云原生之网络篇
前言:在云原生如火如荼的今天,作为云原生的基石:kubernetes(简称k8s)是不得不掌握的技术。而k8s的网络插件是大家绕不开的技术,但是由于k8s的开源包容性,以及网络的复杂性,导致网络插件出现百花齐放百家争鸣的情况,这种情况导致我们的学习成本大大增加。在这种情况下,我建议大家学习最为主流的网络插件,今天我们讲解的主角就是最为主流的网络插件之一:calico、cilium。希望大家通过今天的分享,能够熟悉k8s网络相关技术知识。为以后处理相关问题打下坚实基础。
1、calico ipip模式
k8s网络插件主要分为:underlay和overlay,calico 主要分为3种模式:BGP属于underlay、IPIP和VXLAN属于overlay,由于环境受限,我们只能使用ipip或者VXLAN,因为ipip模式比VXLAN更高效,所以我们主要分析ipip模式,ipip模式主要原理就是在pod ip的基础上再封装一层node ip,这样在通过对应的路由规则,就可以转发到对应的目的地。
环境:
node:20u5, ip:10.0.0.125,pod ip:100.118.198.197
node:20u8, ip:10.0.0.128,pod ip:100.93.79.4
我们在20u5节点上面pod ip:100.118.198.197,然后去ping 20u8节点pod ip:100.93.79.4
$ ping -c 1 100.93.79.4
a、首先我们在100.118.198.197 pod 上面进行网络抓包,可以看到图1以下包:
 图1
图1
通过第一个包的ttl:64,我们可以看出来这个就是在 100.118.198.197 pod内发出的网络包,通过第二个返回的网络包的ttl:62,我们可以判断此网络包经过了2跳路由,哪到底是哪两跳呢?
b、通过图2路由我们知道,数据包是通过tunl0 发送给了 10.0.0.128

图2
c、我们在20u5 节点上面 tunl0网卡进行网络抓包,可以看到以下包:
 图3
图3
