阿里云ES跨账号数据迁移(reindex)
1、背景与前置条件
总的来说,阿里云es集群间数据迁移,有三中方式,logstash、reindex、镜像备份恢复,分别使用不同的场景,本文档主要讨论reindex方式进行账号下,ES跨集群迁移时,使用reindex方式数据迁移。需满足:
A、 ES集群为同账号且是同一可用区
B、 ES集群间满足网络互通(配置实例网络互通)
C、 目标端配置自定义远程索引白名单(需重启)
2、配置实例网络互通
2.1、配置实例网络互通前置条件
为了安全性,阿里云ES实例间的网络默认是隔离的,若需要使用跨集群搜索功能,则需要将两个实例的网络进行打通。打通条件:
A、 相同版本。
B、 归属于相同账号。
C、 部署在同一个专有网络VPC(Virtual Private Cloud)中。
D、 同为单可用区实例,或同为多可用区实例。
2.2、操作步骤
A、 登录阿里云es控制台
B、 在顶部菜单栏处,选择地域。
C、 单击目标实例ID/名称链接。
D、 在左侧导航栏,单击安全配置。
E、 单击配置实例网络互通右侧的修改。
F、 在修改配置页面,单击+添加实例。
G、 在添加实例对话框中,选择需要进行网络互通的远程阿里云ES实例的ID。

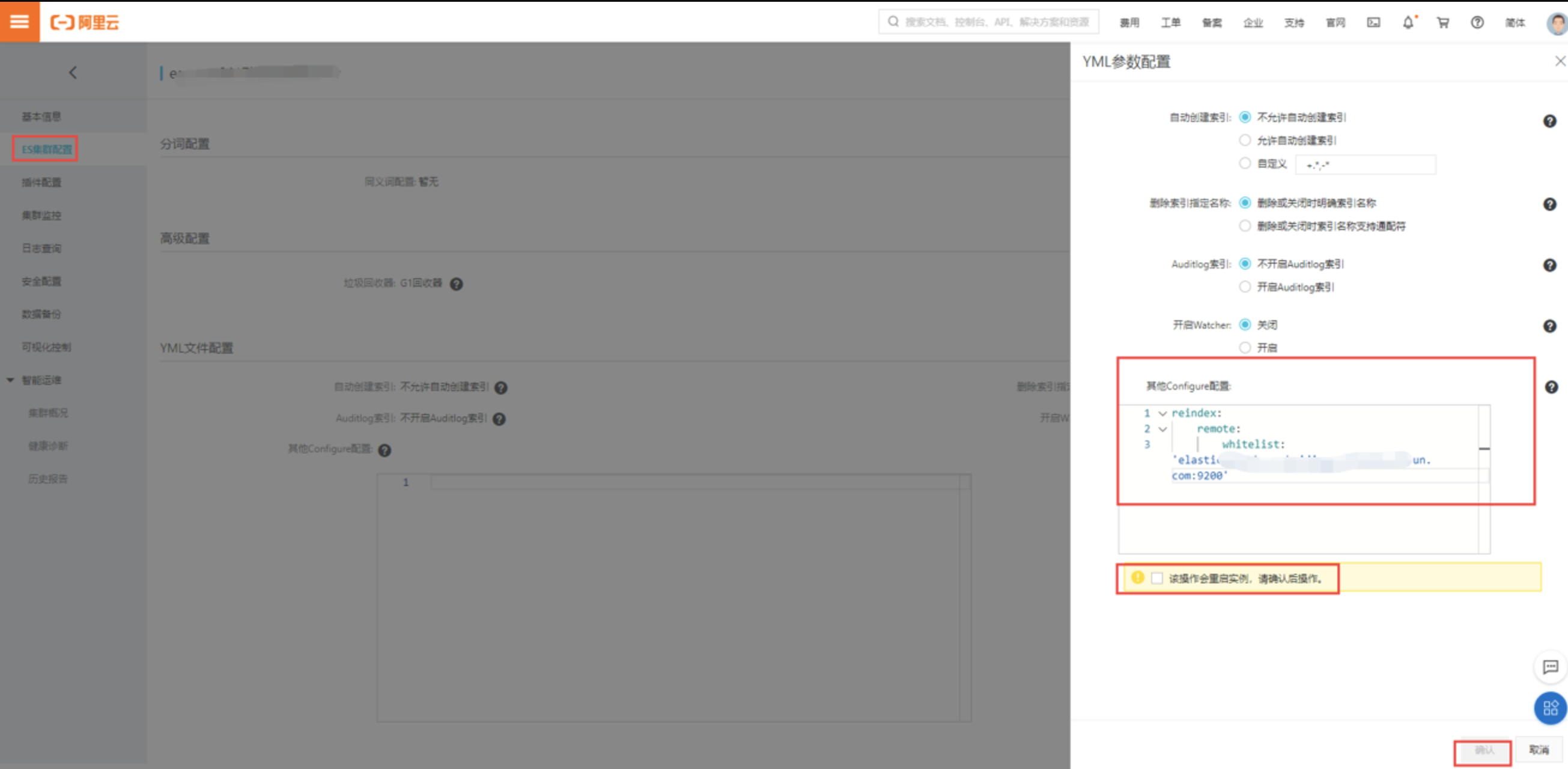
3、配置自定义远程索引白名单
3.1、操作步骤
A、 登录阿里云es控制台
B、 在顶部菜单栏处,选择地域。
C、 单击目标实例ID/名称链接。
D、 在左侧导航栏,单击ES集群配置。
E、 在右测点击修改配置,输入所源集群地址:端口,并重启es集群
4、reindex数据同步操作
4.1、操作步骤
以下操作表示从源ES集群中查询名为test1的索引,查询条件为title字段为elasticsearch,将结果写入当前集群的test2索引
POST _reindex
{
"size": 5000,
"source": {
"remote": {
"host": "源端地址:9200",
"username": "源端用于名",
"password": "源端密码"
},
"index": "源端索引名",
"size": 100
},
"dest": {
"index": "目标端索引名"
}
}
备注:
A、目标端和源端索引名不需要一致,指定就好
B、目标端需要创建索引(mapping不需要创建),或者在目标集群开启自动创建索引参数(需重启)
C、第一个"size": 5000是控制整体迁移的数据量
D、第二个"size": 100是控制迁移批次(即每次迁移数据量)
4.2、迁移完成后验证
源端和目标端分别执行下面命令,对比文档数量
GET _cat/indices/index_name?v