ES部署以及扩容
单节点RPM包方式部署
1、下载RPM包
官网下载地址:
Download Elasticsearch | Elastic
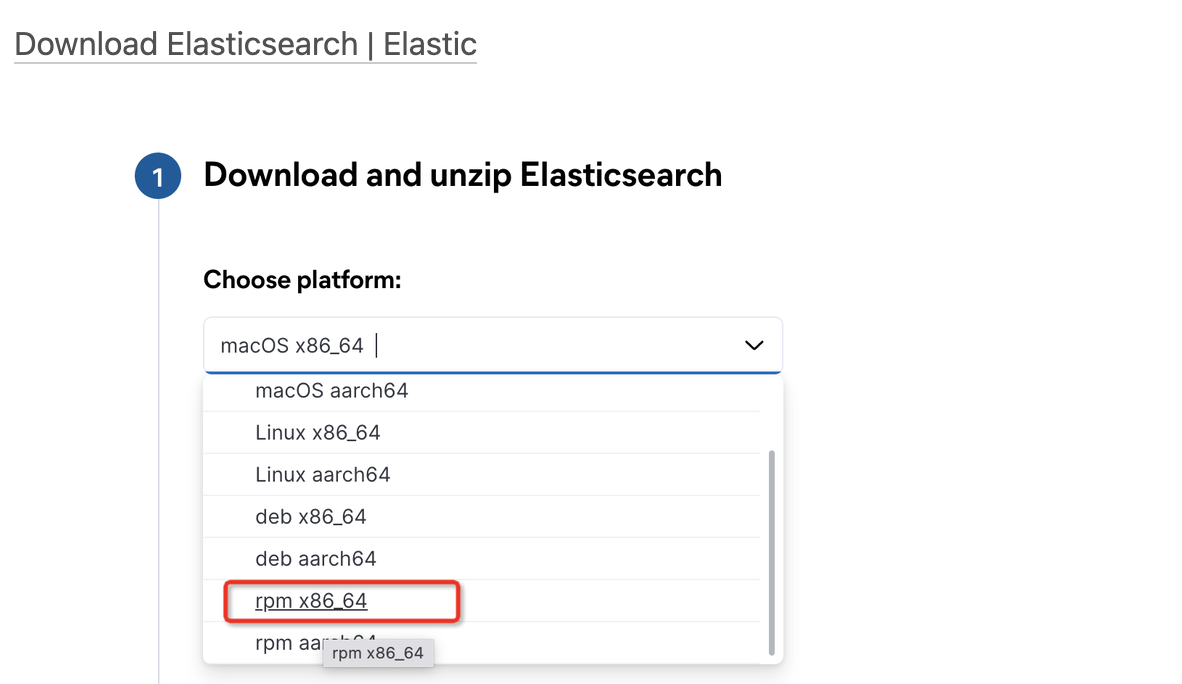
默认下载的为最新版本,如果想要下载历史版本,点击此处查看历史版本
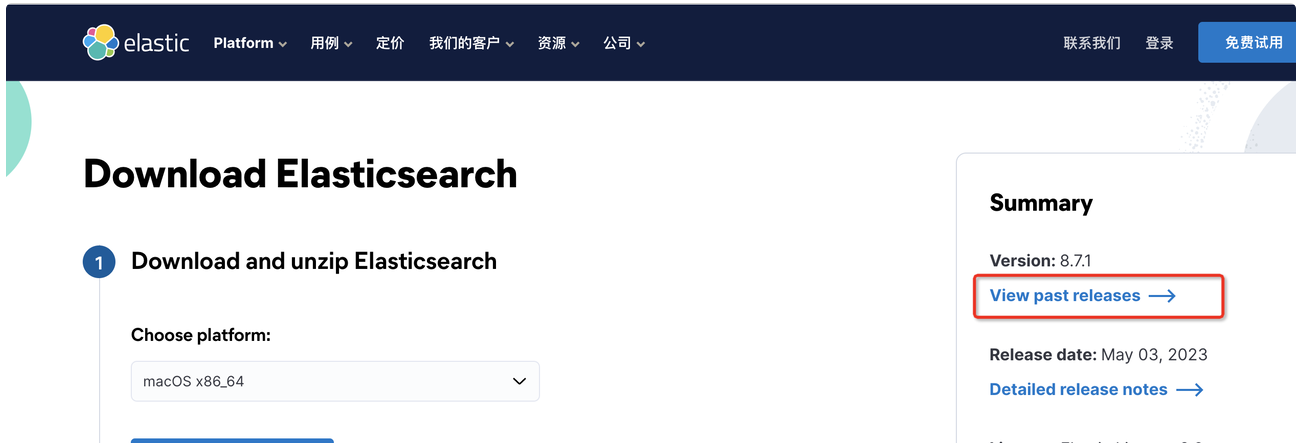 此处安装ES7.X 版本
此处安装ES7.X 版本
[root@172-16-121-160 ~]# rpm -ivh elasticsearch-7.17.10-x86_64.rpm warning: elasticsearch-7.17.10-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY Preparing... ################################# [100%] Creating elasticsearch group... OK Creating elasticsearch user... OK Updating / installing... 1:elasticsearch-0:7.17.10-1 ################################# [100%] ### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service ### You can start elasticsearch service by executing sudo systemctl start elasticsearch.service Created elasticsearch keystore in /etc/elasticsearch/elasticsearch.keystore
修改节点配置文件:
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: es-logs # 设置节点名称,集群内节点名称必须唯一。 node.name: node1 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 path.data: /var/lib/elasticsearch # 日志文件存放的位置 path.logs: /var/log/elasticsearch # 监听地址,用于访问该es network.host: 0.0.0.0 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["172.16.121.160"] # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["172.16.121.160"]
查看集群节点状态
[root@172-16-121-160 ~]# curl http://172.16.121.160:9200/_cluster/health?pretty=true
{
"cluster_name" : "es-logs",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}多节点方式部署
多节点方式部署,其实就是在单节点上启动多个进程,也就是伪集群的方式 (一般不这样做),此处略。
集群方式部署
1、下载
1)centos系统安装包下载
官网下载rpm包,版本选择的为7.6.0
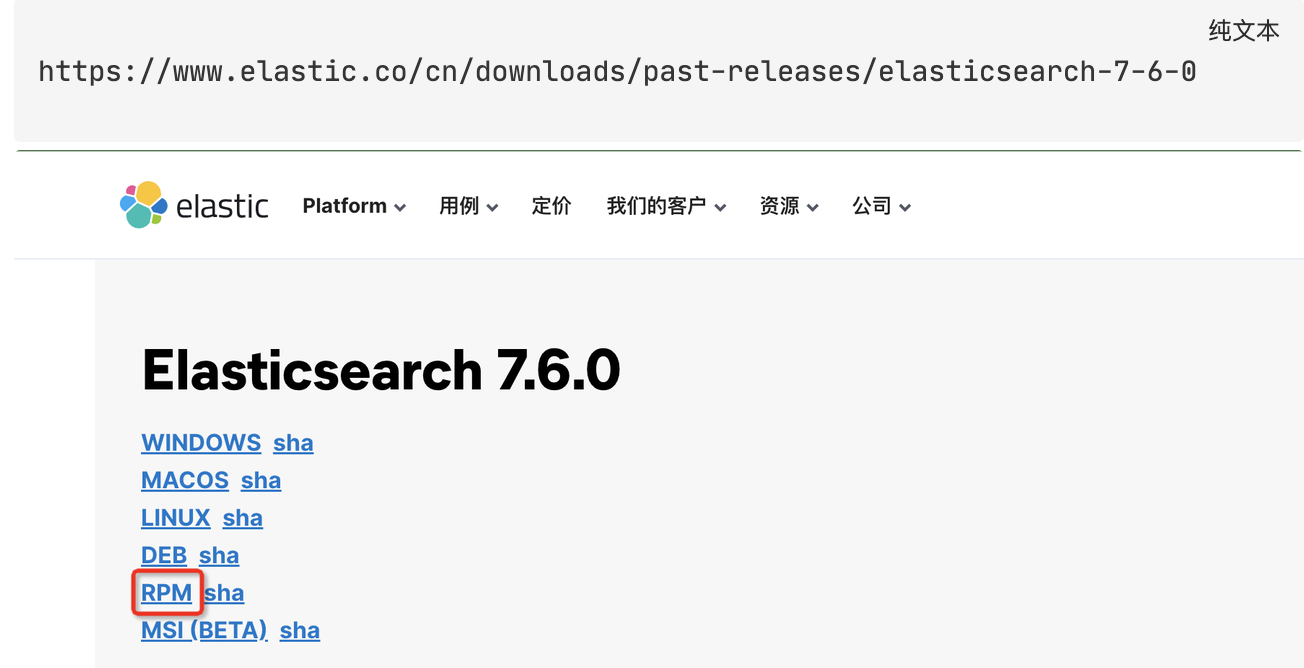
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-6-0
ubuntu系统安装包下载
官网下载deb包,版本选择的为7.6.0

https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-6-0
2、安装
centos系统安装
rpm -ivh elasticsearch-7.6.0-x86_64.rpm
ubuntu系统安装
dpkg -i elasticsearch-7.6.0-amd64.deb
3、数据目录创建