通过此包的第一个包和第二个包的ttl都是63,我们可以看出来:tunl0网卡正是容器 100.118.198.197的下一跳路由。
d、通过在20u8节点上面 tunl0网卡进行网络抓包,可以看到以下包:
 图4
图4
这里我们可以看到ttl并没有改变,网络包是怎么从20u5 节点tunl0网卡到达20u8节点tunl0网卡的?
e、最终我们在 100.93.79.4 pod 上面进行网络抓包,可以看到以下包:
 图5
图5
可以看到第一个包的ttl为62,说明网络包经过2跳最终到达的此pod,而第二个包ttl为64,也说明此pod确实是为 100.93.79.4。
f、我们通过抓包看到了calico IPIP模式的大致流量走向,但是我们在d步骤发现数据包从20u5节点发送到20u8节点,网络包是怎么从20u5节点到达20u8节点的?
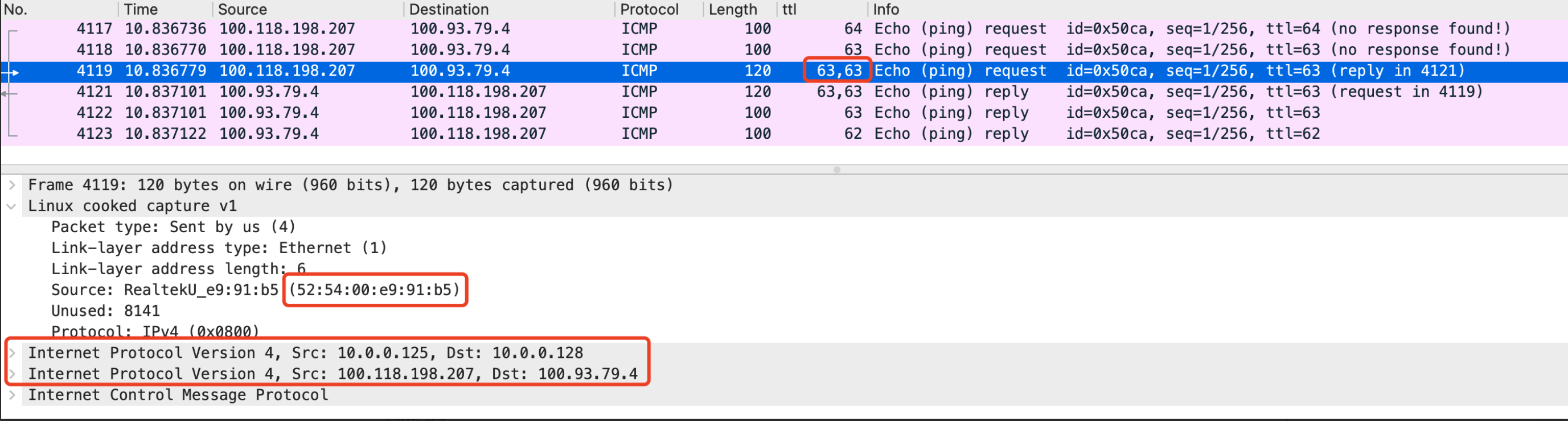 图6
图6
$ ip a | grep -C 1 '52:54:00:e9:91:b5' 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:e9:91:b5 brd ff:ff:ff:ff:ff:ff inet 10.0.0.125/24 brd 10.0.0.255 scope global enp1s0
我们通过在20u5 节点上面执行 tcpdump -i any -w 20u5-host-all.pcap 命令抓取所有网卡的网络包,得到图6的数据包,我们发现在节点上面竟然有3次ICMP协议的ping请求,实际上我们只发送了一次ping请求。而我们分析数据包:通过TTL可以看出第一个包是从容器内发出,第二个包就是我们在tunl0网卡抓取到的,第三个包我们查看mac地址发现竟然是20u5节点的enp1s0网卡。从上面发现网络包竟然存在2个IP包头,一个是pod之间的,另一个是宿主机节点之间的。此网络包的大小也比之前的包大20个字节。由此可见中间转发的过程中,calico最终会在转发出node之前打上node节点的ip以及对应node节点的ip,整条链路为:pod网卡 ==> tunl0网卡 ==> 20u5 enp1s0宿主机网卡 ==> 20u8 enp1s0宿主机网卡 ==> tunl0网卡 ==> pod网卡,流转图见图7
