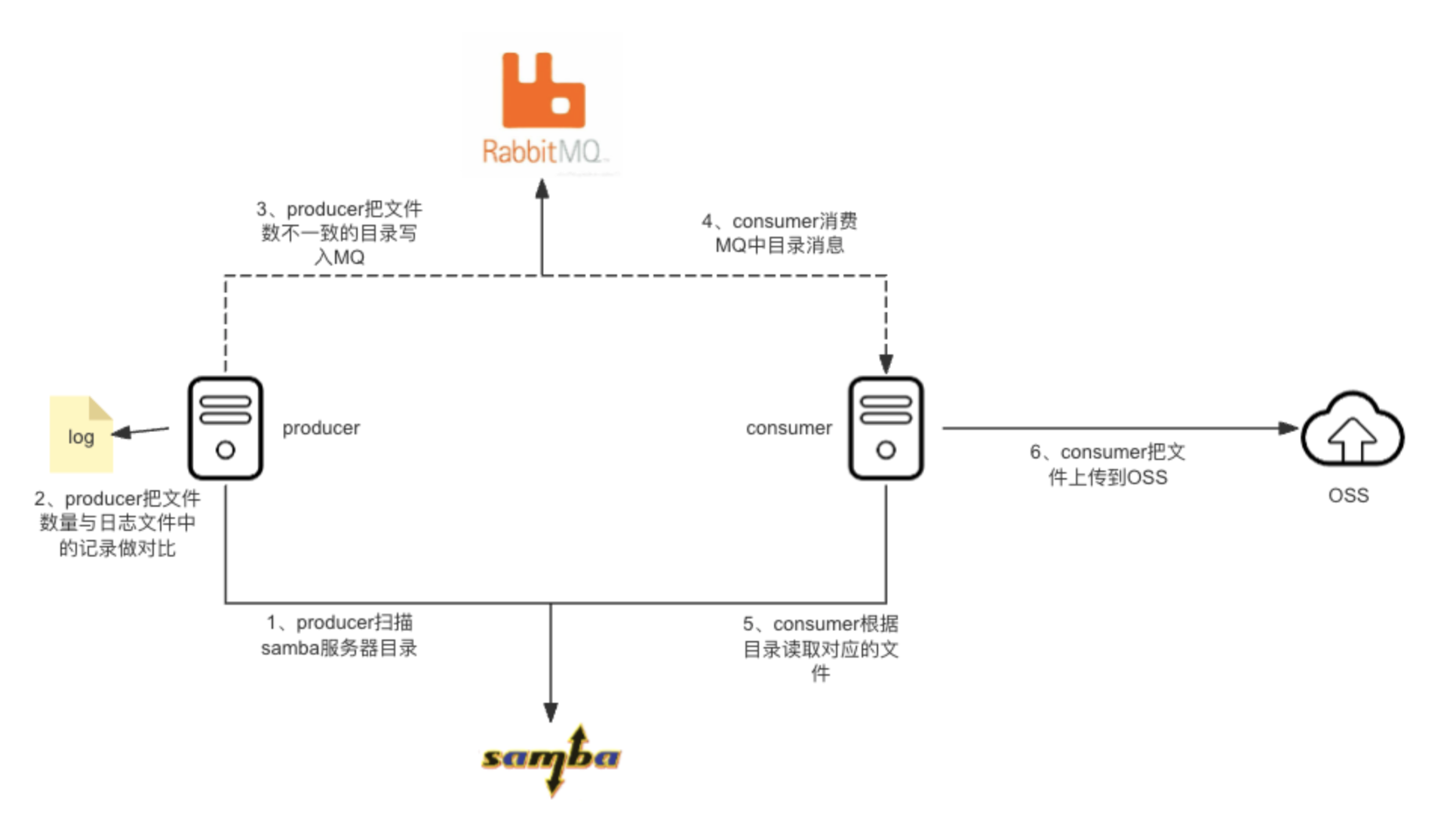
从上图可以看出,架构非常简单:producer和consumer都通过samba挂载存储服务器,producer通过crontab每5分钟去扫描一次samba存储,读取之后跟日志文件中的记录作比对,如果发现有目录下面的文件数量跟日志文件中记录的不一致,就会把目录发给rabbitmq,然后consumer从MQ中读取目录信息,把此目录进行一次数据同步到OSS。
这么看好像没有什么问题,通过producer和consumer把数据比对和数据上传进行了解耦。但经过分析后会发现:由于producer是读取的本地日志文件,存在单点问题,且单点代表着无法随便扩充producer的节点数量。
03
尝试优化 :优化samba挂载参数
通过了解情况之后,出于运维工程师的习惯,我们还是希望经过简单的调整,就能达到客户的性能要求,所以我们没有针对上面发现的问题进行优化。相较于上面需要修改源码的方式,我们直接优化samba协议会更简单。既然要优化samba协议,我们需要看一下samba挂载的参数是什么样子的,如下所示:
//192.168.10.20 on /mnt/source/test type cifs (rw,relatime,cache=struct,uid=0,noforceuid,gid=0,noforcegid,addr=192.168.10.20,file_mode=0755,dir_mode=0755,soft,nounix,serverino,mapposix,rsize=1048576,wsize=1048576,echo_interval=60,actimeo=1)
我们的producer和consumer都是CentOS7,在查阅了很多资料之后,我们发现有很多资料反馈说:CentOS7在挂载的时候,如果不声明samba的协议版本,默认采用的是samba 1.0,而samba1.0协议存在很大的性能问题。根据资料,我们尝试把挂载参数加上 vers=3.0,强制让samba协议走3.0 。这里就算是默认挂载的是3.0,当然我们再显式声明一下也没问题。
没必要去猜挂载的协议到底是不是3.0,由于数据量比较大,我们没有采取抓包分析的方式,如果进行抓包分析,肯定可以分析出采用协议的版本。通过测试发现修改之后,确实存在性能提升,效果如下图所示:
左边是优化前的时间,右边是优化后的时间,性能提升了1倍左右。这个结果是我们经过多次测试得到的,结果都相同。于是我们就把优化参数进行了配置。
04
再次优化 :优化代码并发度
如果到这里就完成了优化的话,这个事情是不会成为一个案例的。后续再次出现了问题。负责客户的小伙伴反馈:优化之后,问题并没有解决,反而更加严重了。对此情况,我们并没有感到慌张,而是第一时间凭借运维工程师的本能去思考解决问题的办法。经过排查我们发现,大量的消息堆积在rabbitmq,说明或许是consumer存在性能问题。我们跟小伙伴沟通了一下,得知这个之前是做的consumer并发,每次取20条消息进行消费,然后并发进行消费,消费完之后,rabbitmq会再发送新的消息过来消费的。代码如下(代码有删减):
func Consumer(cfgInfo map[string]string) {// 创建RabbitMQ连接conn, connErr := tools.RabbitMQConn()// 关闭RabbitMQ连接defer conn.Close()// 获取并发数concurrentNum, _ := strconv.Atoi(cfgInfo["concurrent"])for qname, v := range queues {mainWg.Add(1)go func(queueName string) {defer mainWg.Done()// 创建通道chann, channErr := tools.CreateChann(conn)chann.Qos(concurrentNum, 0, false)// 关闭通道defer chann.Close()// 创建队列que, queueErr := tools.CreateQueue(chann, queueName)// 