Spark thriftserver对接cdh hive
1、背景
客户需要使用spark的thriftserver来通过beeline或者jdbc 来使用spark sql
环境: spark 3.2.0
hive: 2.1.1-cdh6.3.2
hadoop: 3.0.0-cdh6.3.2
2、操作方案
2.1 下载spark 3.2.0 部署包
https://archive.apache.org/dist/spark/spark-3.2.0/
解压安装包
tar -xzvf /opt/spark-3.2.0-bin-hadoop3.2.tar.gz -C /opt
2.2 配置hadoop参数
切换目录
cd /opt/spark-3.2.0-bin-hadoop3.2/conf
需要添加的文件
如下hdfs-site.xml,core-site.xml,yarn-site.xml,hive-site.xml
hive.keytab (从cdh的启动目录中复制到conf目录下)
以下路径已cdh为例
一般在/var/run/cloudera-scm-agent/process/
cp /etc/hadoop/conf/hdfs-site.xml . cp /etc/hadoop/conf/core-site.xml . cp /etc/hadoop/conf/yarn-site.xml .
hdfs-site.xml参数添加以下参数(防止出现filesystem close 异常)
<property> <name>fs.hdfs.impl.disable.cache</name> <value>true</value> </property>
hive-site.xml
按照自己的环境修改以下参数
javax.jdo.option.ConnectionURL
javax.jdo.option.ConnectionDriverName
javax.jdo.option.ConnectionUserName
javax.jdo.option.ConnectionPassword
hive.metastore.schema.verification : false
hive.metastore.kerberos.keytab.file : 具体的hivekeytab的路径
hive.server2.thrift.port : 自定义修改默认为10005
hive.server2.authentication.kerberos.principal #注意kerberos的realm
hive.metastore.kerberos.principal #注意kerberos的realm
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager--> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://cm-server.open.hadoop:3306/hive?useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.metastore.try.direct.sql.ddl</name> <value>true</value> </property> <property> <name>hive.metastore.try.direct.sql</name> <value>true</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>false</value> </property> <property> <name>datanucleus.metadata.xml.validate</name> <value>false</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>datanucleus.autoStartMechanism</name> <value>SchemaTable</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.warehouse.subdir.inherit.perms</name> <value>true</value> </property> <property> <name>hive.server2.logging.operation.enabled</name> <value>true</value> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/var/log/hive/operation_logs</value> </property> <property> <name>mapred.reduce.tasks</name> <value>-1</value> </property> <property> <name>hive.exec.reducers.bytes.per.reducer</name> <value>67108864</value> </property> <property> <name>hive.exec.copyfile.maxsize</name> <value>33554432</value> </property> <property> <name>hive.exec.reducers.max</name> <value>1099</value> </property> <property> <name>hive.metastore.execute.setugi</name> <value>true</value> </property> <property> <name>hive.support.concurrency</name> <value>true</value> </property> <property> <name>hive.zookeeper.quorum</name> <value>cm-agent1.open.hadoop,cm-server.open.hadoop,cm-agent2.open.hadoop</value> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> </property> <property> <name>hive.zookeeper.namespace</name> <value>hive_zookeeper_namespace_hive</value> </property> <property> <name>hive.metastore.server.min.threads</name> <value>200</value> </property> <property> <name>hive.metastore.server.max.threads</name> <value>100000</value> </property> <property> <name>hive.cluster.delegation.token.store.class</name> <value>org.apache.hadoop.hive.thrift.MemoryTokenStore</value> </property> <property> <name>hive.metastore.fshandler.threads</name> <value>15</value> </property> <property> <name>hive.metastore.sasl.enabled</name> <value>true</value> </property> <property> <name>hive.metastore.kerberos.principal</name> <value>hive/_HOST@FZCDH.COM</value> </property> <property> <name>hive.metastore.kerberos.keytab.file</name> <value>hive.keytab</value> </property> <property> <name>hive.metastore.event.listeners</name> <value></value> </property> <!