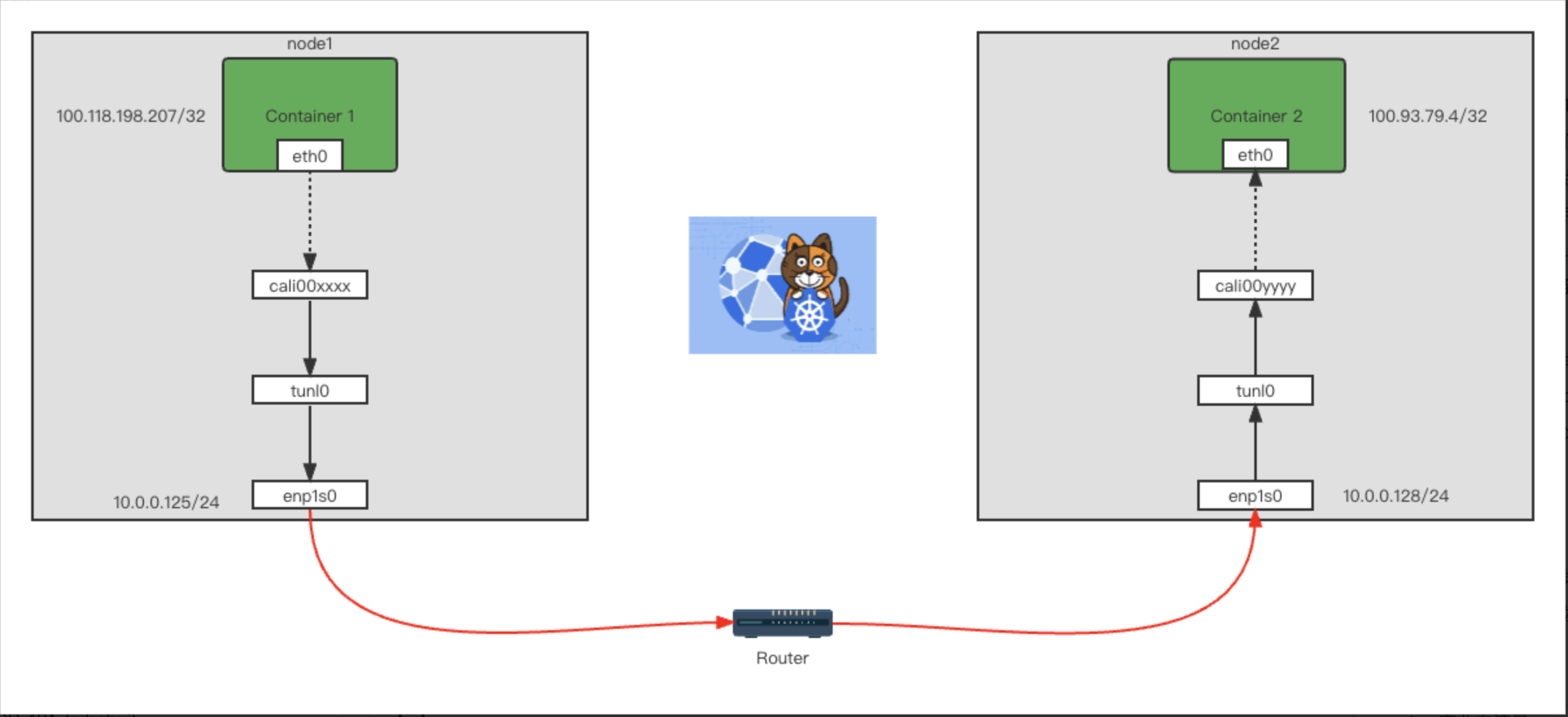 图7
图7
2、优化ipip模式
我们可以看到calico ipip模式默认的配置需要在每个node节点内转发2次才能达到最终pod内,这样的效率有点太低了。那么我们可以怎么优化一下呢?ipip模式下可以选择配置在跨子网的时候才需要走tunl0网卡。
a、我们把ipipMode配置修改为CrossSubnet
$ kubectl get ippool -n kube-system -o yaml apiVersion: v1 items: - apiVersion: crd.projectcalico.org/v1 kind: IPPool metadata: name: default-ipv4-ippool spec: blockSize: 26 cidr: 100.64.0.0/10 ipipMode: CrossSubnet natOutgoing: true nodeSelector: all() vxlanMode: Never
b、我们在20u5 node节点上面抓取网络包,可以看到如图8:
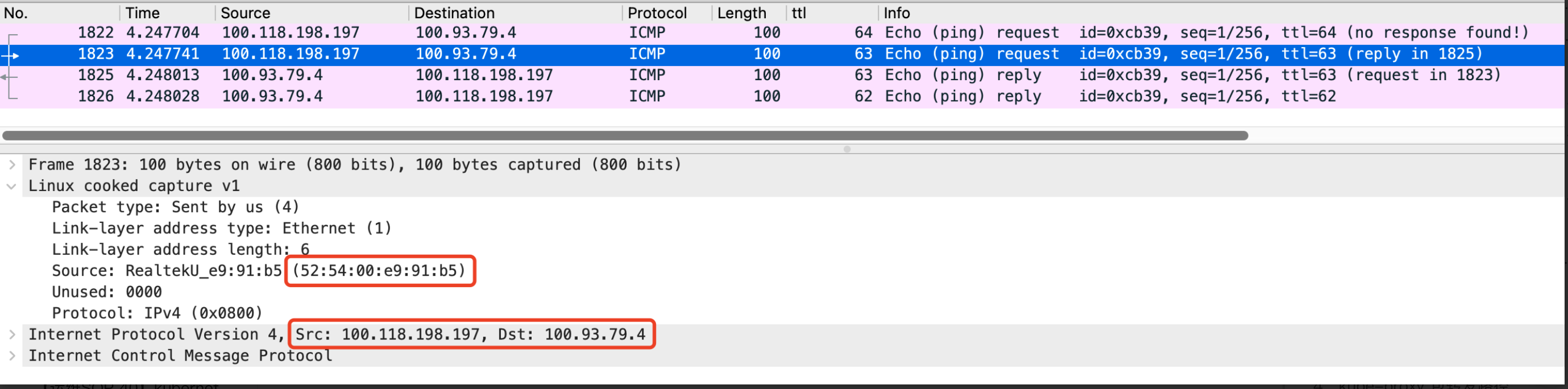 图8
图8
首先我们看到只转发了1次,比之前的网络包少转发一次,其次我们在图6已经看到过一次这个mac地址了,这个是20u5节点的enp1s0网卡的mac地址,这就说明在同子网的情况下没有经过tunl0网卡。那这个是怎么做到的呢?
c、我们通过图9可以看到:之前的路由配置已经改变了,直接路由转发到对应的node节点去了
 图9
图9
由于是处于同一子网下面的,所以通过node节点的mac地址就可以通信了,calico只需要配置对应的路由规则就可以了。如图10所示:
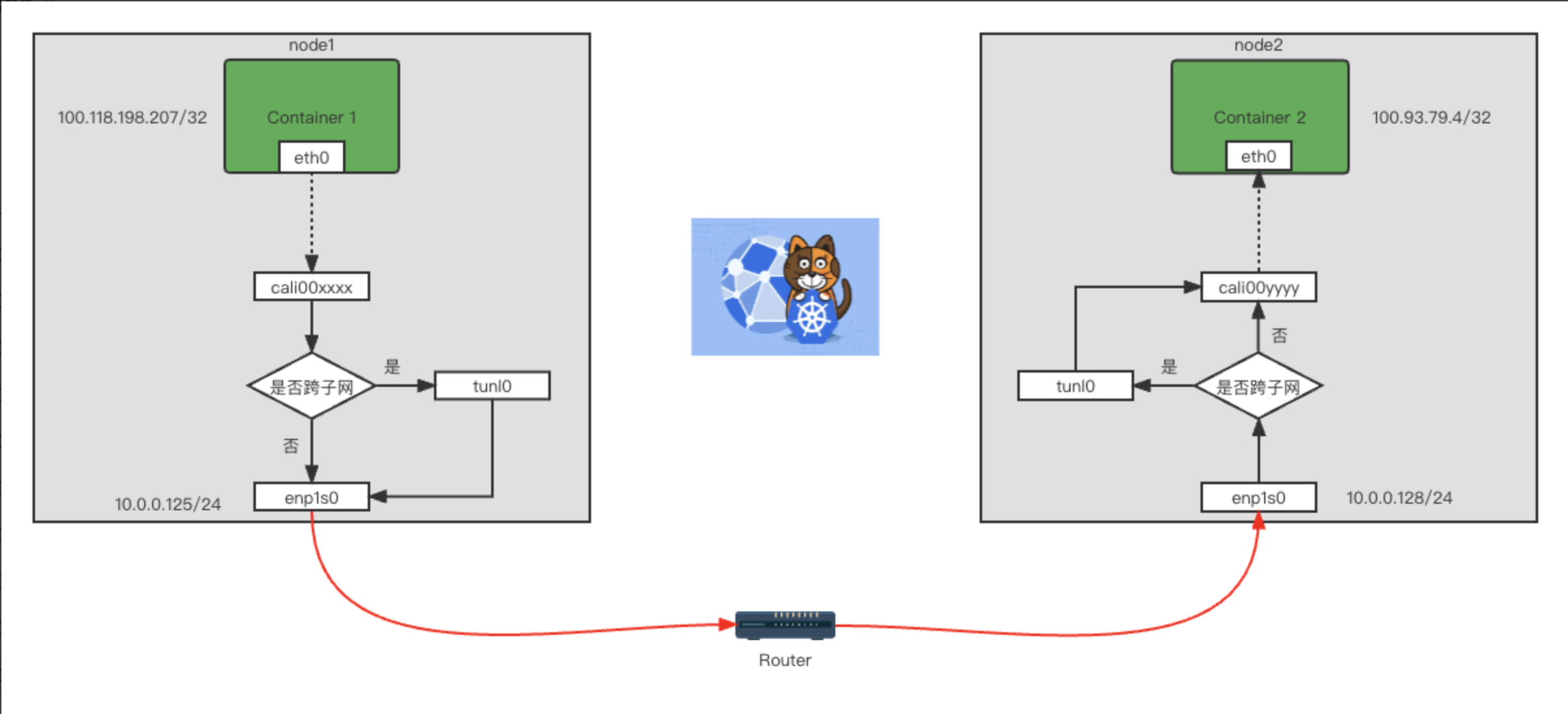 图10
图10
