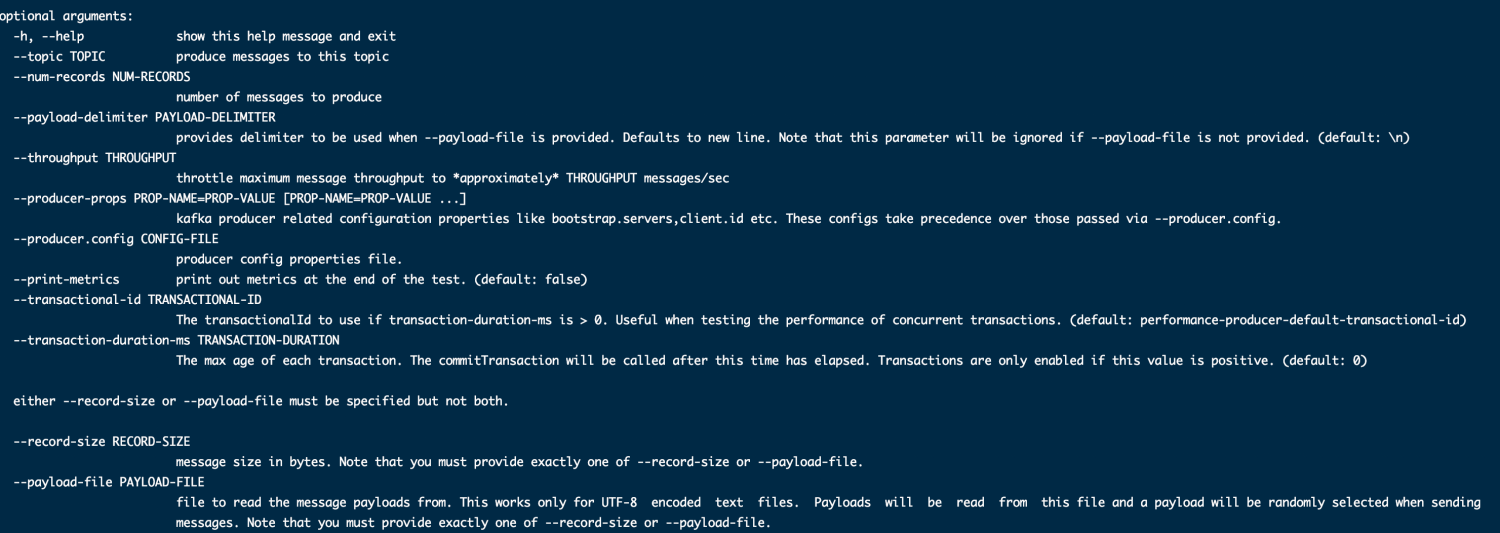
spark配置任务日志(Client模式& Cluster模式)
在Spark中,日志级别可以通过log4j.properties或log4j.xml文件来配置。对于spark-submit命令启动的应用程序,可以通过以下两种方式来修改日志级别:
对于Client模式,可以通过--conf选项来指定日志级别,例如:
spark-submit --class com.xxx.App --master yarn --deploy-mode client --conf spark.driver.extraJavaOptions="-Dlog4j.configuration=file:/path/to/log4j.properties" /path/to/app.jar
在这个例子中,设置了Spark应用程序的日志级别为file:/path/to/log4j.properties中指定的级别。
对于Cluster模式,可以通过--files选项来上传log4j.properties文件到HDFS,然后通过--conf选项来指定日志级别,例如:
spark-submit --class com.xxx.App --master yarn --deploy-mode cluster --files /path/to/log4j.properties#log4j.properties --conf spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j.properties --conf spark.executor.extraJavaOptions=-Dlog4j.configuration=log4j.properties /path/to/app.jar
在这个例子中,log4j.properties文件被上传到HDFS上,然后在--conf选项中指定了日志级别为log4j.properties中指定的级别。
需要注意的是,对于Client模式和Cluster模式,修改日志级别的方式是不同的。对于Client模式,可以直接指定spark.driver.extraJavaOptions来修改日志级别。而对于Cluster模式,则需要将log4j.properties文件上传到HDFS上,并在执行命令时指定相应的参数来修改日志级别。此外,应该确保log4j.properties文件中的配置项与您想要的日志级别相符合,以确保日志输出的正确性。