定义一个消费者msgs, comErr := chann.Consume(que.Name, // queue"", // consumerfalse, // auto-ackfalse, // exclusivefalse, // no-localfalse, // no-waitnil, // args)go func() {// 并发消费文件for d := range msgs {msg := string(d.Body)localfile := v["sourcePath"] + msgalyunfile := v["targetPath"] + msg + "/"ossutilErr := PushDir(localfile, alyunfile)if ossutilErr == nil {consumerLogger.Info("Successfully ossutil sync file: " + msg)consumerLogger.Info(string(out))} else {consumerLogger.Fatal("Failed ossutil sync file!")}d.Ack(false)}}()// 等待select {}}(qname)}mainWg.Wait()}
这个大致一看也没有什么问题,但是我们仔细读了代码后发现,在最后// 并发消费文件那一行的上面,只使用了一个goroutine来进行执行,而下面是一个for循环,简单点说就是:只采用一个协程,按照顺序进行上传操作。意思是实际上并没有并发去消费运行。
根据这个我们尝试进行了修复,修复代码如下所示:
for d := range msgs {mainWg.Add(1)go func(d amqp.Delivery) {defer mainWg.Done()msg := string(d.Body)localfile := v["sourcePath"] + msgalyunfile := v["targetPath"] + msg + "/"ossutilErr := PushDir(localfile, alyunfile)if ossutilErr == nil {consumerLogger.Infof("Successfully ossutil sync dir: %s\n", msg)} else {consumerLogger.Fatalf("Failed ossutil sync dir %s, ERROR: %s\n", msg, ossutilErr)}if err := d.Ack(false); err != nil {consumerLogger.Fatalf("Failed rabbitmq ack! ERROR:%v\n", err)} else {consumerLogger.Info("Successfully rabbitmq Ack message: " + msg)}}(d)}
我们做的就是通过for循环取出rabbitmq消息之后,把消息传递给匿名函数,再使用协程去并发执行PushDir函数。经过测试,发现性能得到了进一步的提升,可以看到rabbitmq上面已经没有消息堆积了。
05
三次优化 :优化日志时间分隔和应用单点问题
上面提到优化过consumer之后,rabbitmq已经不存在消息堆积了,但小伙伴收到医院反馈说文件延迟还是很大,超出了客户能接受的范围。
我们得知这个消息的时候,第一反应是觉得rabbitmq已经不存在堆积了,按理来说不会还出现这种问题,不应该存在这么大的延迟。如果还存在这么大的延迟,那只能说明是producer存在问题,因为producer根本就没有推送消息到rabbitmq,所以导致文件同步存在很大的延迟。
我们查看了相关日志,发现producer之前的日志根本就没有明显输出比对结束的时间点,而我们是根据日志开始的时间间隔,去计算整个过程的时间。由于我们一次是运行了最近3天的任务,这3天的日志都打印在一个日志文件内,所以根本就无法区分是不是一个任务的开始和结束。