--property> <name>hive.metastore.transactional.event.listeners</name> <value>org.apache.hive.hcatalog.listener.DbNotificationListener</value> </property--> <property> <name>hive.metastore.notifications.add.thrift.objects</name> <value>false</value> </property> <property> <name>hive.metastore.event.db.listener.timetolive</name> <value>172800s</value> </property> <property> <name>hive.metastore.server.max.message.size</name> <value>536870912</value> </property> <property> <name>hive.service.metrics.file.location</name> <value>/var/log/hive/metrics-hivemetastore/metrics.log</value> </property> <property> <name>hive.metastore.metrics.enabled</name> <value>true</value> </property> <property> <name>hive.service.metrics.file.frequency</name> <value>30000</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10005</value> </property> <property> <name>hive.server2.authentication</name> <value>kerberos</value> </property> <property> <name>hive.server2.authentication.kerberos.principal</name> <value>hive/_HOST@FZCDH.COM</value> </property> <property> <name>hive.server2.authentication.kerberos.keytab</name> <value>/opt/spark-3.3.1-bin-hadoop3/conf/hive.keytab</value> </property> </configuration>
2.3 调整spark 参数
1、spark-defaults.conf
添加以下参数
spark.master=yarn #提交到yarn上 spark.executor.memory=1g spark.driver.memory=1g spark.executor.cores=2 spark.yarn.jars = hdfs://mg1/tmp/spark3.2/jars/*.jar ##由于有时候客户使用的hive版本较低,默认的的hive依赖为hive 2.3.9导致不兼容,通过下面的方法配置特定的hive版本及jar包 spark.sql.hive.metastore.version=2.1.1-cdh6.3.2 spark.sql.hive.metastore.jars=path spark.sql.hive.metastore.jars.path=file:///opt/cloudera/parcels/CDH/lib/hive/lib/*.jar
参考文档:https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html#interacting-with-different-versions-of-hive-metastore
2、spark-env.sh
添加以下参数
export HADOOP_CONF_DIR=/etc/hadoop/conf export YARN_CONF_DIR=/etc/hadoop/conf
3、启动thriftserver
./sbin/start-thriftserver.sh --master yarn --deploy-mode client --principal hive/cm-server.open.hadoop@FZCDH.COM --keytab /opt/spark-3.2.0-bin-hadoop3.2/conf/hive.keytab --driver-java-options "-Dsun.security.krb5.debug=true" --conf "spark.hadoop.hive.metastore.sasl.enabled=true" --conf "spark.hadoop.hive.metastore.kerberos.principal=hive/_HOST@FZCDH.COM" --conf "spark.hadoop.hive.metastore.execute.setugi=true"
检查端口是否启动成功
ss -tunlp | grep 10005

使用beeline 进行连接
./bin/beeline -u 'jdbc:hive2://cm-server.open.hadoop:10005/default;principal=hive/cm-server.open.hadoop@FZCDH.COM'
附录
FQA-使用insert into 时出现filesystem close 异常
1、现象
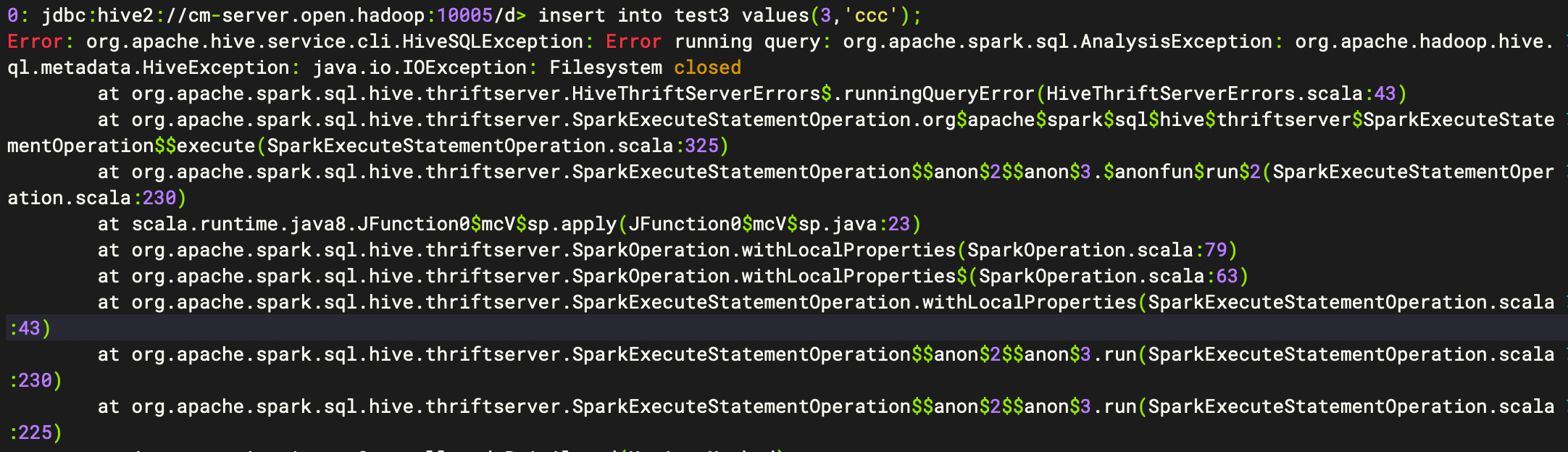
2、解决方案
在hdfs-site.xml添加以下参数
<property> <name>fs.hdfs.impl.disable.cache</name> <value>true</value> </property>
在spark集群中执行 insert 语句时报错,堆栈信息为:FileSystem closed。常常出现在ThriftServer里面。 当任务提交到集群上面以后,多个datanode在getFileSystem过程中,由于Configuration一样,会得到同一个FileSystem。 由于hadoop FileSystem.get 获得的FileSystem会从缓存加载,如果多线程中的一个线程closed,即如果有一个datanode在使用完关闭连接,其它的datanode在访问就会出现上述异常。