TDengine集群部署
1、基础环境
操作系统:centos7.9
内核版本:3.10
下载地址:https://docs.taosdata.com/releases/tdengine/#3110
架构设置:3 dnode,3 mnode
依赖操作系统用户:root
2、环境部署
1、集群节点部署
下载TDengine-server-3.1.1.0-Linux-x64.tar.gz包到服务器解压
tar -xzvf TDengine-server-3.1.1.0-Linux-x64.tar.gz cd TDengine-server-3.1.1.0 #执行./install.sh
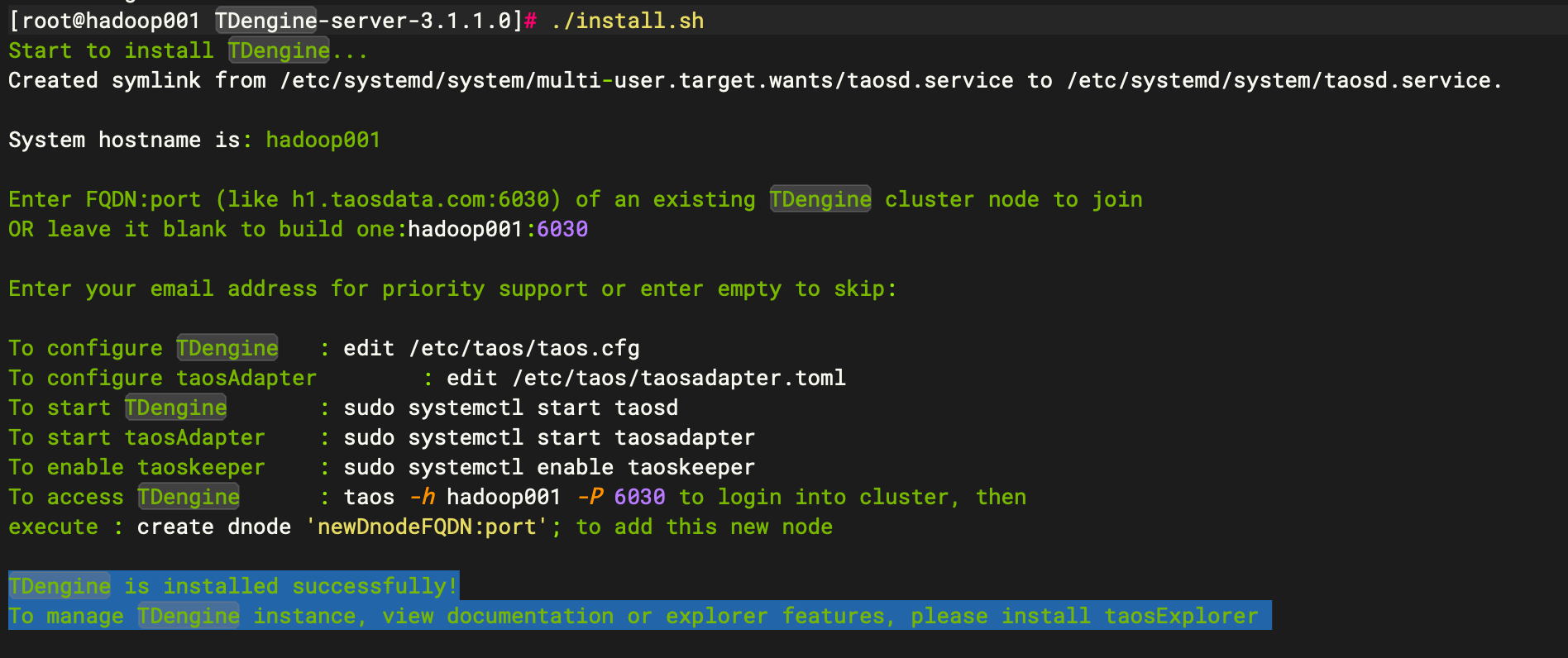
其中hostname为本机的主机名
如果已经存在tdengine集群,则填写tdengine集群中的某一台机器主机名:端口(默认端口6030),如果不存在,则直接回车,创建本集群的第一个节点。
修改配置文件
vim /etc/taos/taos.cfg firstEp hadoop001:6030 #集群的第一个节点 fqdn hadoop001 #本机主机名 serverPort 6030 #服务端口 logDir /var/log/taos #日志目录 dataDir /var/lib/taos #数据目录
启动tdengine
启动服务进程:systemctl start taosd 停止服务进程:systemctl stop taosd 重启服务进程:systemctl restart taosd 查看服务状态:systemctl status taosd
2、集群节点扩容
前置条件:
1、保证操作系统干净,无遗留的tdengine数据及配置
2、保证网络畅通(集群中所有主机在端口 6030-6042 上的 TCP/UDP 协议能够互通。)
3、物理节点安装 TDengine,且版本必须是一致的,但不要启动 taosd。安装时,提示输入是否要加入一个已经存在的 TDengine 集群时,第一个物理节点直接回车创建新集群,后续物理节点则输入该集群任何一个在线的物理节点的 FQDN:端口号(默认 6030);
