Redis 主从同步
前言
在分布式系统中为了解决单点问题,通常会把数据复制到多个副本部署到其它机器,满足故障恢复和负载均衡需求。Redis 也提供了复制功能,实现相同数据多个 Redis 副本。本篇文章介绍如何配置 Redis 复制及原理。
1. 复制配置
ip | 端口 | 角色 |
172.16.104.55 | 6379 | Master |
172.16.104.56 | 6379 | Slave |
Redis 复制配置有三种方法:
1.1 写入配置文件
写入 slave 节点配置文件中,随 Redis 启动时生效:
slaveof 172.16.104.55 6379
1.2 使用命令配置
127.0.0.1:6379> slaveof 172.16.104.55 6379 OK 127.0.0.1:6379> info replication # Replication role:slave master_host:172.16.104.55 master_port:6379 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:238 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:5d8a5460b775393de4e34aad453d846be82337d7 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:238 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:225 repl_backlog_histlen:14 127.0.0.1:6379>
1.3 Redis 启动命令配置
redis-server /usr/local/redis/redis.conf --slaveof 172.16.104.55 6379 --port 6379 --logfile /usr/local/redis/redis.log --daemonize yes
1.4 配置安全认证
上方配置过程没有任何的密码验证,对于数据比较重要的 主节点 可以配置 requirepass 密码认证参数,从节点的 masterauth 需与主节点 requirepass 密码一致,否则无法建立复制关系。
1.5 查询复制状态
复制状态可以通过 info replication来查询,Master-Slave 端都可以执行:
# Slave 127.0.0.1:6379> info replication # Replication role:slave master_host:172.16.104.55 master_port:6379 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:238 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:5d8a5460b775393de4e34aad453d846be82337d7 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:238 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:225 repl_backlog_histlen:14 # Master 127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=172.16.104.56,port=6379,state=online,offset=2296,lag=1 master_replid:5d8a5460b775393de4e34aad453d846be82337d7 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2296 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2296
1.6 断开复制
