HDP-Yarn开启CPU调度和隔离
进入到ambari主界面 点击yarn
点击config
CPU Scheduling and Isolation 设置为enable
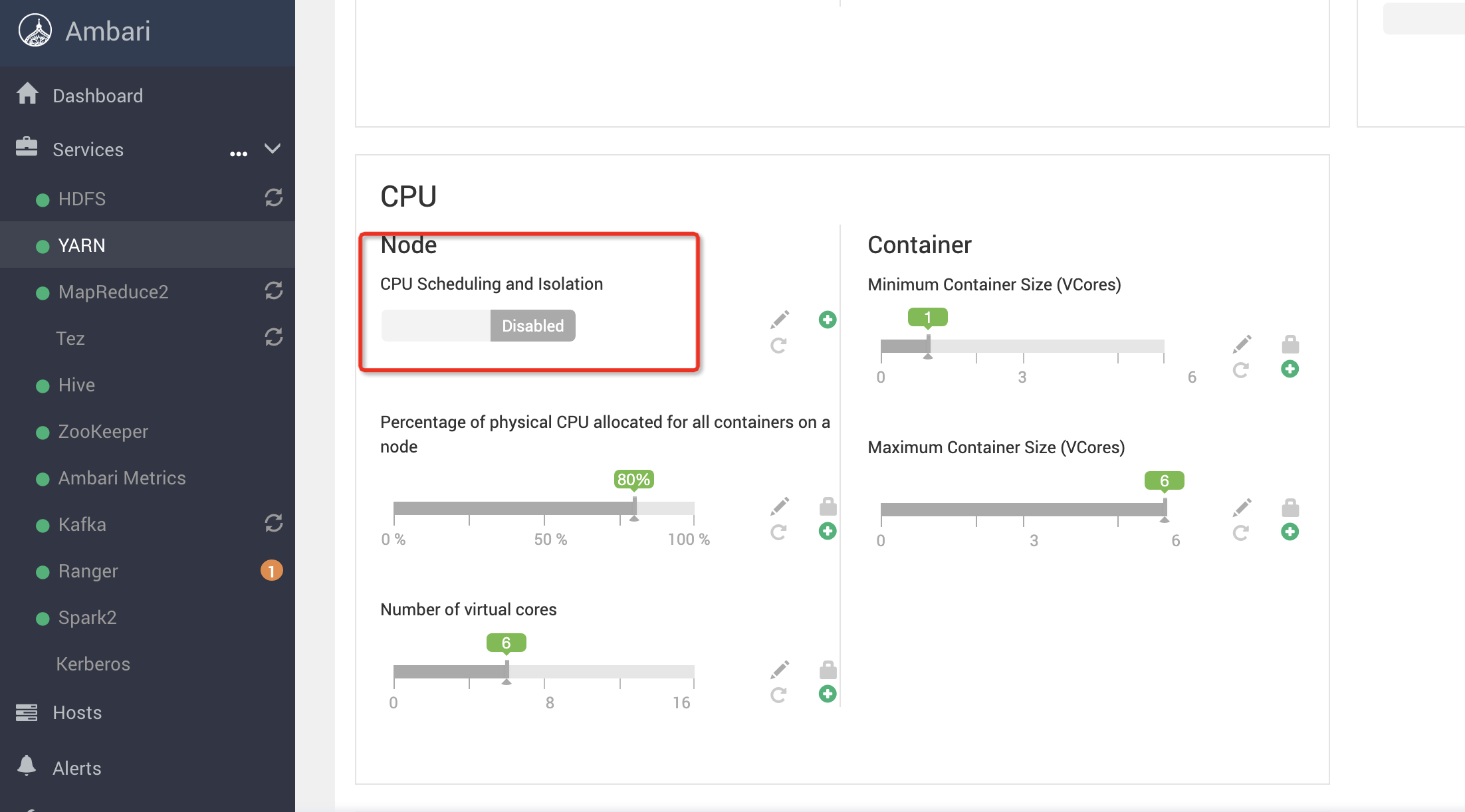
修改高级配置
点击ADVANCED
搜索需要修改的配
yarn.nodemanager.linux-container-executor.cgroups.mount-path =/sys/fs/cgroup #挂在目录
Yarn CGroup Hierarchy=/yarn
yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage=true
yarn.nodemanager.linux-container-executor.cgroups.hierarchy=/yarn
yarn.nodemanager.linux-container-executor.group=hadoop
yarn.nodemanager.linux-container-executor.nonsecure-mode.limit-users=false
保存配置 先不要重启yarn 。
编辑脚本
vi /etc/init.d/yarn_cgroup.sh
#!/bin/sh
mkdir -p /sys/fs/cgroup/cpu/yarn
chown -R yarn:hadoop /sys/fs/cgroup/cpu/yarn
mkdir -p /sys/fs/cgroup/memory/yarn
chown -R yarn:hadoop /sys/fs/cgroup/memory/yarn
mkdir -p /sys/fs/cgroup/blkio/yarn
chown -R yarn:hadoop /sys/fs/cgroup/blkio/yarn
mkdir -p /sys/fs/cgroup/net_cls/yarn
chown -R yarn:hadoop /sys/fs/cgroup/net_cls/yarn
mkdir -p /sys/fs/cgroup/devices/yarn
chown -R yarn:hadoop /sys/fs/cgroup/devices/yarn
分发每个nodemanager节点
scp yarn_cgroup.sh hdp0x:$PWD
执行脚本
source /etc/init.d/yarn_cgroup.sh
ps
如果/sys/fs/cgroup 只读模式 执行如下命令
mount -o remount,rw 文件挂载点名称 /sys/fs/cgroup
mount -o remount,rw /sys/fs/cgroup
然后去重启yarn服务。
冒烟测试
/usr/hdp/3.1.5.0-152/spark3/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --queue default1 /usr/hdp/3.1.5.0-152/spark3/examples/jars/spark-examples_2.12-3.2.1.jar 10000000