3、Cilium eBPF
Cilium是一个开源软件,用于透明地提供和保护使用Kubernetes,Docker和Mesos等Linux容器管理平台部署的应用程序服务之间的网络和API连接。Cilium基于一种名为BPF的新Linux内核技术,它可以在Linux内部动态插入强大的安全性,可见性和网络控制逻辑。 除了提供传统的网络级安全性之外,BPF的灵活性还可以在API和进程级别上实现安全性,以保护容器或容器内的通信。由于BPF在Linux内核中运行,因此可以应用和更新Cilium安全策略,而无需对应用程序代码或容器配置进行任何更改。
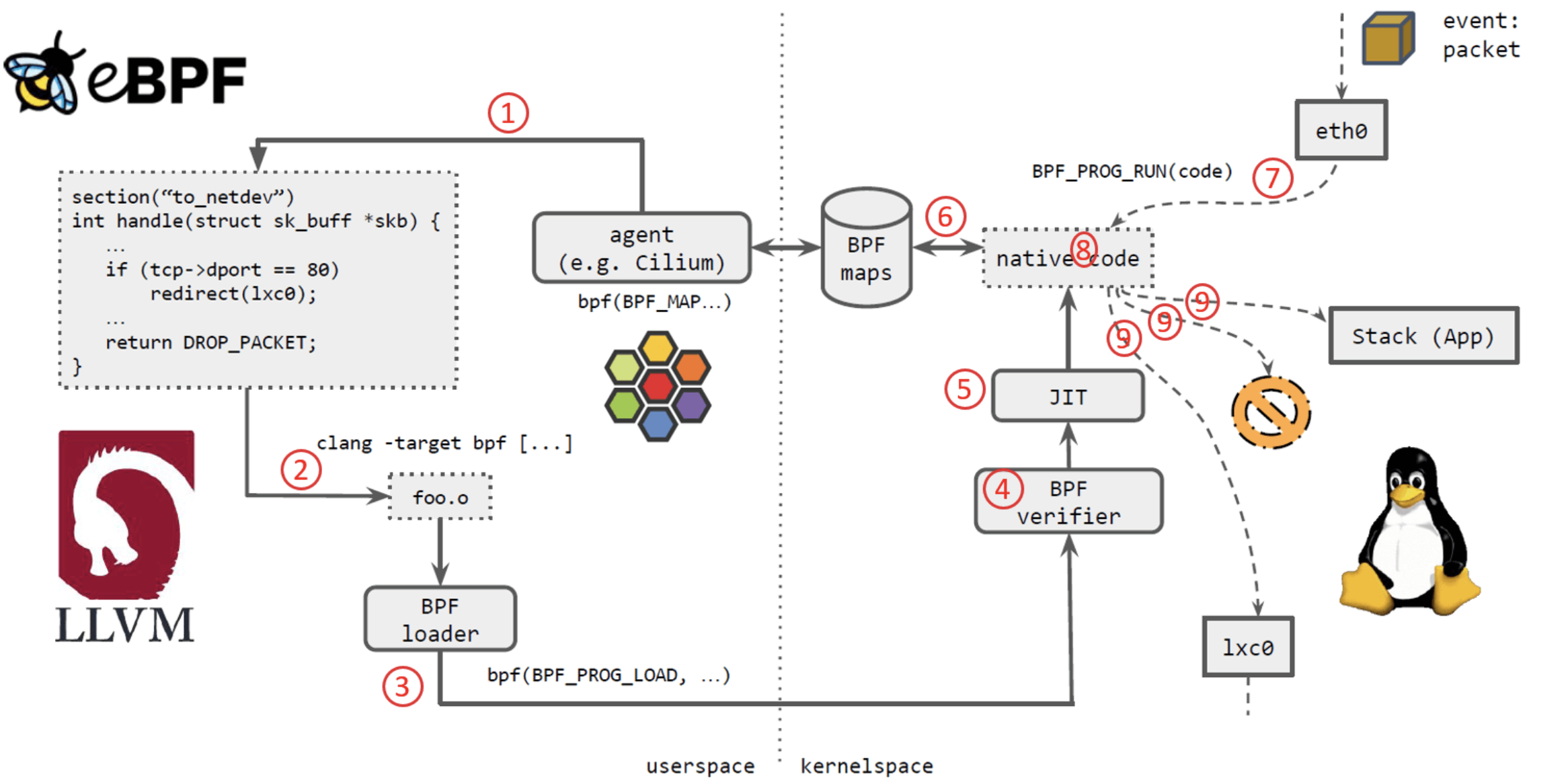 图11
图11
a、cilium的流程
如上图11所示,几个步骤:
Cilium agent 生成 eBPF 程序。
用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,
*.o)。
用 eBPF loader 将对象文件加载到 Linux 内核。
校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储 ,BPF 侧和用户侧都可以访问。
BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
b、eBPF的特点
最重要的一点:不能 crash 内核。
执行起来,与内核模块(kernel module)一样快。
提供稳定的 API。
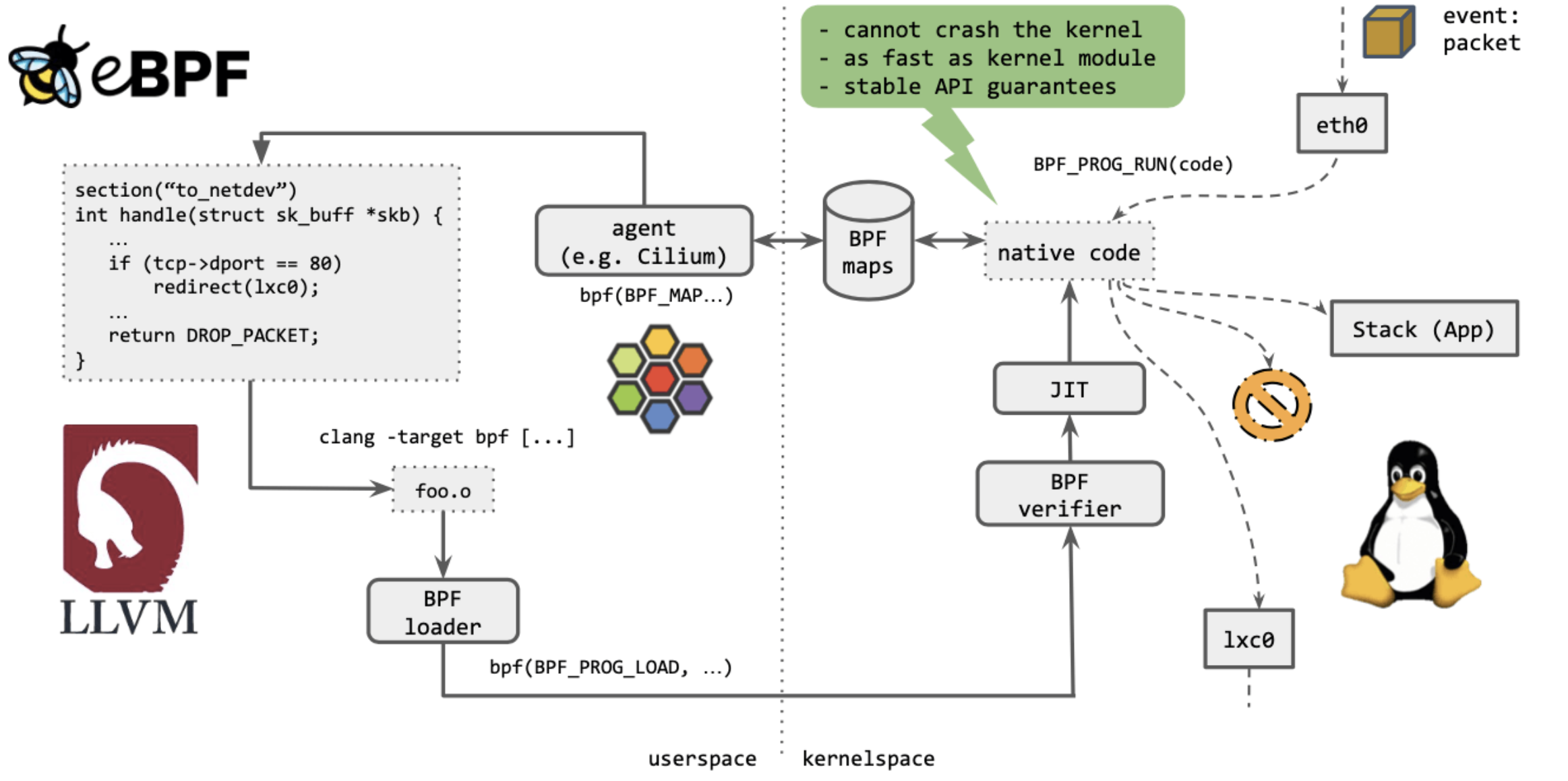
这意味着什么?简单来说,如果一段 BPF 程序能在老内核上执行,那它一定也能继续在新 内核上执行,而无需做任何修改。
这就像是内核空间与用户空间的契约,内核保证对用户空间应用的兼容性,类似地,内核也 会保证 eBPF 程序的兼容性。
4、kube-proxy 包转发路径
从网络角度看,使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图12所示:
