rancher上kube-prometheus部署报错处理
问题描述
rancher 上安装kube-prometheus,版本:8.3.9 ,Chart 仓库:bitnami
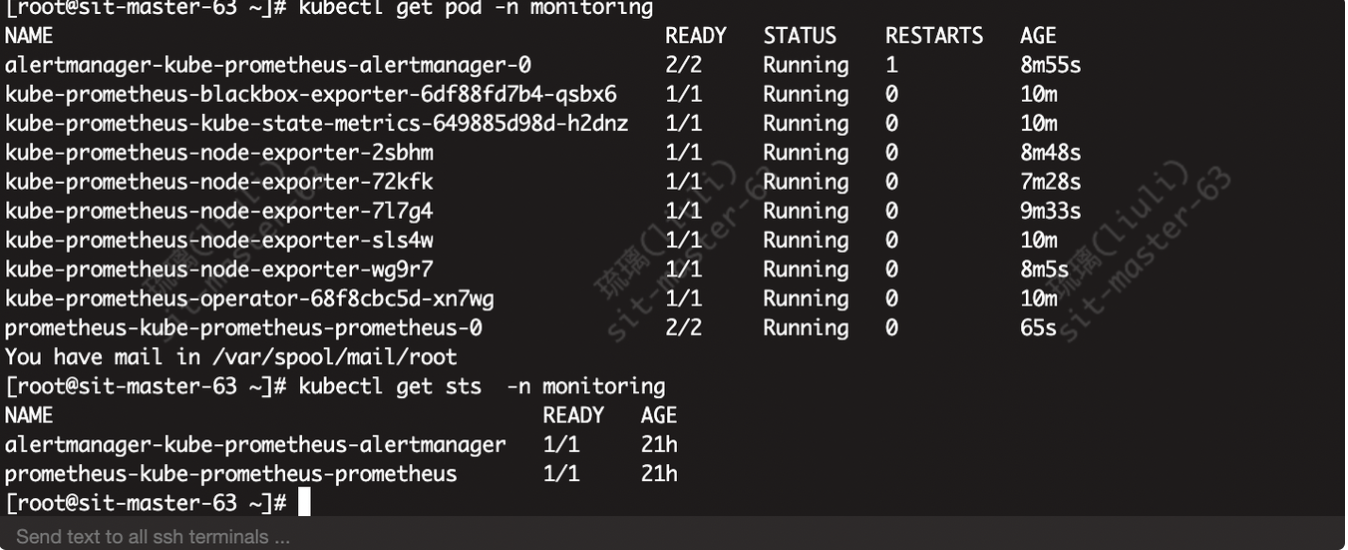
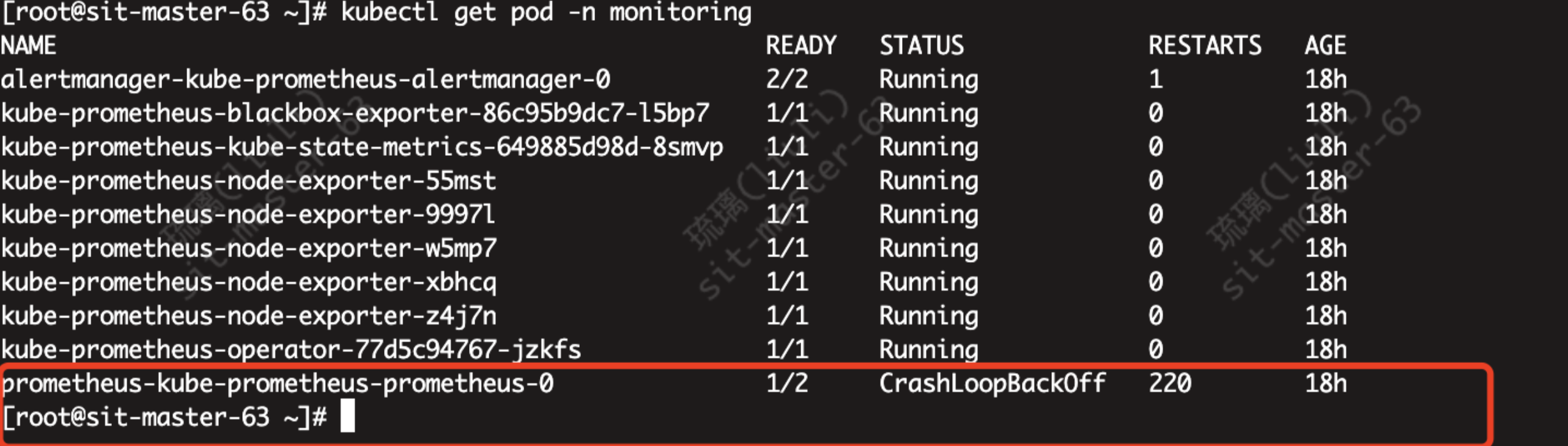
服务 pod: prometheus-kube-prometheus-prometheus 启动异常
问题处理
kubectl describe po -n monitoring prometheus-kube-prometheus-prometheus-0
报错如下:
caller=main.go:468 level=error msg="Error loading config (--config.file=/etc/prometheus/config_out/prometheus.env.yaml)" file=/etc/prometheus/config_out/prometheus.env.yaml err="parsing YAML file /etc/prometheus/config_out/prometheus.env.yaml: empty duration string" |

