Flink 运行架构简介
一、Flink简介
Apache Flink 是一个开源的分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。它具备强一致性的计算能力、大规模的扩展性,整体性能非常卓越,同时支持SQL、Java、Python等多语言,拥有丰富的API接口方便各种场景业务使用。目前在国内外互联网企业中Flink已经成为主流的实时大数据计算技术,是实时计算领域的事实技术标准。
1、Flink能解决什么
流数据更真实地反映了我们的生活方式
(1)传统的数据架构是基于有限数据集做处理
(2)随着业务量攀升,现在需要达到的目标是:低延迟、高吞吐、结果的准确性和良好的容错性
2、那些行业在使用Flink
移动媒体、生活服务、游戏、金融、在线教育、物流、在线交易、IT企业等,几乎大数据整个行业为了满足现有低延时高吞吐等目标都在使用Flink
3、传统数据处理架构
(1)事务处理
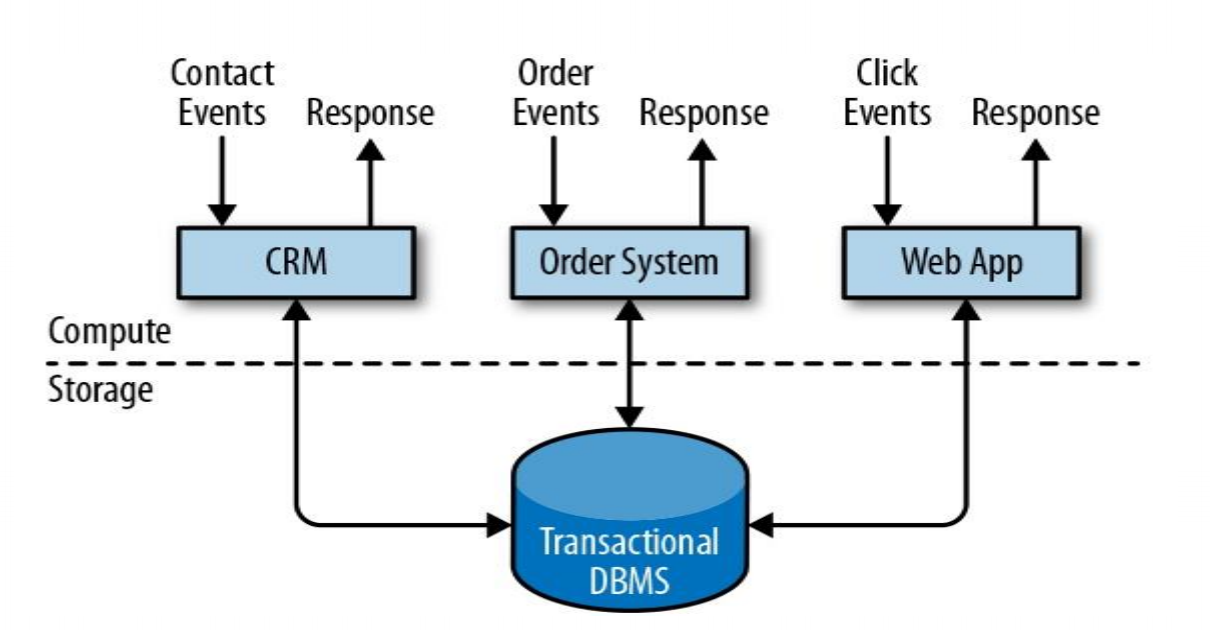
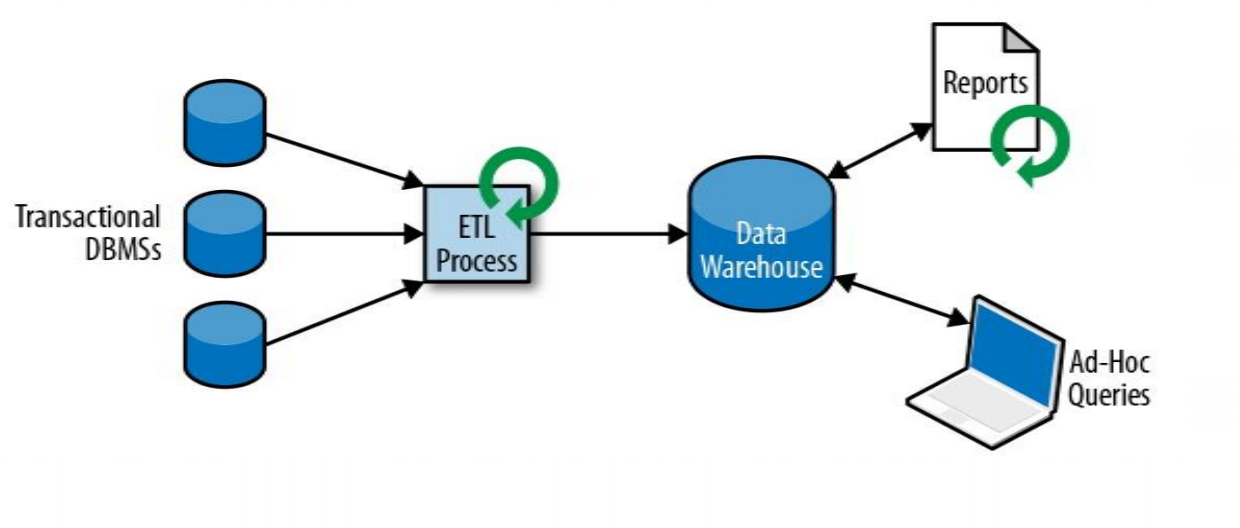
(2)分析处理
将数据从业务数据库复制到数仓,再进行分析和查询
(3)有状态的流式处理

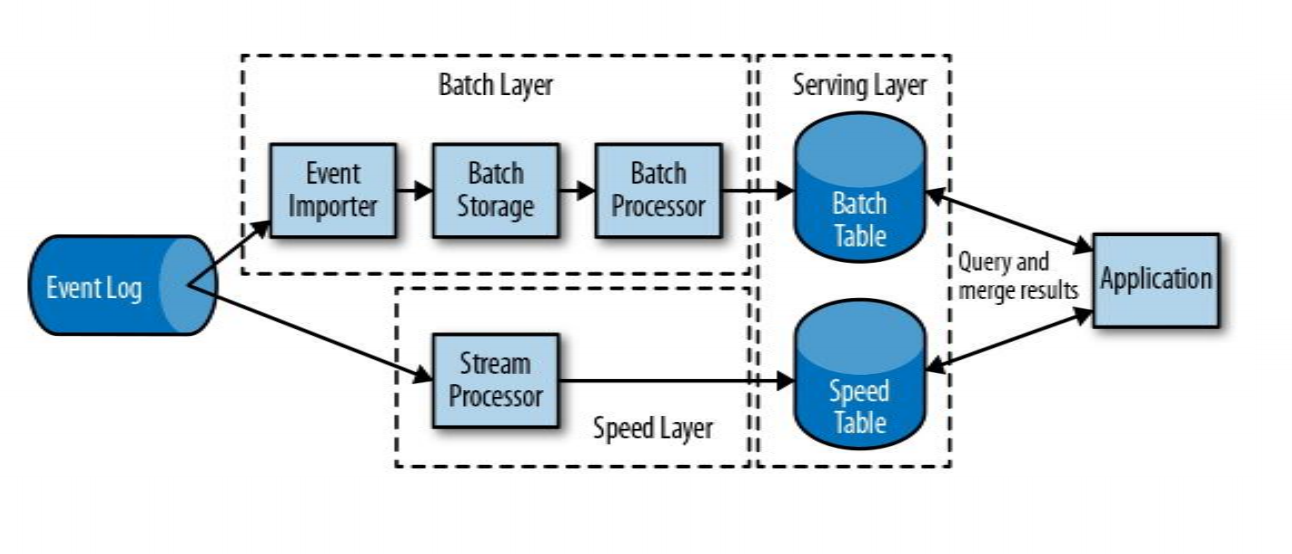
4、流处理演变
lambda架构,用两套系统,同时保证低延迟和结果准确
二、Flink运行时组件
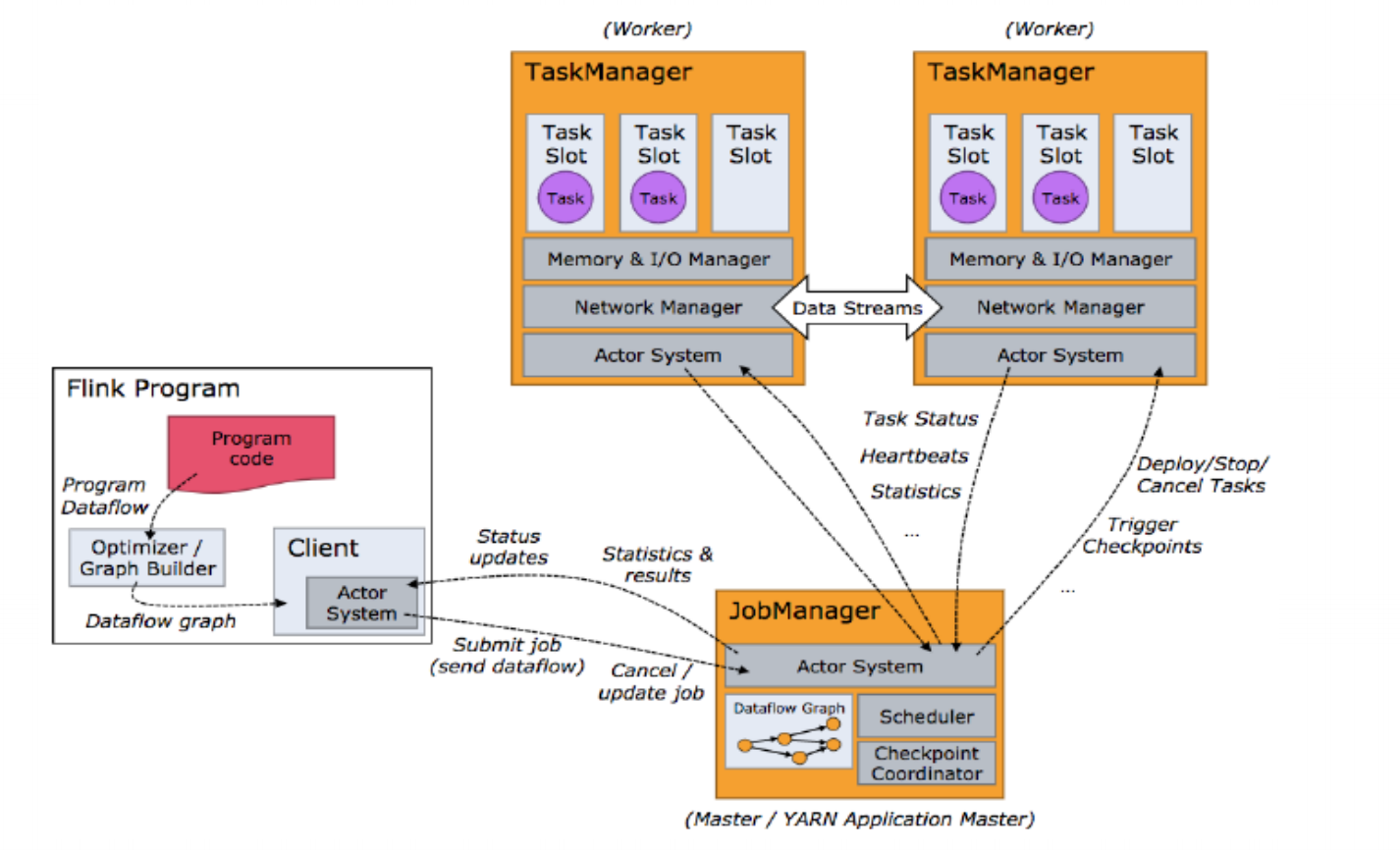
Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager),以及分发器(Dispatcher)。因为 Flink 是用 Java 和 Scala 实现的,所以所有组件都会运行在Java 虚拟机上。
1、作业管理器