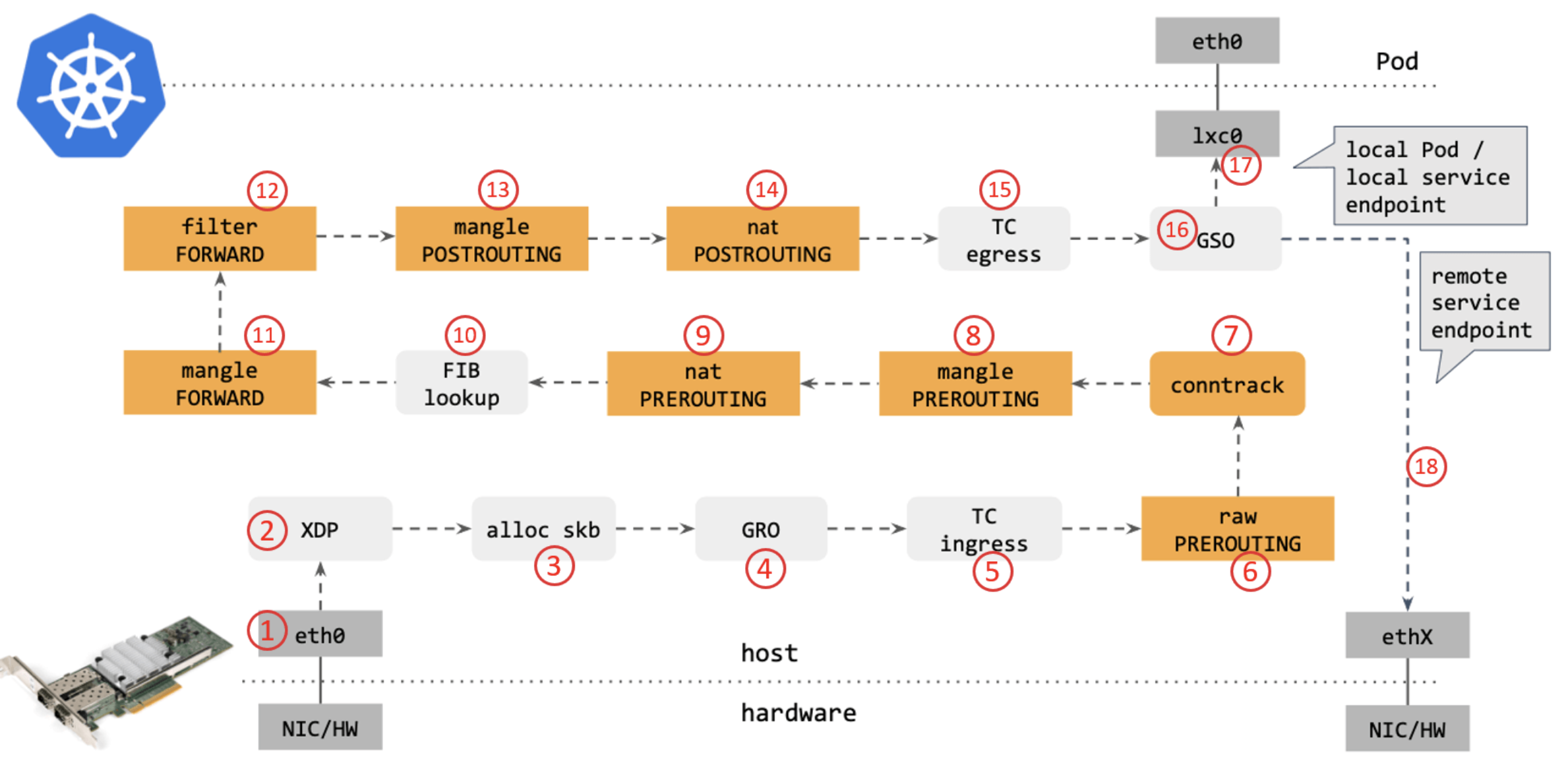 图12
图12
步骤:
网卡收到一个包(通过 DMA 放到 ring-buffer)。
包经过 XDP hook 点。
内核给包分配内存,此时才有了大家熟悉的
skb(包的内核结构体表示),然后 送到内核协议栈。
包经过 GRO 处理,对分片包进行重组。
包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
Netfilter:在
PREROUTINGhook 点处理rawtable 里的 iptables 规则。
包经过内核的连接跟踪(conntrack)模块。
Netfilter:在
PREROUTINGhook 点处理mangletable 的 iptables 规则。
Netfilter:在
PREROUTINGhook 点处理nattable 的 iptables 规则。
进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
Netfilter:在
FORWARDhook 点处理mangletable 里的 iptables 规则。
Netfilter:在
FORWARDhook 点处理filtertable 里的 iptables 规则。
Netfilter:在
POSTROUTINGhook 点处理mangletable 里的 iptables 规则。
Netfilter:在
POSTROUTINGhook 点处理nattable 里的 iptables 规则。
包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
发送到一个本机 veth 设备,或者一个本机 service endpoint,
或者,如果目的 IP 是主机外,就通过网卡发出去。
5、Cilium eBPF 包转发路径
作为对比,再来看下( 图13) Cilium eBPF 中的包转发路径:
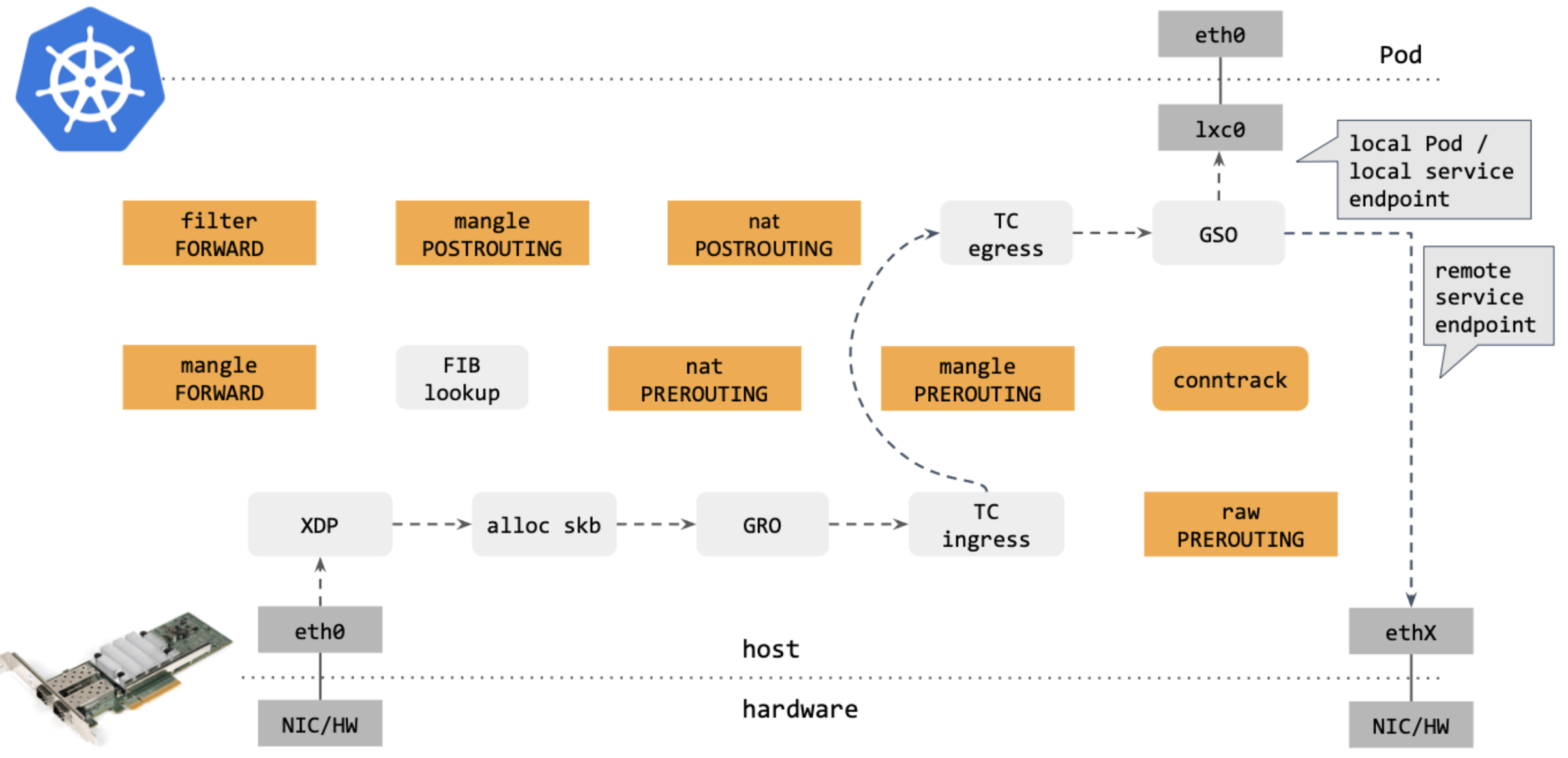 图13