# 创建主节点数据存放目录 mkdir -p /data/elasticsearch/data # 创建主节点配置存放目录 mkdir -p /data/elasticsearch/config # 创建主节点日志存放目录 mkdir -p /data/elasticsearch/logs # 创建主节点插件存放目录 mkdir -p /data/elasticsearch/plugins
4、目录权限配置
chown -R elasticsearch:elasticsearch /data/elasticsearch
5、配置文件修改
1)node1节点
[root@xacraliware115 ~]# cat /etc/elasticsearch/elasticsearch.yml # 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: es-logs # 设置节点名称,集群内节点名称必须唯一。 node.name: node1 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 path.data: /data/elasticsearch/data # 日志文件存放的位置 path.logs: /data/elasticsearch/logs # 需求锁住物理内存,是:true、否:false #bootstrap.memory_lock: true # 监听地址,用于访问该es network.host: 0.0.0.0 # es对外提供的http端口,默认 9200 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 1 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] # 是否支持跨域,是:true,在使用head插件时需要此配置 http.cors.enabled: true # “*” 表示支持所有域名 http.cors.allow-origin: "*"
2)node2节点
[root@xdhhcm001 ~]# cat /etc/elasticsearch/elasticsearch.yml cluster.name: es-logs node.name: node2 node.master: true node.data: true path.data: /data/elasticsearch/data path.logs: /data/elasticsearch/logs #bootstrap.memory_lock: true network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.zen.minimum_master_nodes: 1 discovery.seed_hosts: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 cluster.initial_master_nodes: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] http.cors.enabled: true http.cors.allow-origin: "*"
3)node3节点
cluster.name: es-logs node.name: node3 node.master: true node.data: true path.data: /root/elasticsearch/data path.logs: /root/elasticsearch/logs #bootstrap.memory_lock: true network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.zen.minimum_master_nodes: 1 discovery.seed_hosts: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 cluster.initial_master_nodes: ["192.168.80.230:9300", "192.168.85.111:9300","192.168.85.112:9300"] http.cors.enabled: true http.cors.allow-origin: "*"
6、启动服务
#启动服务 systemctl start elasticsearch #配置服务开机自启动 systemctl enable elasticsearch