(1)控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的 JobManager 所控制执行。
(2)JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图 (JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、 库和其它资源的JAR包。
(3) JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做 “执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
(4)JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源, 也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的 资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中, JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints) 的协调。
2、任务管理器(TaskManager)
(1)Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制TaskManager能够执行的任务数量。
(2)启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
(3)在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
3、资源管理器(ResourceManager)
(1)主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。
(2)Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
(3) 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
4、分发器(Dispatcher)
(1)可以跨作业运行,它为应用提交提供了REST接口。
(2)当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
(3)Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
(4)Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
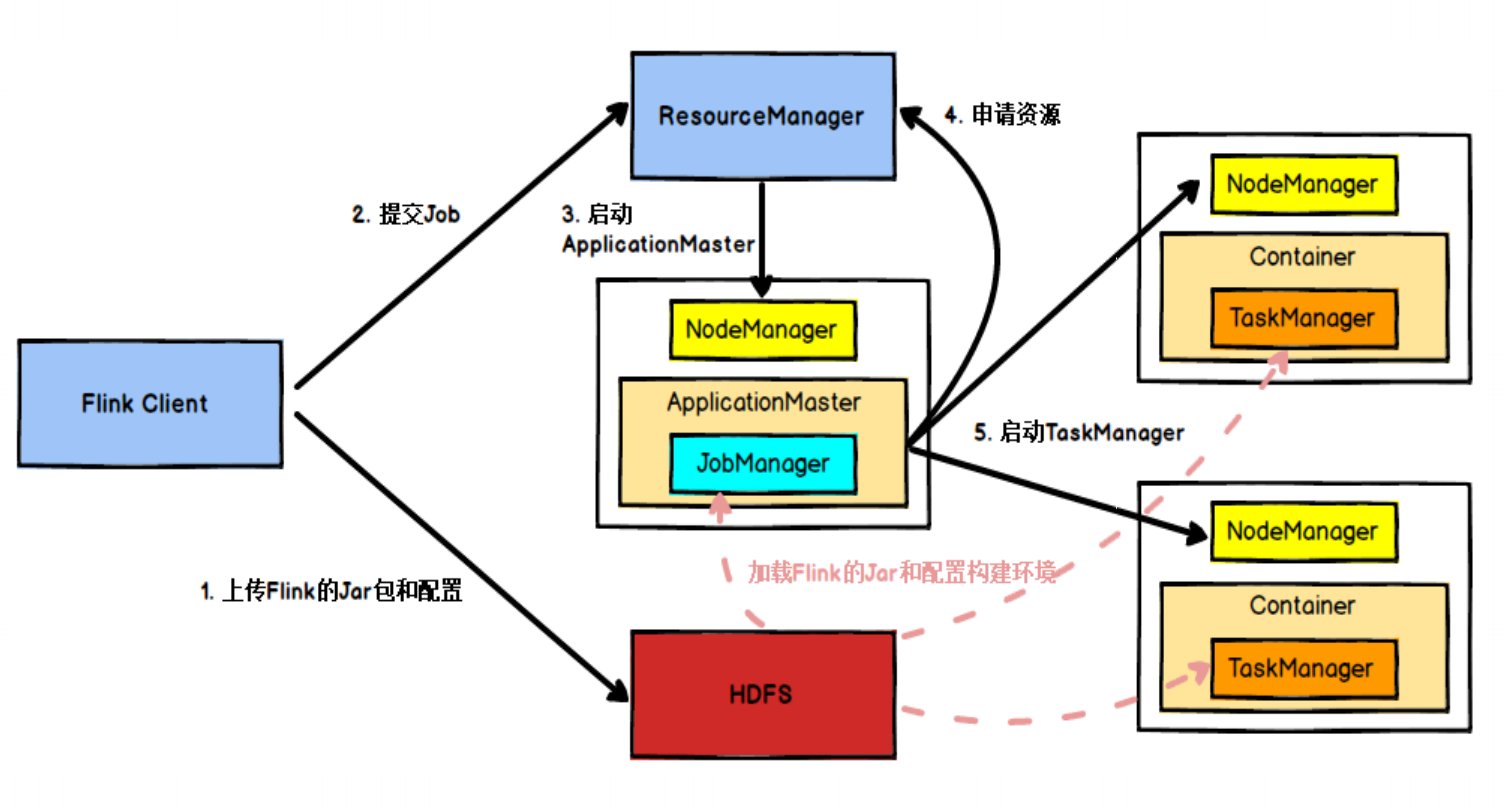
5、任务提交流程
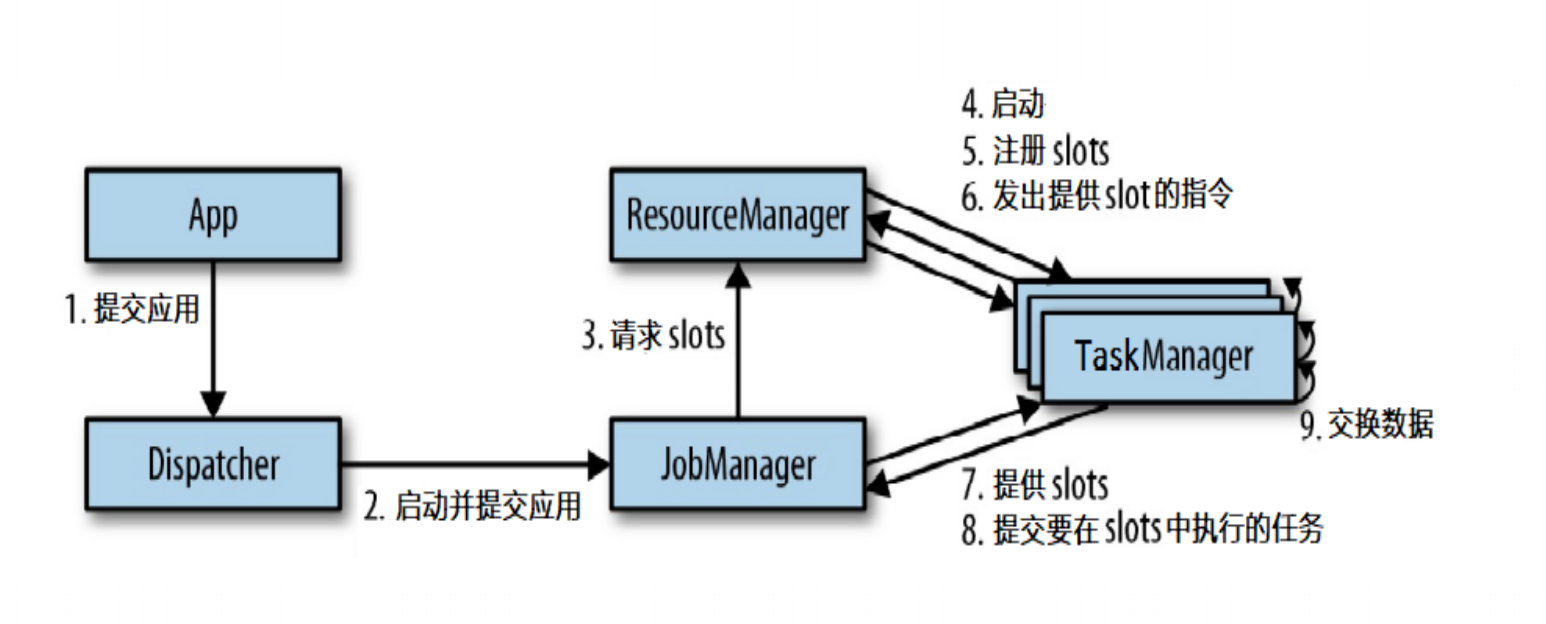
6、任务提交流程(Yarn)