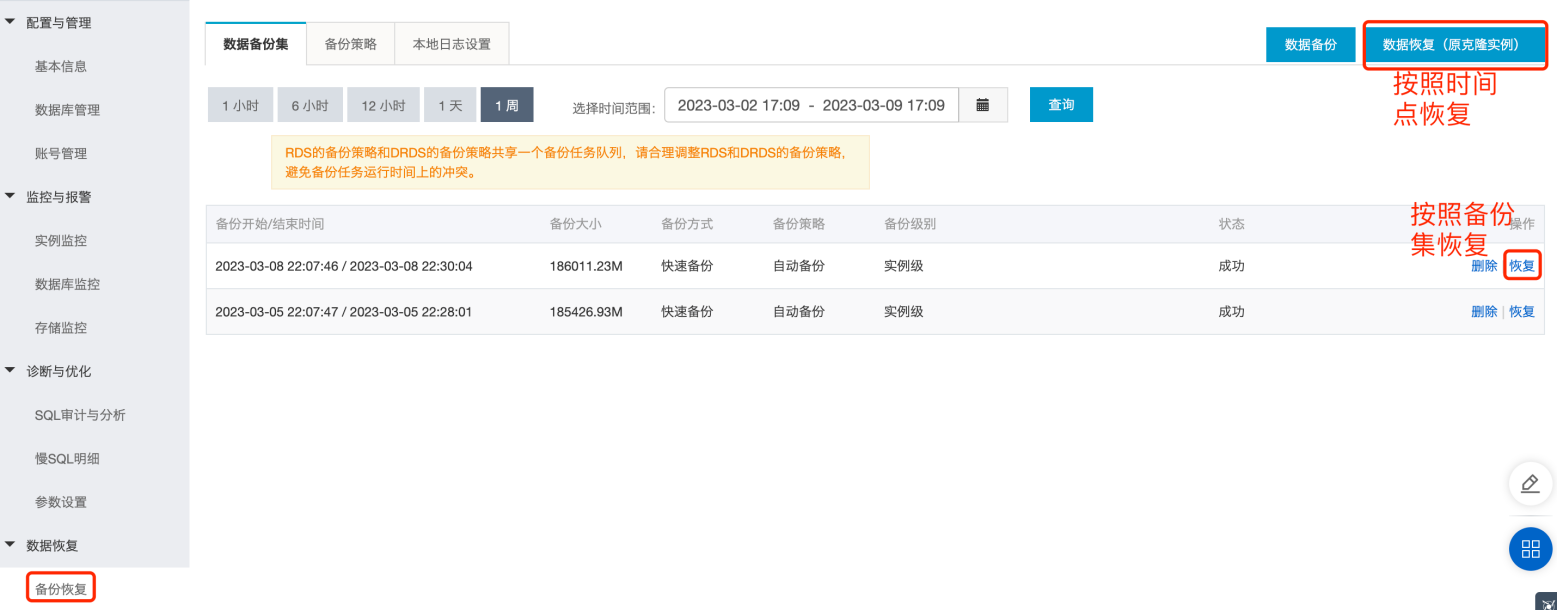
MySQL 组复制一致性保证
说明
本篇文章介绍,MySQL 组复制作为一个分布式系统,如何保证事务一致性?
1. 一致性级别
MySQL 8.0.14 版本开始,提供组复制变量:group_replication_consistency 用于配置不同级别的一致性保证。
如下 SQL 是本篇文章测试 MGR 一致性级别的表结构,实验均在单主模式下进行:
create table mgr_test(
id bigint primary key auto_increment,
r1 varchar(20),
r2 varchar(20)
);
insert into mgr_test(r1, r2) values ('a1', 'b1'),('a2', 'b2');1.1. EVENTUAL
确保最终一致性,并不能保证数据实时同步。
在未出现 group_replication_consistency 参数之前的默认行为,也是该参数的默认值。
读写事务不等待其他成员应用事务,意味着在次要成员上可能会读到旧数据,当主要成员发生故障时,新选举的成员立即接管流量,即使还有未应用完成的事务。此时业务可能会读到旧数据,可能会产生数据冲突导致回滚。
PRIMARY | SECONDARY |
次要成员,加共享读锁,模拟堵塞 lock table mgr_test read; | |
insert into mgr_test(r1, r2) values ('a3', 'b3'); 执行成功,查询有 3 行记录。 | |
select * from mgr_test; 查询立即返回,但是查询只有两行记录,读到旧数据 | |
unlock tables; 解锁,模拟恢复 | |
select * from mgr_test; 查询到最新数据 |
1.2. BEFORE_ON_PRIMARY_FAILOVER
确保从节点晋升为主节点后的本地一致性。
当发生故障转移时,在新的主要成员上,新的只读事务或读写事务将被保留,直到尚未应用完的事务被完全应用。该模式能够确保在主要成员发生故障转移时,客户端总能读取主要成员上的最新数据。虽然一致性得到保证,但是客户端可能出现延迟等待主库处理完成积压的事务,通常这种延迟应该是较小的,取决于积压事务的量。
1.3. BEFORE
确保本地强一致性,并不保证其他节点数据实时同步。
本地节点必须要等待中继日志数据全部应用完成后,才会执行新的请求,否则会一直等待。等待的时间和中继日志里未应用的事务量成正比。保证了本地节点永远可以读到最新的数据,但是如果存在大事务,应用期间相当于该节点直接不可用。该模式下包括 BEFORE_ON_PRIMARY_FAILOVER 提供的一致性。
PRIMARY | SECONDARY 1 | SECONDARY 2 |
次要成员,加共享读锁,模拟堵塞 lock table mgr_test read; | ||
insert into mgr_test(r1, r2) values ('a4', 'b4'); 执行成功,查询表中共有 4 行记录。 | ||
select * from mgr_test; 执行查询,已经被堵塞了,因为本地有 Binlog 没有应用完,会话状态为: Executing hook on transaction begin. | select * from mgr_test; 执行成功,查询表中有 4 行记录,该节点无影响。 |
1.4. AFTER
确保全局强一致性,可以保证所有节点数据实时同步。
此选项为 强同步 选项,设置为此模式的节点,必须等待集群内其他节点应用完中继日志中的事务,才能返回结果。优先保证了集群内所有节点数据的一致性,性能很差。该模式下包括 BEFORE_ON_PRIMARY_FAILOVER 提供的一致性。
PRIMARY | SECONDARY 1 | SECONDARY 2 |
次要成员,加共享读锁,模拟堵塞 lock table mgr_test read; | ||
insert into mgr_test(r1, r2) values ('a4', 'b4'); 直接卡主,无法执行,在等待次要成员应用日志。 | 此时次要成员 2 节点也被卡住 | |
unlock tables; 解锁,让日志回放。 | ||
insert 执行成功,耗时 60 秒 |
1.5. BEFORE_AND_AFTER
最高级别,确保本地强一致性,全局强一致性。结合 BEOFRE 和 AFTER 的特性。
读写事务等待所有先序的事务在应用之前完成且直到其更改在其它成员上完成应用。只读事务在执行之前等待所有先前的事务完成。这可以保证此事务在最新的数据快照上执行,并且一旦事务完成,所有后续任何不管在哪个成员上执行的事务都会读取包含其更改的数据状态,性能极差。