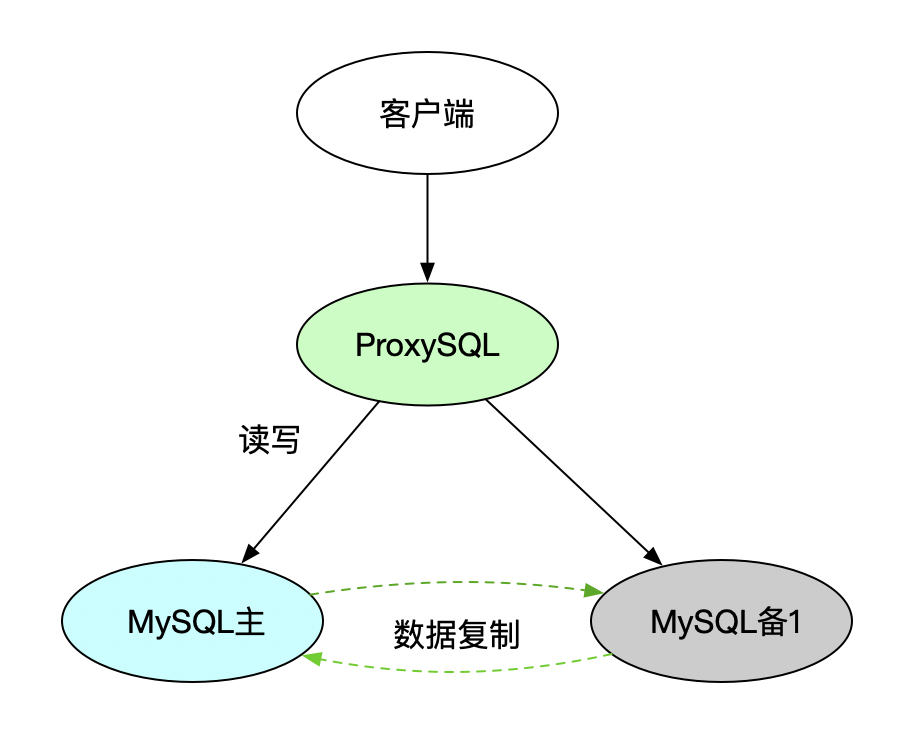
lru_cache 缓存
Python 语法: @functools.lru_cache(maxsize=128, typed=False)
Least-recently-used 装饰器。Iru 最近最少使用、cache 缓存。
如果 maxsize 设置为 None,则禁用 LRU 功能,并且缓存可以无限制增长。当 maxsize 是二的幂时,LRU 功能执行得最好。
如果 typed 设置为 True,则不同类型的函数参数将单独缓存。例如,f(3) 和 f(3.0) 将被视为具有不同结果的不同调用。
1、简单实例
import functools import time @functools.lru_cache() # add = functools.lru_cache()(add) def add(x, y, z=2): # add() = wrapper() time.sleep(z) return x + y add(4, 5) # 执行2秒 add(4, 5) # 瞬间完成 add(5, 6) # 执行2秒 add(5, 6) # 瞬间完成 add(4, 5) # 瞬间完成
分析缓存是如何实现的?
缓存可以通过字典记录实参和返回值,当下次传入相同实参时,通过 hash 访问;
key 是什么?
2、lru_cache 本质分析
2.1 lru_cache 伪代码
def lru_cache(maxsize=128, typed=False): def decorating_function(user_function): wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo) return update_wrapper(wrapper, user_function) # return wrapper return decorating_function def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo): make_key = _make_key # _make_key函数作用: hash 传入的实参 def wrapper(*args, **kwds): key = make_key(args, kwds, t-ped) # hash 实参作为 key result = user_function(*args, **kwds) return result return wrapper
2.2 key 是什么?
key 是传入的实参的组合,通过 _make_key 组织在一起。
# 分析源代码
def _make_key(args, kwds, typed, # (4, 5, z=6)
kwd_mark = (object(),),
fasttypes = {int, str},
tuple=tuple, type=type, len=len):
key = args # (4, 5)
if kwds: # {'z':6}
key += kwd_mark # (4, 5, object())
for item in kwds.items(): # items遍历 ——> 二元组 : ('z', 6)
key += item # (4, 5, object(), 'z', 6)
if typed:
key += tuple(type(v) for v in args)
if kwds:
key += tuple(type(v) for v in kwds.values())
elif len(key) == 1 and type(key[0]) in fasttypes:
return key[0]
return _HashedSeq(key) # _HashedSeq 是什么?
class _HashedSeq(list): # 我: _HashedSeq 是列表的子类
__slots__ = 'hashvalue'
def __init__(self, tup, hash=hash):
self[:] = tup # 切片赋值,右边为可迭代对象,self 为列表
self.hashvalue = hash(tup)
def __hash__(self):
return self.hashvalue # 相当于返回:hash(tuple(self))2.3 _make_key 实例
from functools import _make_key
_make_key((1,), {}, False) # 1
_make_key((1,), {'a':100}, False) # [1, <object at 0x29b644d7e70>, 'a', 100]
# 再通过 class _HashedSeq(list) 进行元组包裹、哈希。2.4 总结
lru_cache 缓存装饰器:
构造装饰器
将被包装函数拿进去
将所有实参
_make_key
将
_make_key放在tuple中哈希
3、Iru_cache 装饰器应用
3.1 使用前提
同样的函数参数一定得到同样的结果
函数执行时间很长,且要多次执行
本质是函数调用的参数 => 返回值
3.2 缺点
不支持缓存过期,key 无法过期、失效
不支持清除操作
不支持分布式,是一个单机的缓存
3.3 适用场景及实例
适用场景,单机上需要空间换时间的地方,可以用缓存来将计算变成快速的查询。cache 还可以通过预加载热点数据,使第一次也进行hash查询。
实例:
import functools @functools.lru_cache(maxsize=60) # 空间换时间,递归也有深度限制 def fib(n): return 1 if n < 3 else fib(n-1) + fib(n-2) fib(100)