单节点扩容为集群
在之前安装的单节点的基础上扩容出两个ES节点。
新节点node02配置文件:
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: es-logs # 设置节点名称,集群内节点名称必须唯一。 node.name: node2 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 path.data: /var/lib/elasticsearch # 日志文件存放的位置 path.logs: /var/log/elasticsearch # 监听地址,用于访问该es network.host: 0.0.0.0 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["172.16.121.160","172.16.121.103","172.16.121.216"] # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["172.16.121.160","172.16.121.103","172.16.121.216"]
新节点node03配置文件:
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: es-logs # 设置节点名称,集群内节点名称必须唯一。 node.name: node3 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 path.data: /var/lib/elasticsearch # 日志文件存放的位置 path.logs: /var/log/elasticsearch # 监听地址,用于访问该es network.host: 0.0.0.0 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["172.16.121.160","172.16.121.103","172.16.121.216"] # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["172.16.121.160","172.16.121.103","172.16.121.216"]
分别启动node02,以及node03节点,重启成功后,检查集群状态
[root@172-16-121-103 ~]# curl http://172.16.121.160:9200/_cluster/health?pretty=true
{
"cluster_name" : "es-logs",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 4,
"active_shards" : 8,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}最后修改之前的node1节点,配置文件修改为如下内容:
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: es-logs # 设置节点名称,集群内节点名称必须唯一。 node.name: node1 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 path.data: /var/lib/elasticsearch # 日志文件存放的位置 path.logs: /var/log/elasticsearch # 监听地址,用于访问该es network.host: 0.0.0.0 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["172.16.121.160","172.16.121.103","172.16.121.216"] # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["172.16.121.160","172.16.121.103","172.16.121.216"]
重启node01节点,再次验证集群状态是否正常。(重启node01会触发重新选举master节点,因为之前node01为master节点)