这种情况下,我第一时间做的是:把producer的日志进行了拆分,不同的任务输出到不同的文件,并加上明确的任务开始和结束时间。经过拆分之后我们发现,实际上任务在高峰期,运行超过2个小时,甚至能到4个小时,与客户要求的半个小时相差甚远。我们查看了producer的代码,发现对consumer的优化同样也也适用于producer。我们把producer改成并发的之后,在开始时,性能飙升,直接提升到了1分钟左右。这个效果说明我们优化还是很成功的。
但没想到没过多久,问题再次发生。这次是客户反馈说很多文件都延迟非常大,于是我们查了一下发现数据确实是没有同步到云上。经过排查,我发现应用竟然在执行的过程中报空指针异常退出了。异常日志如下:
./gosync -r producer -t 20240108panic: runtime error: invalid memory address or nil pointer dereference[signal SIGSEGV: segmentation violation code=0x1 addr=0x1 pc=0x5fcba1]goroutine 2403 [running]:gopkg.in/ini%2ev1.(*File).SectionsByName(0x0, {0x0?, 0xc000020d00?})/Users/edy/go/pkg/mod/gopkg.in/ini.v1@v1.67.0/file.go:156 +0x61gopkg.in/ini%2ev1.(*File).GetSection(...)/Users/edy/go/pkg/mod/gopkg.in/ini.v1@v1.67.0/file.go:137gopkg.in/ini%2ev1.(*File).Section(0xc00270cd20?, {0x0, 0x0})/Users/edy/go/pkg/mod/gopkg.in/ini.v1@v1.67.0/file.go:175 +0x26gosync/rabbitmq.recursiveDir.func1({0x6ec978, 0xc00018ad40}, 0x0?)/Users/edy/gosync/rabbitmq/producer.go:90 +0x234created by gosync/rabbitmq.recursiveDir in goroutine 6/Users/edy/gosync/rabbitmq/producer.go:80 +0x28e
还记得我们刚开始优化的时候,说过架构不合理的事情吗?producer由于是写信息到本地的日志文件,因此会导致producer存在单点故障。而这里的报错又指向了写信息的那个模块,具体代码如下:
for _, dir := range dirs {files, getfileErr := ioutil.ReadDir(classsdir + dir.Name())if getfileErr == nil {producerLogger.Info("Obtaining a File success!")} else {producerLogger.Fatal("Obtaining a File failed!")}// d := strings.TrimLeft(classsdir+dir.Name(), sourcePath)d := (classsdir + dir.Name())[len(sourcePath):]// 判断是否同步目录: 不存在、有增量则进行同步if cfg.Section("").HasKey(d) {val := cfg.Section("").Key(d).String()nums, _ := strconv.Atoi(val)if nums < len(files) {cfg.Section("").Key(d).SetValue(strconv.Itoa(len(files)))cfg.SaveTo(syncfile)producerFiles(producerLogger, d, ch, q, bucket)}} else {cfg.Section("").Key(d).SetValue("0")cfg.SaveTo(syncfile)producerFiles(producerLogger, d, ch, q, bucket)}}