图13
对比可以看出,Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
去掉那些不用的框之后,Cilium eBPF datapath (图14)长这样:
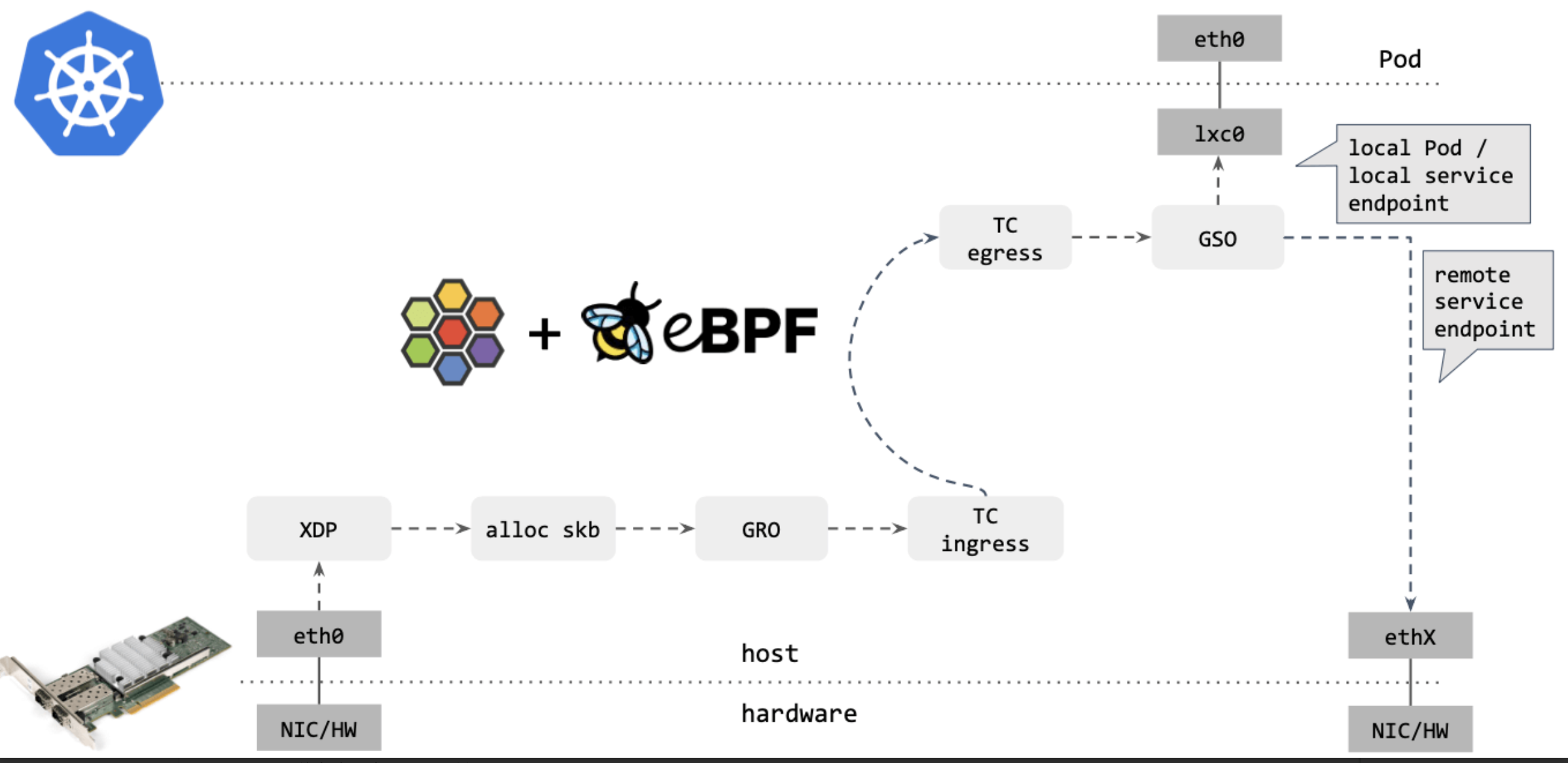 图14
图14
Cilium/eBPF 还能走的更远。例如,如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP 框中完成包的重定向(收包 1->2,在步骤 2 中对包 进行修改,再通过 2->1 发送出去),将其发送出去,如下图15所示:
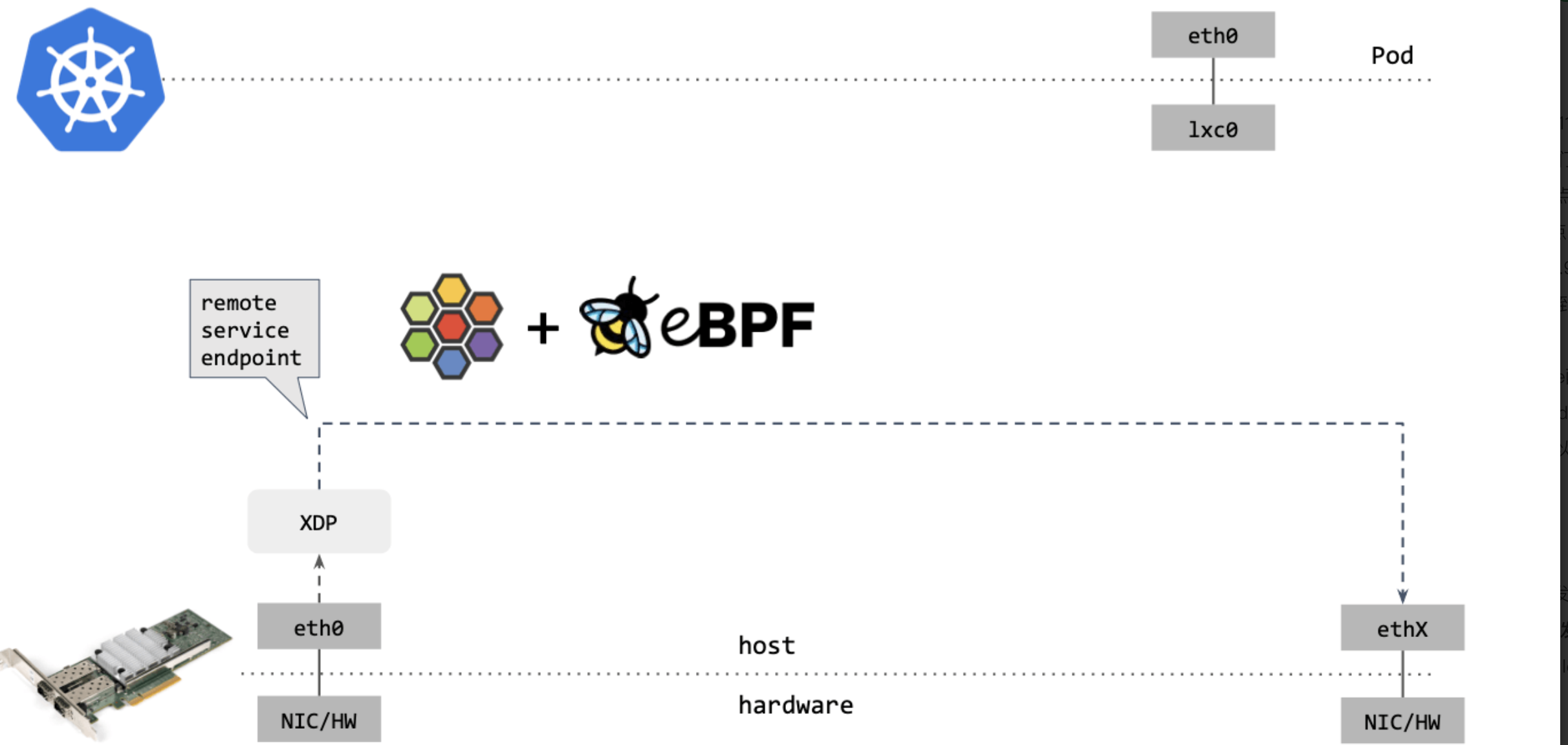 图15
图15
可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb)就被转 发出去了,性能可想而知。
XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,而无需将包送 到复杂的协议栈进行处理,因此处理代价很小,速度极快。
6、Cilium 的 Service load balancing 设计
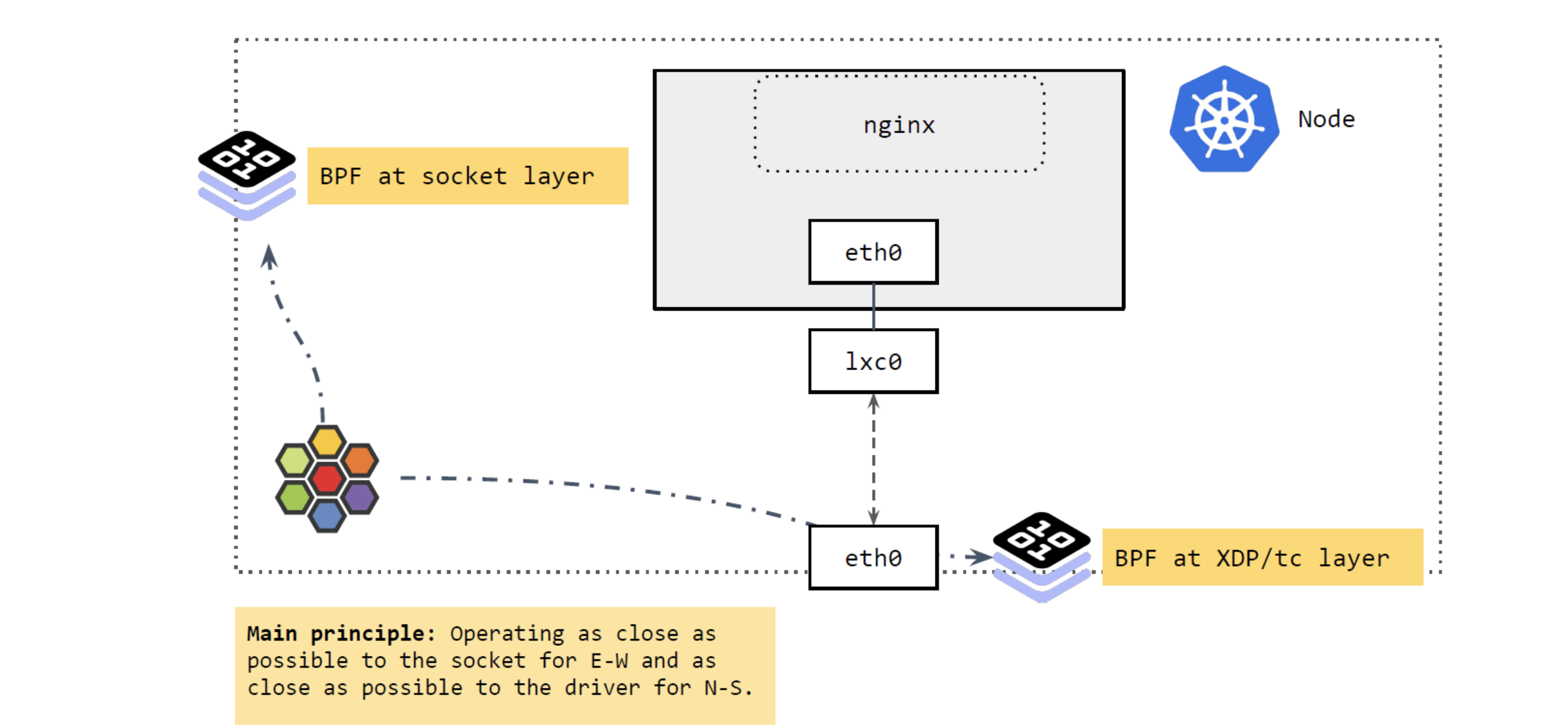 图16
图16
如上图16所示,主要涉及两部分:
在 socket 层运行的 BPF 程序
在 XDP 和 tc 层运行的 BPF 程序
a、东西向流量
我们先来看 socker 层。
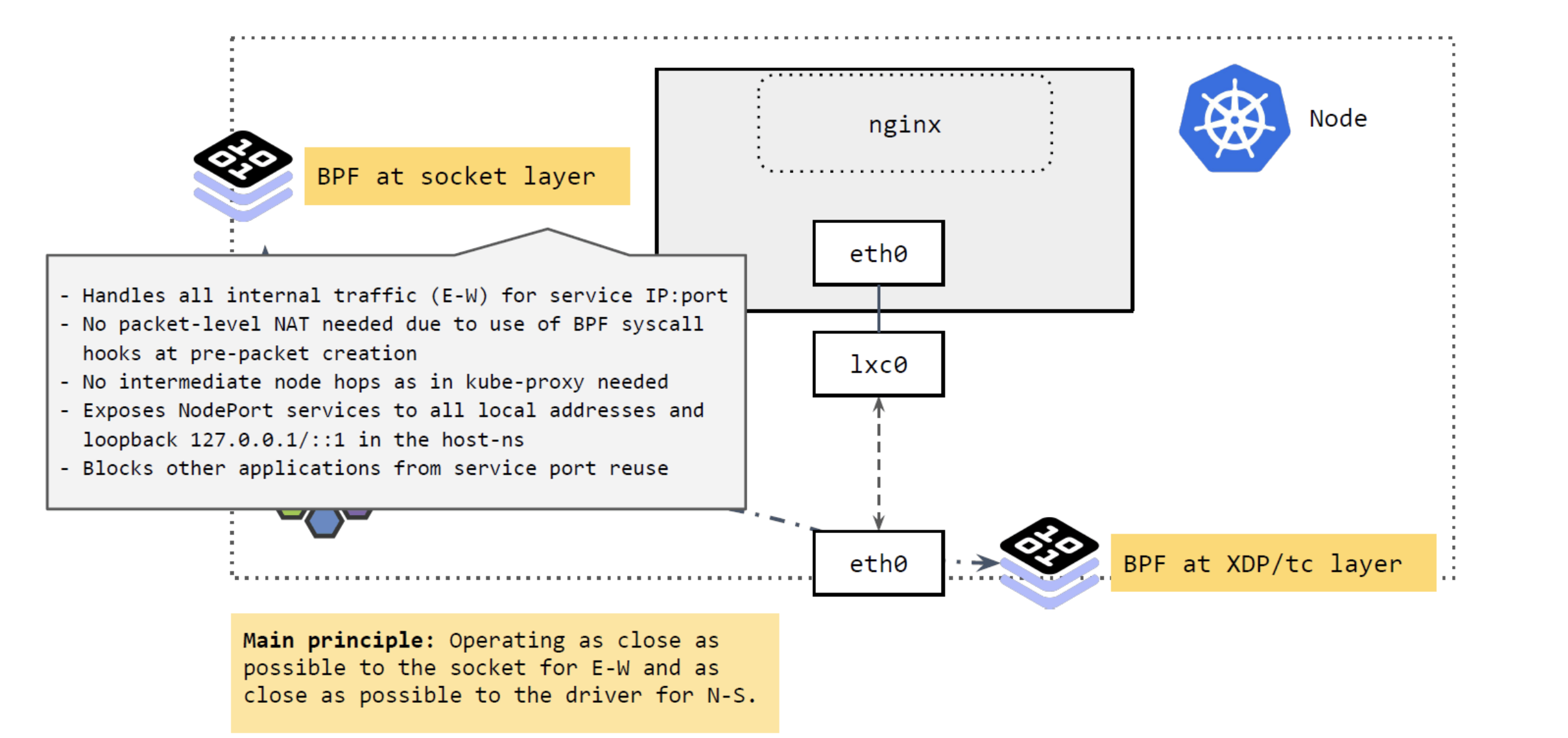 图17
图17
如上图17所示,
Socket 层的 BPF 程序主要处理 Cilium 节点的东西向流量(E-W)。
将 Service 的
IP:Port映射到具体的 backend pods,并做负载均衡。
当应用发起 connect、sendmsg、recvmsg 等请求(系统调用)时,拦截这些请求, 并根据请求的
IP:Port映射到后端 pod,直接发送过去。反向进行相反的变换。
