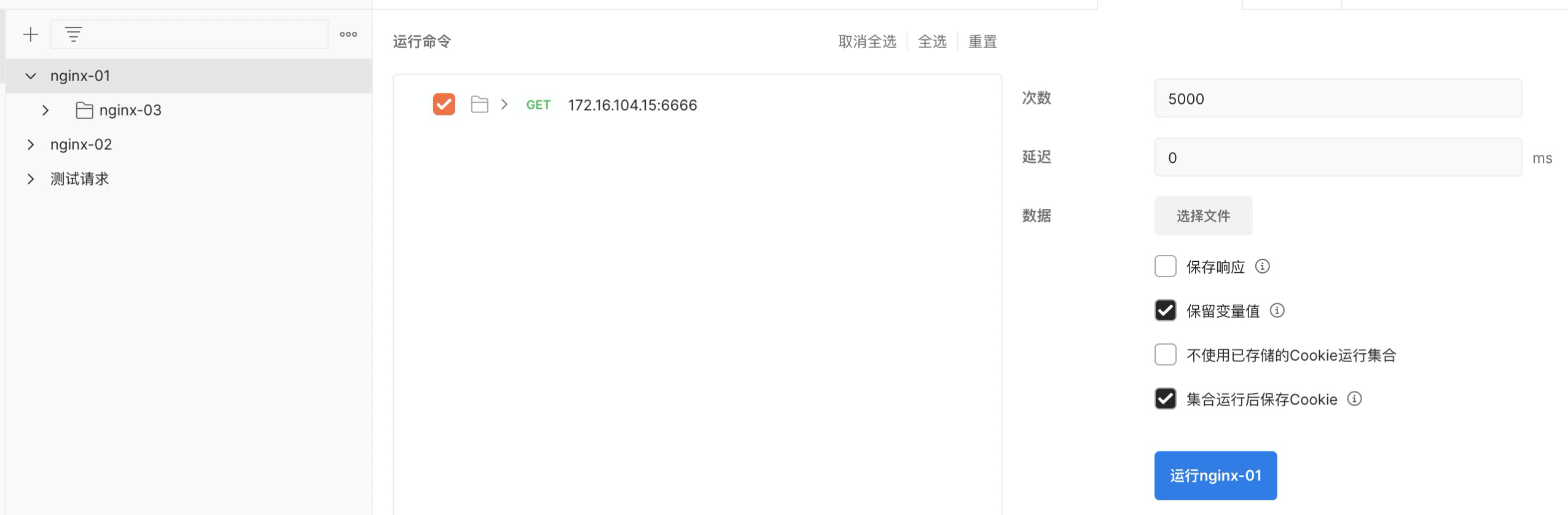
ES模糊查询(Wildcard Query)导致CPU打满问题
一、概述
Wildcard Query是es中实现模糊查询的一种方式,尤其对有SQL经验的人,会常常习惯于它,毕竟这是和SQL里like操作最相似的查询方式,最近一个客户的es集群就在这上面踩了个坑。。。
二、问题处理过程
a、问题现象
阿里云es集群三个节点cpu突然打高(100%),持续半小时,且自动恢复时间后,集群三个节点cpu再次打高(100%),期间通过监控可以看到集群qps并未有增强,且集群本身数据量较少,真正的生产索引就一个,5个主分片,2备份,总共87.6G左右。暂且不表,先上图:
阿里云监控信息显示cpu打高,期间qps已无记录(应该是集群已崩),前后qps变化不大
[MISSING IMAGE: , ]
kibana监控显示与阿里云监控显示基本一致:
[MISSING IMAGE: , ]
b、问题定位分析
这种情况一般肯定先看集群存在的热点线程啦(GET _nodes/hot_threads),果然看到有几个cpu占用较高的任务,见图如下:
[MISSING IMAGE: , ]
几个热点线程都是一样的,search任务,且是WildcardQuery任务。直接查下search任务(GET _tasks?actions=*search&detailed),果然看到了‘异常’的WildcardQuery任务,见图如下:
[MISSING IMAGE: , ]
这样结论就比较明显了,罪魁祸首就是就是集群里出现了这种大字段的模糊匹配的查询,有人直接把一篇文章输入到了搜索框里了!!!
c、问题处理
知道原因了,处理就比较简单了,让开发对搜索框查询的字段长度做了限制,目前未再出现上述情况。
三、深度探究
笔者后来又在自己的测试环境上就行了复现,发现即使在一个很小的索引上进行此类查询,即使返回为空也需要几秒甚至几十秒,并且占用cpu较高。查了一堆资料,听的云里雾里,大概总结就是:es在进行search时会对输入的查询字段进行解析,不管这个解析怎么优化,也总是会涉及拆分词组,那么这个查询字段越大,尤其是开头有*这种匹配时,会极大的增加这个拆分的结果集,且在匹配时又是一番大结果集匹配,这就导致少量的类似查询就会打满集群cpu。更详细的解说可以参考下面大佬的文章:https://elasticsearch.cn/article/171