4、确认所有节点的hostname 是否存在相同,如存在相同hostname,则需要进行修改
5、修改tdengine配置文件
vim /etc/taos/taos.cfg // firstEp 是每个数据节点首次启动后连接的第一个数据节点 firstEp hadoop001:6030 // 必须配置为本数据节点的 FQDN,如果本机只有一个 hostname,可注释掉本项 fqdn hadoop002 // 配置本数据节点的端口号,缺省是 6030 serverPort 6030
启动tdengine
systemctl start taosd
##连接 taos -h hadoop001 -P 6030
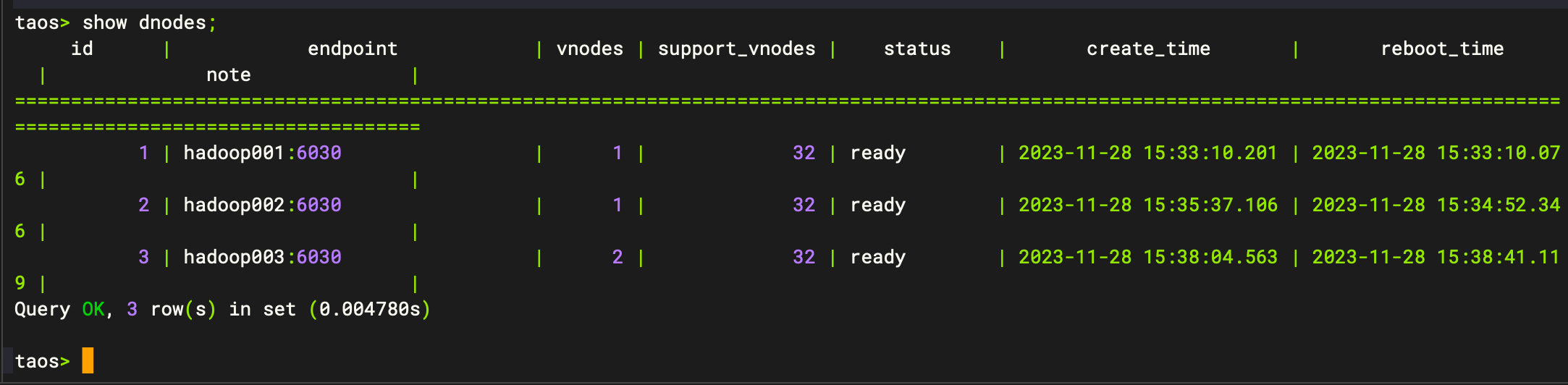
#添加dnode create dnode 'hadoop002:6030'; #查看添加的dnode show dnodes;
#添加mnode create mnode on DNODE <dnode_id>; #create mnode on DNODE 3; #查看mnode show mnodes;

3、测试连接
taos -h hadoop001 -P 6030
CREATE DATABASE demo;
USE demo;
CREATE TABLE t (ts TIMESTAMP, speed INT);
INSERT INTO t VALUES ('2019-07-15 00:00:00', 10);
INSERT INTO t VALUES ('2019-07-15 01:00:00', 20);
SELECT * FROM t;
ts | speed |
========================================
2019-07-15 00:00:00.000 | 10 |
2019-07-15 01:00:00.000 | 20 |