这里实现的好处:性能更高。
不需要包级别(packet leve)的地址转换(NAT)。在系统调用时,还没有创建包,因此性能更高。
省去了 kube-proxy 路径中的很多中间节点(intermediate node hops)
可以看出,应用对这种拦截和重定向是无感知的(符合 k8s Service 的设计)。
b、南北向流量
再来看从 k8s 集群外进入节点,或者从节点出 k8s 集群的流量(external traffic), 即南北向流量(N-S):
区分集群外流量的一个原因是:Pod IP 很多情况下都是不可路由的(与跨主机选用的网 络方案有关),只在集群内有效,即,集群外访问 Pod IP 是不通的。
因此,如果 Pod 流量直接从 node 出宿主机,必须确保它能正常回来。而 node IP 一般都是全局可达的,集群外也可以访问,所以常见的解决方案就是:在 Pod 通过 node 出集群时,对其进行 SNAT,将源 IP 地址换成 node IP 地址;应答包回来时,再进行相 反的 DNAT,这样包就能回到 Pod 了。
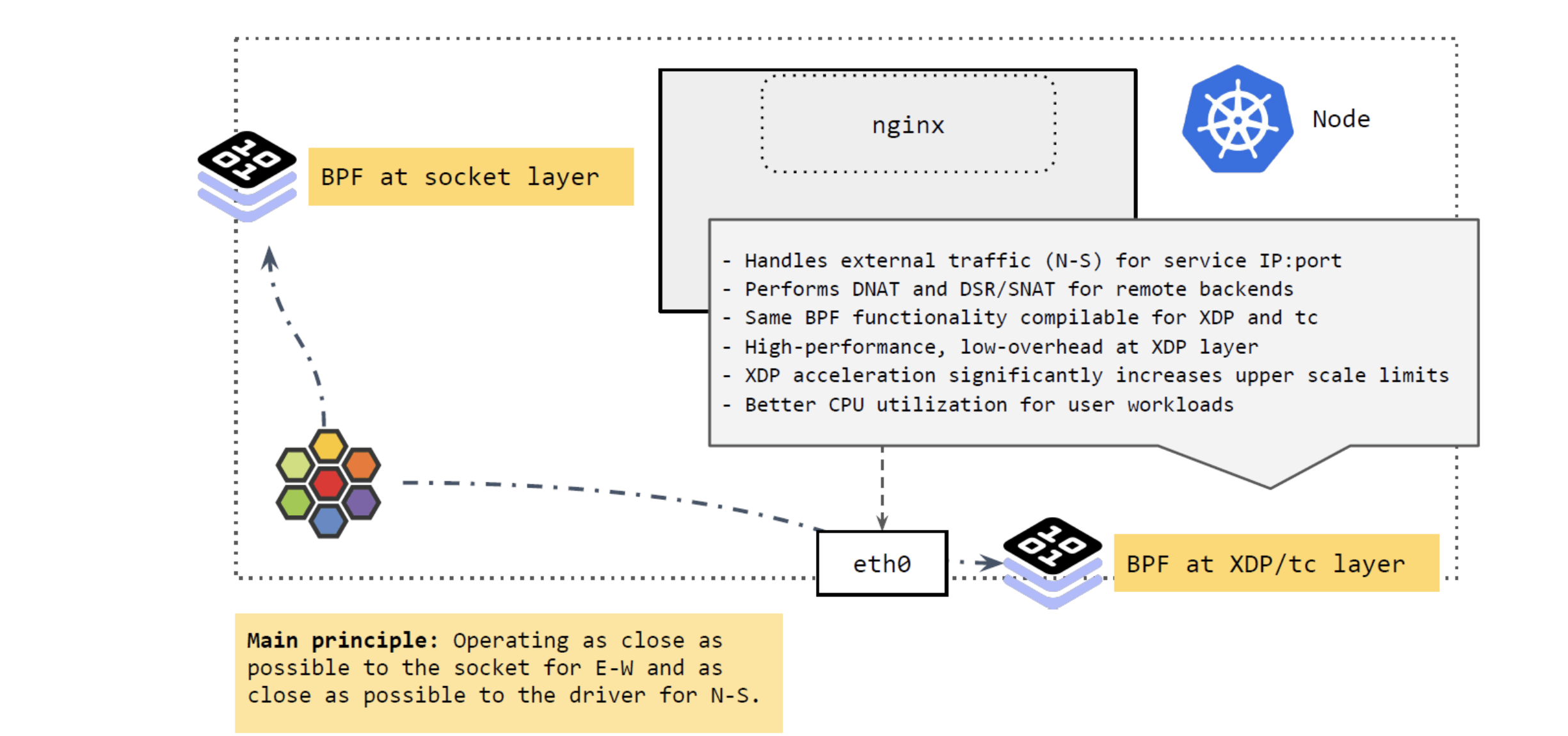
如上图所示,集群外来的流量到达 node 时,由 XDP 和 tc 层的 BPF 程序进行处理, 它们做的事情与 socket 层的差不多,将 Service 的 IP:Port 映射到后端的 PodIP:Port,如果 backend pod 不在本 node,就通过网络再发出去。发出去的流程我们 在前面 Cilium eBPF 包转发路径 讲过了。
这里 BPF 做的事情:执行 DNAT。这个功能可以在 XDP 层做,也可以在 TC 层做,但 在 XDP 层代价更小,性能也更高。
总结起来,这里的核心理念就是:
将东西向流量放在离 socket 层尽量近的地方做。
将南北向流量放在离驱动(XDP 和 tc)层尽量近的地方做。
7、XDP/eBPF vs kube-proxy 性能对比
网络吞吐