查看具体报错信息:
kubectl describe po -n monitoring prometheus-kube-prometheus-prometheus-0 | grep /etc/prometheus/config_out/prometheus.env.yaml

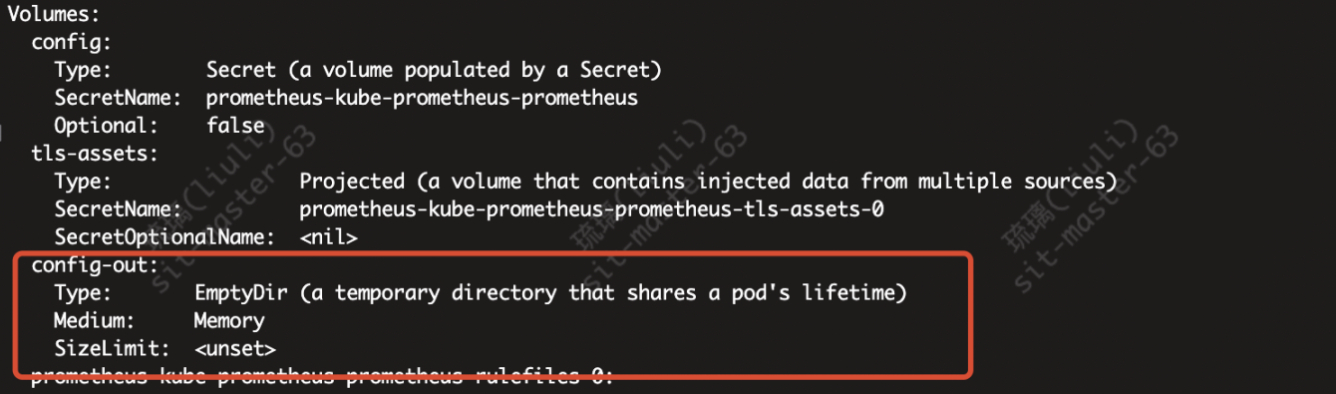
查看挂载信息

查看卷信息 ,config-out Type类型为 EmptyDir
备注:
emptyDir类型的volume在pod分配到node上时被创建,kubernetes会在node上自动分配 一个目录,因此无需指定宿主机node上对应的目录文件。这个目录的初始内容为空,当Pod从node上移除时,emptyDir中的数据会被永久删除。 |
查看在宿主机上EmptyDir映射信息


docker inspect 8ce86e673faa
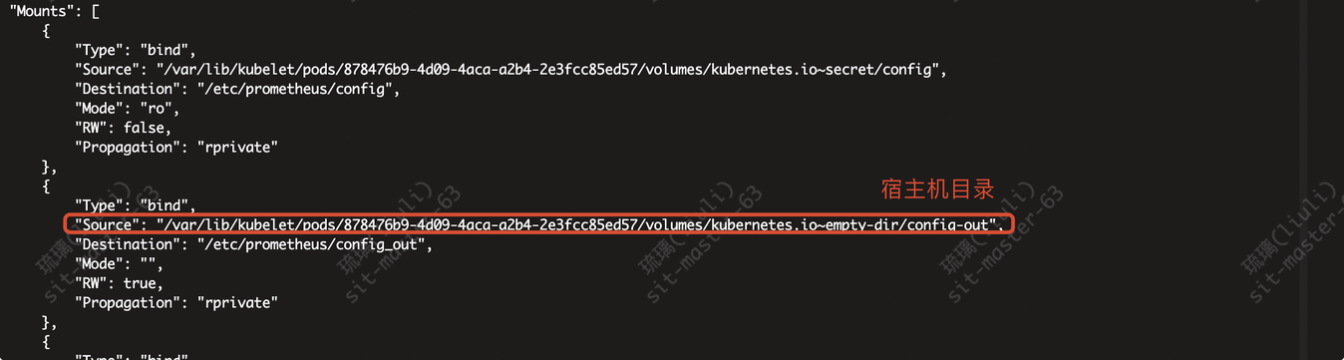
cd /var/lib/kubelet/pods/878476b9-4d09-4aca-a2b4-2e3fcc85ed57/volumes/kubernetes.io~empty-dir/config-out

github 查询资料发现此issues:
What steps will reproduce the bug?
|
it seems setting these values fixes the issue:
在values中添加如下scrapeInterval 、evaluationInterval 值
prometheus: scrapeInterval: 1m evaluationInterval: 1m |
Prometheus以scrape_interval规则周期性从监控目标上收集数据,然后将数据存储到本地存储上。
Prometheus以evaluation_interval规则周期性对告警规则做计算,然后更新告警状态。
# 评估告警周期 evaluation_interval
# 数据采集间隔 scrape_interval
添加完成后服务正常启动