我猜测是由于写入文件的时候,没有做并发控制,多个协程写入引发了空指针问题。既然是这里存在问题,我们的数据实际上是key/value数据,目录名是唯一的(key),目录下面的文件数量是value。既然是key/value类型,那我们应该使用Redis 来存放这些数据。本身应用就存在单点问题,引入Redis之后,可以解决此问题,只不过单点变成了Redis。相比于我们的应用作为单点,我更相信Redis的稳定性。就像木桶原理,引入Redis之后,只会把我们的其他木板的高度提升,Redis本身的质量也不会使其成为短板。改变之后的架构如图所示:
经过这样优化,我们观察后发现,应用没有再出现过空指针,也没有再出现过缺失目录和文件的问题。不过在优化这块代码的时候,我们发现读取底层存储的文件数量是使用的 ioutil.ReadDir()。我们查询了此模块的此方法,发现此模块存在性能问题,而在我们只是获取文件数量的场景下,go更推荐使用os.ReadDir(),所以我们这里更换为os.ReadDir(),最终优化后代码如下:
for _, dir := range dirs {wg.Add(1)go func(dir os.DirEntry) {defer wg.Done()localDir := classsdir + dir.Name()files, getfileErr := os.ReadDir(localDir)if getfileErr != nil {producerLogger.Fatalf("Obtaining a File failed! dirname: %s, ERROR: %s\n", dir.Name(), getfileErr)}localFileSum := len(files)// 去掉前面的统一的本地路径,保留只上云的路径,把此路径推送到MQ队列d := (classsdir + dir.Name())[len(sourcePath):]// 判断是否同步目录: 不存在、有增量则进行同步exists, err := cli.Exists(ctx, d).Result()if err != nil {producerLogger.Fatalf("redis: Exists failed! ERROR: %s", err)}// 判断redis 中key是否存在,返回值为0则不存在,不存在立即把目录发送到MQ,并设置keyif exists == 0 {err := ProducerFiles(producerLogger, d, ch, q)if err != nil {producerLogger.Fatalf("rabbitMQ: send key failed! ERROR:%s", err)return}err = cli.Set(ctx, d, localFileSum, 0).Err()if err != nil {producerLogger.Fatalf("redis: set key failed! ERROR:%s", err)return}}// 查询redis 中key 的值,跟本地目录下的文件数做对比,如果本地大则发布MQ消息val, err := cli.Get(ctx, d).Result()if err != nil {producerLogger.Fatalf("redis: get key failed! ERROR:%s", err)}num, err := strconv.Atoi(val)if err != nil {producerLogger.Fatalf("redis: key to int failed! ERROR:%s", err)}if localFileSum > num {err := ProducerFiles(producerLogger, d, ch, q)if err != nil {producerLogger.Fatalf("rabbitMQ: send key failed! ERROR:%s", err)return}err = cli.Set(ctx, d, localFileSum, 0).Err()if err != nil {producerLogger.Fatalf("redis: set key failed! ERROR:%s", err)}}}(dir)}