测试环境:两台物理节点,一个发包,一个收包,收到的包做 Service loadbalancing 转发给后端 Pods。
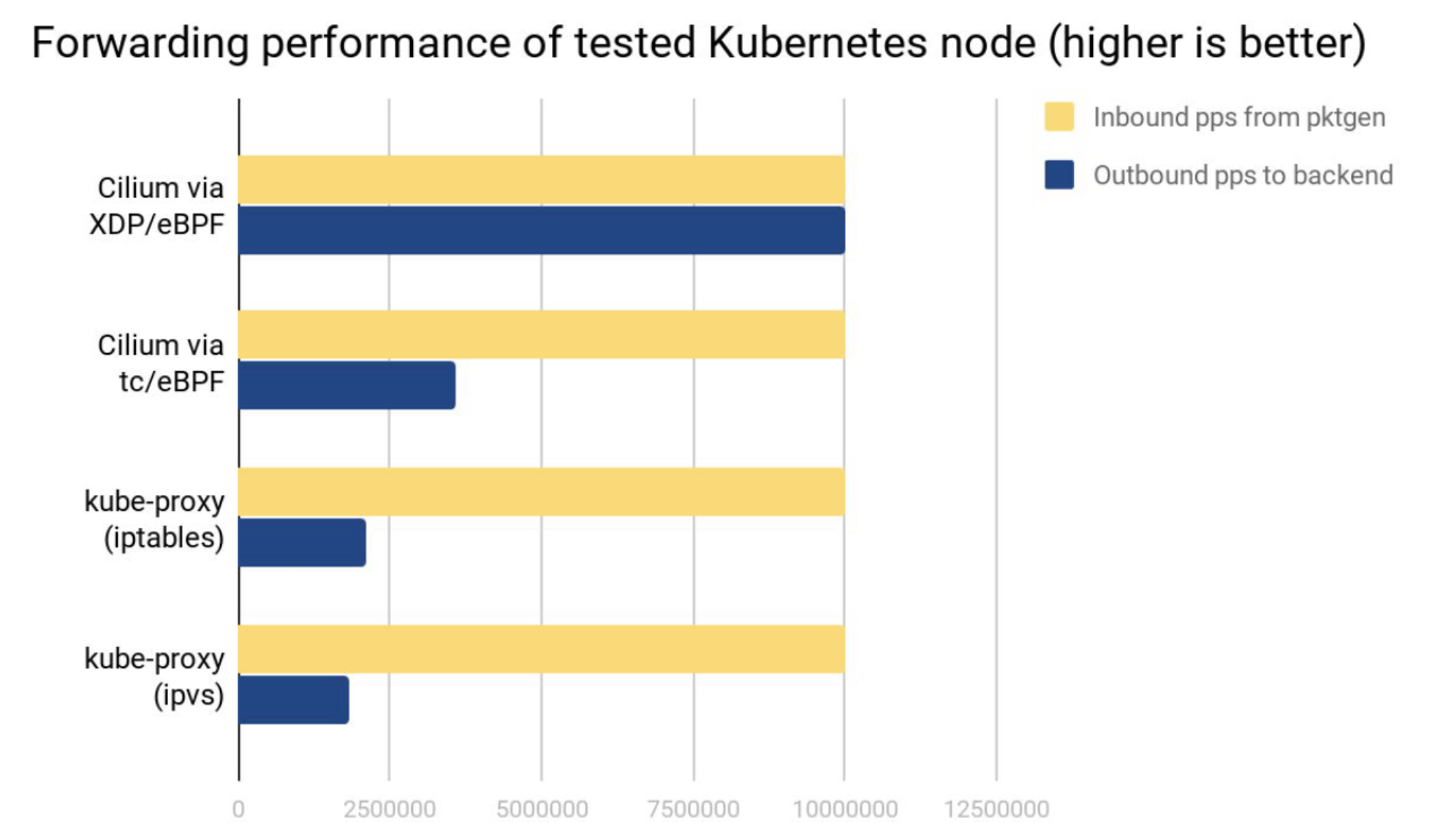
可以看出:
Cilium XDP eBPF 模式能处理接收到的全部 10Mpps(packets per second)。
Cilium tc eBPF 模式能处理 3.5Mpps。
kube-proxy iptables 只能处理 2.3Mpps,因为它的 hook 点在收发包路径上更后面的位置。
kube-proxy ipvs 模式这里表现更差,它相比 iptables 的优势要在 backend 数量很多的时候才能体现出来。
我们生成了 1Mpps、2Mpps 和 4Mpps 流量,空闲 CPU 占比(可以被应用使用的 CPU)结果如下:
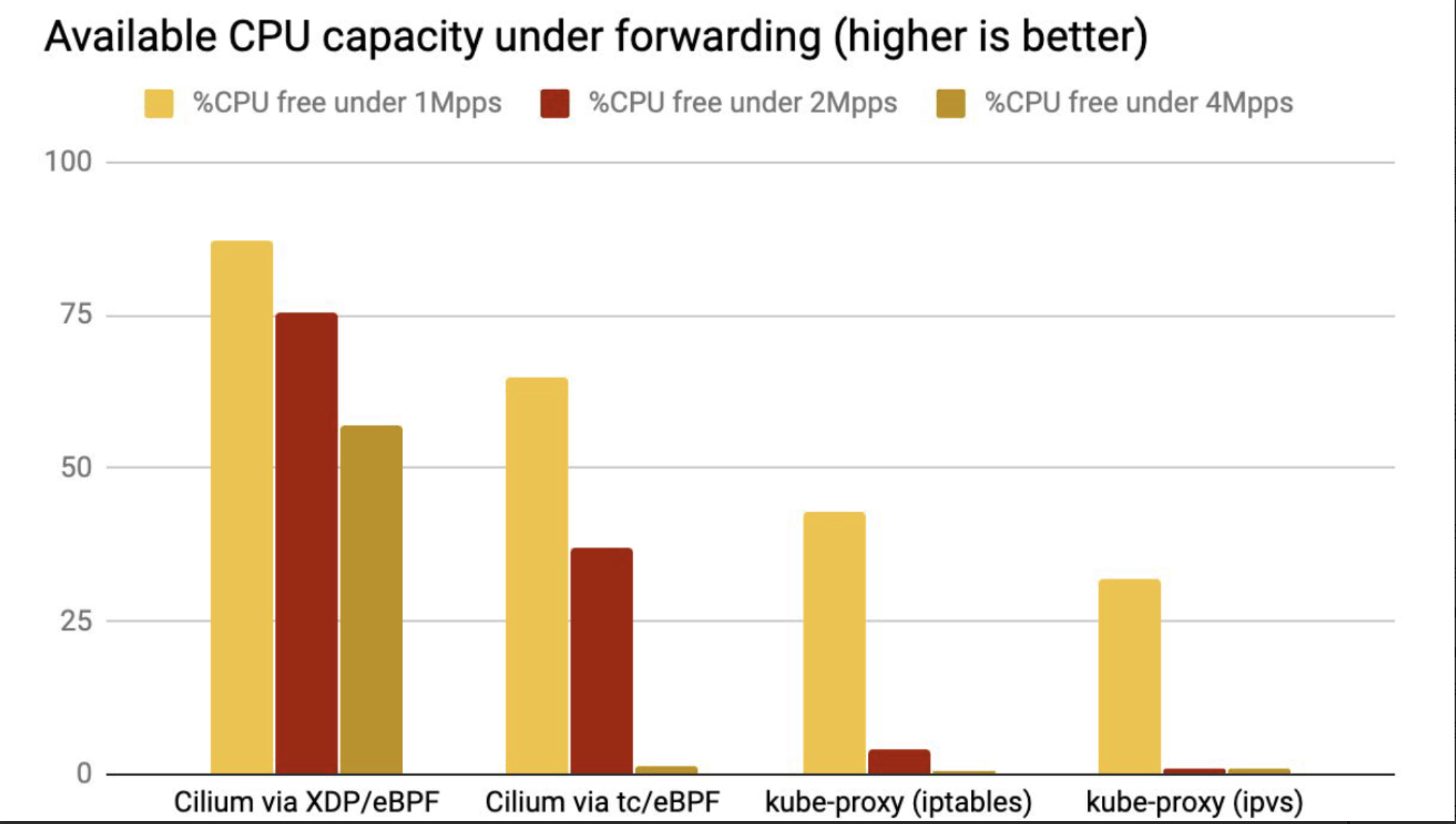
CPU 利用率
结论与上面吞吐类似。
XDP 性能最好,是因为 XDP BPF 在驱动层执行,不需要将包 push 到内核协议栈。
kube-proxy 不管是 iptables 还是 ipvs 模式,都在处理软中断(softirq)上消耗了大量 CPU。
总结:根据以上内容,我们了解了calico ipip模式以及cilium eBPF模式,根据我们从calico官方文档得到的信息:calico也支持了eBPF,而cilium也在支持BGP。由此可见,云原生未来的方向是绕不开这些技术的。eBPF 可以称为最近这些年以来Linux内核最重要的模块之一,其所带来的深远影响,希望大家能尽快熟悉此模块。由于eBPF对Linux内核版本有着比较大的要求,在4.8以上版本才支持的比较好,大家都知道CentOS 7支持时间已经快要结束了。接下来不管是Redhat系还是Debian系的,内核版本都不会低于4.18。接下来就是eBPF大行其道的时间了。
引用1:https://docs.cilium.io/en/stable/
引用2:https://projectcalico.docs.tigera.io/about/about-calico