PostgreSQL 源码部署
说明
1. 准备工作
1.1 源码包下载
进入 选择 Source 栏目:
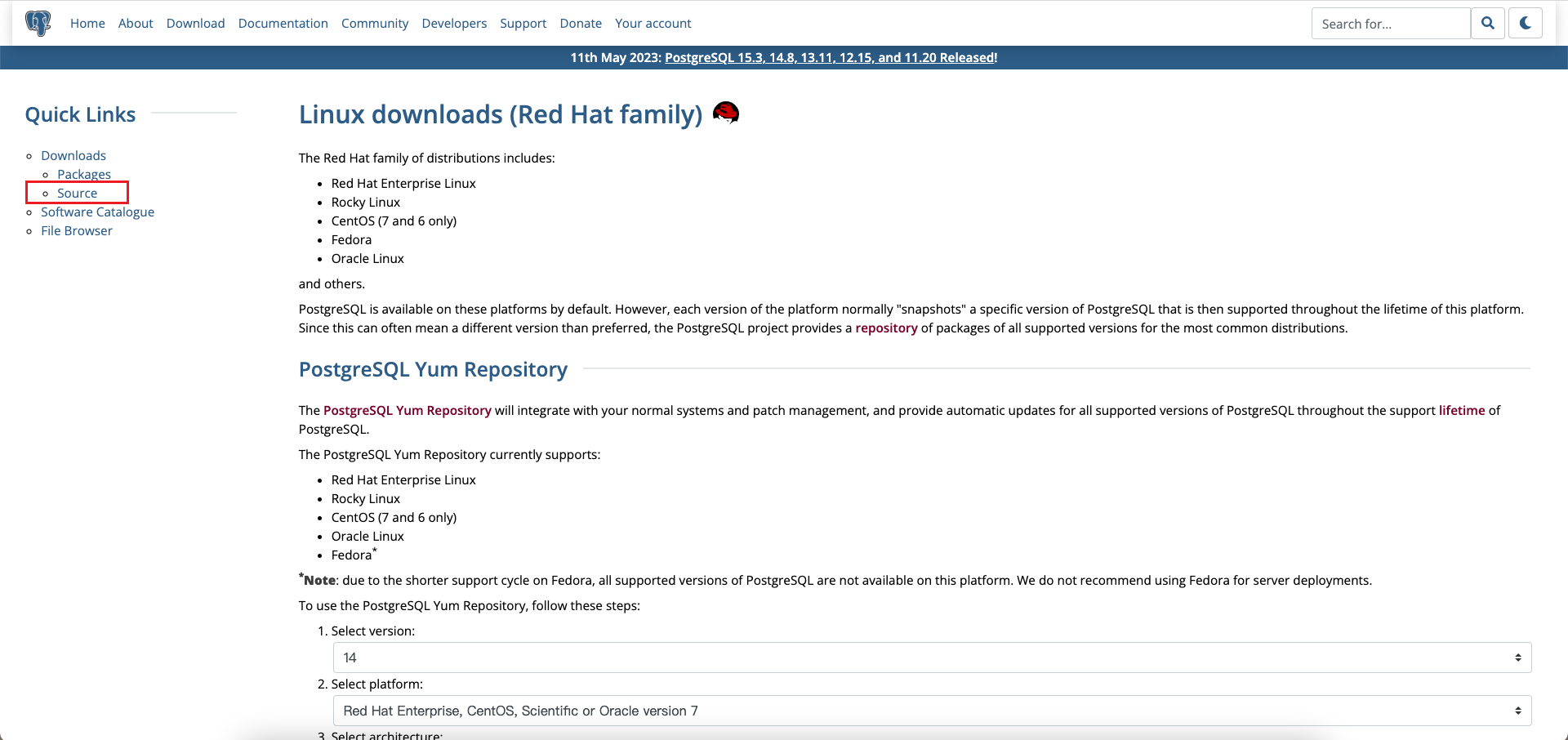
接着就进入源码版本目录,选择需要安装的版本下载即可。

1.2 解压安装目录
源码包下载完成后,上传到服务器,进行解压缩:
tar -xf postgresql-14.8.tar.gz
1.3 安装依赖包
yum install gcc gcc-c++ readline-devel readline readline-dev zlib-devel
1.4 添加用户
groupadd postgres
useradd -g postgres postgres
1.5 创建数据目录
为 PostgreSQL 创建存储数据的目录:
mkdir -p /data/pgsql/{data,logs}
chown -R postgres:postgres /data/pgsql/
2. 编译安装
2.1 源码编译
cd 到源码目录下:
cd /opt/postgresql-14.8
执行 configure:
./configure --prefix=/usr/local/pgsql
| 参数名 | 含义 |
|---|---|
| prefix | 软件目录也就是安装目录 |
| with-perl | 编译时添加该参数才能够使用 perl 语法的 PL/Perl 过程语言写自定义函数,需要提前安装好相关的 perl 开发包:libperl-dev |
| with-python | 编译时添加该参数才能够使用 python 语法的 PL/Perl 过程语言写自定义函数,需要提前安装好相关的 python 开发包:python-dev |
| with-blocksize & with-wal-blocksize | 默认情况下 PG 数据库的数据页大小为 8KB,若数据库用来做数仓业务,可在编译时将数据页进行调整,以提高磁盘 IO |
编译安装:
make && make install
编译完成后,会在 prefix 参数指定的目录下生成 PostgreSQL 程序文件。
2.2 配置环境变量
根据自己实际环境,修改安装目录和数据目录:
vi /etc/profile
export PGHOME=/usr/local/pgsql
export PGDATA=/data/pgsql/data
export PATH=$PGHOME/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/pgsql/lib
source /etc/profile
2.3 初始化数据库
切换到 postgres 用户:
su postgres
执行数据库初始化 -D 选项后面是数据目录:
initdb -D /data/pgsql/data/
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "zh_CN.UTF-8".