06
四次优化 :优化网络链路带宽限制问题
没想到还没过多久,又出现了问题。我们发现有的时候,MQ会出现大量的消息堆积。经过排查确认是consumer的网络带宽存在问题,带宽不稳定,有时候可以达到100Mb/s左右,有时候却只有10Mb/s。注意这里是bit,如果换算成我们常见的字节(要除以8),那就更低了。和小伙伴确认发现网络架构是:samba服务器经过专线到 producer和 consumer ,然后producer和consumer再通过专线到云上。这两条专线都是 1Gb的,但是实际上有时候远远达不到1Gb,而我们又很难推动排查专线的问题。
这个时候小伙伴反馈说:客户的IDC机房实际上有一条直接到云上的专线,我们在客户的IDC机房也有2台consumer的。但是由于登录比较困难,需要层层验证。再加上我们稍微一加大并发,那两台服务器就会崩溃,所以我们没有再使用那两台服务器了。而现在这条链路存在性能问题,我们可以尝试使用那两台服务器。我们尝试之后发现,IDC机房的那两台服务器,单台网络带宽可以达到 600Mb/s,于是我们顺利避开了之前网络链路中带宽的限制。目前的架构如下图所示:
07
五次优化:优化linux文件句柄参数问题
使用上面的架构运行了几天,没想到问题又出现了。在文章最开始我们就提到过,直接加大consumer的并发数,当时小伙伴给的回复是应用会崩溃。机房内的consumer在高性能运行了一段时间之后,出现了失联的问题。我们也无法通过ssh协议进行登录,刚开始我们也很疑惑问题出现的原因。我们让客户帮忙重启服务器之后,经过排查,我们定位到是由于linux的文件句柄参数没有进行优化(默认是1024),我们的应用打开超过1024的限制,最终导致了服务器失联。
经过我们反复的测试,最终我们把文件句柄配置为:1000000。如下图所示:
08
模块补充优化:优化Check模块
经过我们五次优化之后,基本上不会有大问题出现了。不过我们的架构是查询Redis中的key/value跟samba中存在的文件数做对比,实际上我们要的是 samba中的数据跟OSS中的数据一致。我们之所以采用这种方式是因为直接查询OSS也会产生相对应API调用费用,而查询Redis可以节省这块的费用。但是万一Redis的数据跟samba的是一致的,而samba跟OSS的数据不一致呢?那么我们就会出现数据丢失的问题。
基于以上考虑,我们还需要补充一个Check模块,用来直接比对samba的数据和OSS的数据,用来消除Redis和OSS数据不一致的这种可能性,而且客户每隔一段时间也要进行全量对比,刚好我们也可以使用Check模块来进行。如下图所示:
其实之前也有这个操作,当时我们小伙伴是采用Python来处理的,每次全量对比需要运行一个多月。我们在编写Check模块的时候,还碰到了需要限制goroutine数量的问题。由于全量运行的时候数据量太大了,如果不限制goroutine的数量,会导致服务器卡死或者应用异常退出。
这里参考了雅泽大佬给的建议,我们使用带缓冲的channel来进行goroutine限制。我们优化完Check模块之后,每次全量Check比对只需要2天左右,效率提升了15倍至20倍。
09
总结
我们刚开始接触这块的时候,简单地以为只是代码中可能存在一些bug,我们只需要简单地调优之后,就可以使其高效运行。当时的目标是平稳运行几个月都不会有客户来找我们。没想到我们优化了samba协议挂载参数、consumer并发上传、producer并发比对(基于Redis)、专线带宽问题、linux文件句柄上限、Check模块goroutine限制等等诸多问题点,才基本满足了客户性能要求。
目前producer模块仅仅需要1分钟左右,而且是多节点高可用架构。consumer也能在5分钟以内把数据上传到OSS。Check模块全量运行的情况下也仅需要2天时间。
优化效果如下图所示:
没想到一个小小的工具竟然暗含这么多优化点,充分说明了细节决定成败。现在优化过的应用工具已经正常平稳运行了几个月了,客户再也没有因为这方面的问题来找过我们。
经过多年工作我发现:一个好的运维工程师,也会是一个好的开发工程师(如果你懂开发的话),反之亦然。希望大家都能抱着一颗纯粹的学徒心态,在技术的道路上越走越远。