在从节点使用👇命令即可断开复制,从节点断开复制后并不会抛弃原有的数据,只是无法再获取主节点上的变化。
slaveof no one
1.7 只读模式
复制关系建立后,避免数据不一致,备库默认被调整为只读状态。
127.0.0.1:6379> set v 66 (error) READONLY You can't write against a read only replica.
从节点只读模式由下方参数控制👇 为避免数据不一致,生产环境不建议修改 Slave 的只读模式。
127.0.0.1:6379> config get slave-read-only 1) "slave-read-only" 2) "yes"
2. 主从同步原理
2.1 全量复制
启动多个 Redis 实例后,可以通过 replicaof 命令(Redis 5.0 之前使用 slaveof)配置主从关系,之后会进行如下步骤:
1)保存主节点信息
2)主从建立连接
3)发送 ping 命令
4)权限验证
5)同步全量数据集
主库会执行 bgsave 命令生产 RDB 文件,然后传输给备库,备库会先清空数据,然后加载主库的 RDB 文件。在此期间主库不会堵塞,会将收到的命令写入 replication buffer 当 RDB 加载完成后,会发送给从库执行。
6)持续复制
完成 “同步数据集” 步骤后,Redis 主从间会维护一个长连接来实现增量命令的传输。
2.2 增量复制
主从第一次同步步骤中,在持续复制过程中,如果出现网络闪断,那么主从间无法进行命令传播。
增量复制就是用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
在 Redis 2.8 之前第版本,如果出现网络闪断,主从会重新进行一次同步全量数据集,开销非常大。
在 Redis 2.8 开始,如果出现网络闪断,主从会采用增量复制的方式继续同步。
增量复制是对老版本复制功能重大优化,如果使用复制功能,尽量使用 2.8 以上版本。
2.2.1 增量复制原理
主节点在执行完命令后,会将命令字节长度做累加记录,通过 info replication 命令中的 master_repl_offset 查看这个偏移量。
从节点在接收到主库发送到命令后,也会累加自身的偏移量,通过 info replication 命令中的 slave_repl_offset 查看该偏移量。
从节点每秒会上报自身的偏移量给主节点,因此主节点也可以查看从节点的偏移量信息:
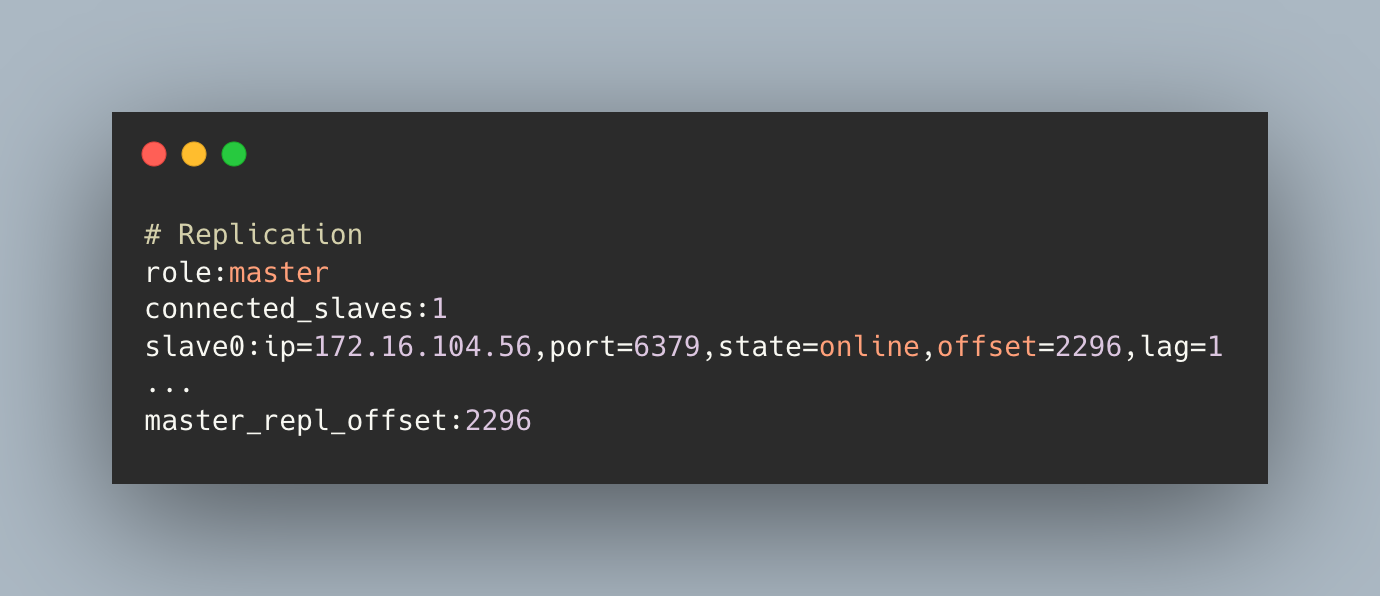
通过对比两者的偏移量可判断主从节点数据是否一致。
当出现网络闪断,网络断连期间,主库可能会收到新的写操作命令。主从节点连接恢复后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。
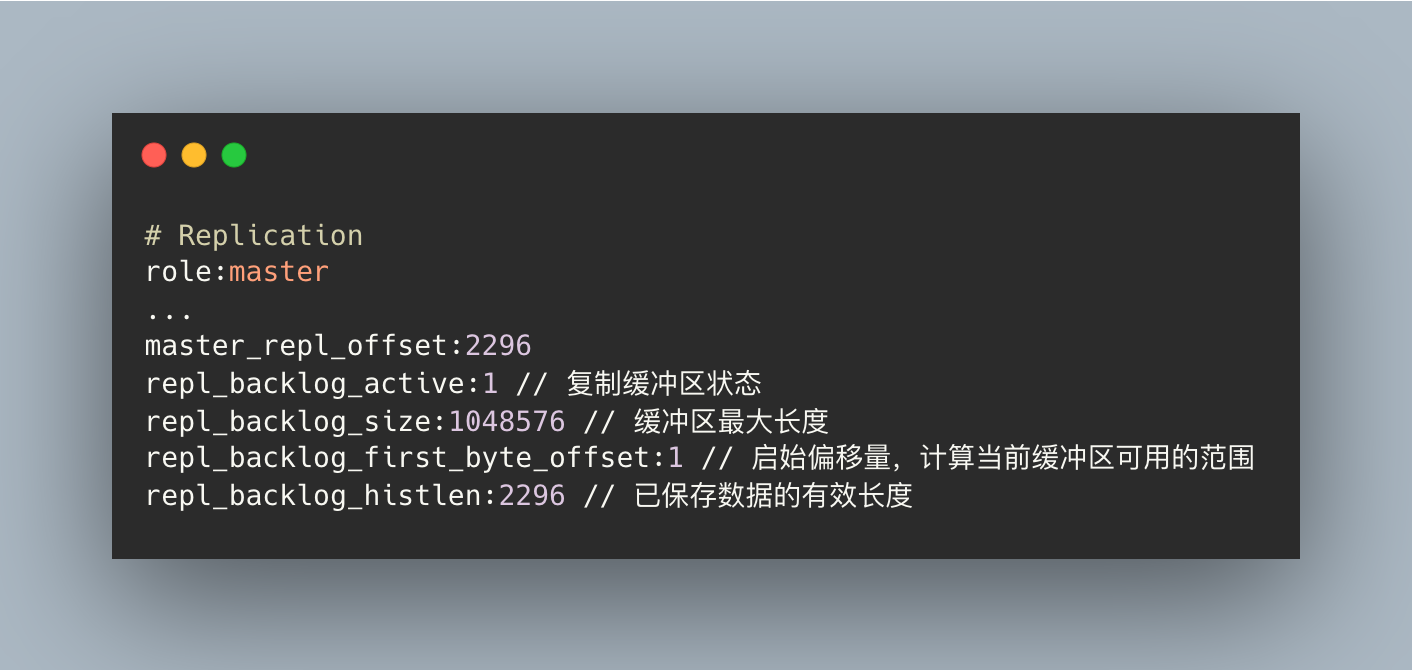
期间的增量命令主库是存储在主库 repl_backlog_buffer 中,它一个环形缓冲区。所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。
建议将 repl_backlog_size 设置为 2MB~4MB。
总结
本篇文章介绍如何配置 Redis 复制及原理,复制的全量阶段会消耗大量的资源占用网络带宽,因此建议一个 Redis 实例内存不要太大,通常建议不要超过 6GB。可以减少 RDB 文件生成、传输、重新加载的开销。