The default database encoding has accordingly been set to "UTF8".
initdb: could not find suitable text search configuration for locale "zh_CN.UTF-8"
The default text search configuration will be set to "simple".
Data page checksums are disabled.
fixing permissions on existing directory /data/pgsql/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Asia/Shanghai
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
pg_ctl -D /data/pgsql/data/ -l logfile start
2.4 启动数据库
进入 logs 目录下,创建启动日志文件,将启动时的日志输出到该文件:
touch /data/pgsql/logs/start.log
启动 PostgreSQL:
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log start
关闭数据库可以使用下方命令:
# 关闭数据库
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log stop
# 重启数据库
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log restart
2.5 连接数据库
启动成功使用 psql 即可进入数据库:
>>>>$ psql
psql (14.8)
Type "help" for help.
postgres=# select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 14.8 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
3. 参数调整
3.1 配置 pg_hba
PostgreSQL 数据目录中,会自动生成 pg_hba.conf 文件,该文件是一个黑名单访问控制文件,可以控制允许哪些 IP 地址的机器访问数据库。默认,不允许远程访问数据,所以安装完成后需要配置下。
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
# Type 表示访问方式,local 表示本地套接字访问,DATABASE、USER 分别表示数据库和用户
# 参数 all 表示所有的数据库或用户,ADDRESS 表示一个地址或者网段,METHOD 表示验证的方式
# 默认的 trust 表示完全信任,password 表示发送明文密码,不建议使用,建议使用 md5 模式
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
可以在 pg_hba 文件中加入下面一行,表示允许任何用户远程连接数据库,连接时需要提供密码:
host all all 0/0 md5
详细可参考文档:
3.2 监听相关
在数据目录中的 postgresql.cnf 中,可以找到如下内容:
listen_addresses = 'localhoset' # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to 'localhost'; use '*' for all
# (change requires restart)
其中,参数 listen_addresses 表示监听的 IP 地址,默认是在 localhost/127.0.0.1 处监听,这样会导致远程主机无法访问数据库,如果需要远程访问,需要将其设置为实际网络地址,设置为 * 表示监听所有地址,该参数修改重启生效。
PS:配置完 3.1 和 3.2 两个步骤,PostgreSQL 就可以支持远程连接。
下表是其它常见监听相关的参数,按需设置:
| 参数 | 含义 |
|---|---|
| port | 服务器监听TCP端口,默认 5432 |
| max_connections | Server 端允许最大连接数,默认 100 |
| superuser_reserved_connections | Server 端为超级账号保留的连接数,默认3 |
| unix_socket_directory | Server 监听客户端 Unix 嵌套字目录,默认 /tmp |
2.4 日志文件
下面是 PostgreSQL 日志相关的参数,一般都是需要配置:
| 参数 | 含义 |
|---|---|
| logging_collector | 是否打开日志 |
| log_rotation_age | 超过多少天生产一个新的日志文件 |
| log_rotation_size | 超过多少大小生成一个新的日志文件 |
| log_directory | 日志目录,可以是绝对路径或相对 PGDATA 的相对路径 |
| log_destination | 日志记录类型,默认是 stderr,只记录错误输出 |
| log_filename | 日志文件名,默认是 postgresql-%Y-%m-%d_%H%M%S.log |
| log_truncate_on_rotation | 当日志名已存在时,是否覆盖原文件 |
以下是几个常用的配置模版,每天生成一个新的日志文件:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 1d
log_rotation_size = 0
每当一个日志写满时(如 100MB)切换一个日志:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 0
log_rotation_size = 100MB
只保留最近 7 天的日志,进行循环覆盖:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'error_log.log'
log_truncate_on_rotation = on
log_rotation_age = 7d
log_rotation_size = 0
2.5 内存参数
熟悉 MySQL 的同学都知道它有一个参数 innodb_buffer_pool 限制 innodb 引擎缓冲池的大小,buffer pool 越大可以缓存的页就越多,可以减少很多磁盘 IO 消耗,提升数据库的性能。shared_buffer 在 PostgreSQL 中与 MySQL 的 buffer pool 是异曲同工。
| 参数 | 含义 |
|---|---|
| shared_buffer | 共享内存缓存区大小,默认 128MB |
| temp_buffers | 每个会话使用的临时缓存区大小,默认 8MB |
| work_mem | 内存临时表排序操作或者 hash join 需要使用到的内存缓存大小,默认 4MB |
| maintenance_work_mem | 对于维护性操作(vacuum、create index)最大使用内存,默认 64M,最小 1M |
| max_stack_depth |