Python 并发编程 Futures
编程中如果能合理利用编程语言的并发编程技巧,都可以极大提升程序的性能。在 Python 3.2 版本为用户提供了一个标准库 可以实现进程池 和 线程池,本篇文章介绍 Python 并发编程 Futures。
1. 并发与并行
并发(Concurrency)指某个特定时刻,只允许有一个操作发生,通过 线程/任务 之间互相切换,直到任务完成。并发通常应用于 I/O 操作频繁的场景,比如从网站上下载多个文件,I/O 操作的时间可能会比 CPU 运行处理的时间长得多。
并行(Parallelism)是指同一时刻,同时发生。并行则更多应用于计算密集型的场景,比如 MapReduce 中的并行计算,为了加快运行速度,一般会用多台机器、多个处理器来完成。
2. Futures 模块
如果是 I/O 密集型场景,读取文件、读取网络 I/0 等,使用 ThreadPoolExecutor 是可以提升速度的,如果是 CPU 计算密集型,使用 ThreadPoolExecutor 是无法提升速度的,因为 GIL 原因可能还会更慢,使用 ProcessPoolExecutor 也就是 multiprocessing 可以实现真正的并行计算。
其原理是 concurrent.futures 会以子进程的形式,平行的运行多个 python 解释器,从而令 python 程序可以利用多核 CPU 来提升执行速度。由于子进程与主解释器相分离,所以他们的全局解释器锁也是相互独立的,每个子进程都能够完整的使用一个 CPU 内核。
2.1 顺序执行
下方使用顺序执行的方式执行程序:
import time
# 求最大公约数
def gcd(pair):
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
numbers = [
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
]
start = time.time()
# 这里使用 map 函数对 gcd 进行调用
for i in map(gcd, numbers):
print(i)
end = time.time()
print('Took %.3f seconds.' % (end - start))
消耗时间是:1s
2.2 并发执行
使用 Futures 模块的线程池执行该计算:
import time
import concurrent.futures
def gcd(pair):
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
# 可以理解为计算任务
numbers = [
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
]
start = time.time()
# 线程池处理
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for task in numbers:
future = executor.submit(gcd, task)
to_do.append(future)
# 回调
for future in concurrent.futures.as_completed(to_do):
print(future.result())
end = time.time()
print('Took %.3f seconds.' % (end - start))
消耗时间是:1s 并没有速度提升,因为调用的程序属于 CPU 密集型,因为 GIL 使用多线程并不会提升速度,而且可能因为上下文切换导致程序更慢。
2.3 并行执行
使用 Futures 模块的进程池执行该计算:
import time
import concurrent.futures
def gcd(pair):
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
# 可以理解为计算任务
numbers = [
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
]
start = time.time()
# 线程池处理
with concurrent.futures.ProcessPoolExecutor(max_workers=4) as executor:
to_do = []
for task in numbers:
future = executor.submit(gcd, task)
to_do.append(future)
# 回调
for future in concurrent.futures.as_completed(to_do):
print(future.result())
end = time.time()
print('Took %.3f seconds.' % (end - start))
消耗时间是 0.3 秒,速度比较前面两个版本都快。
2.4 Executor 对象
class concurrent.futures.Executor 是一个抽象类,提供了如下抽象方法 submit、map、shutdown。值得一提的是 Executor 实现了 enter 和 exit 使得其对象可以使用 with 操作符。
上方的几个例子都是使用 submit 方法调用的,除此之外还有 map 方法可以传入任务实现 并发/并行。与 submit 的区别是 map 输出得到结果是有序的。
import time
import concurrent.futures
def gcd(pair):
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
# 可以理解为计算任务
numbers = [
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
]
start = time.time()
# 线程池处理
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
result_list = executor.map(gcd, numbers)
for i in result_list:
print(i)
end = time.time()
print('Took %.3f seconds.' % (end - start))
3. 全局解释器锁
上面的例子,我们使用线程池,使用线程池执行一个 CPU 密集型程序,发现消耗的时间和单线程差不多,并没有速度提升,其原因就是 Python 的 GIL(Global Interpreter Lock,即全局解释器锁)同一时刻也只能有一个线程处于运行状态,且切线程之间切换时还要消耗一部分资源。这就导致 CPU 密集型任务下多线程反而没有单线程运行的快。
3.1 为什么有 GIL
这与 CPython 解释器有关,发生在多个线程同时访问同一个共享代码、变量、文件等没有进行锁操作或者同步操作的场景中,就有可能出现条件竞争漏洞(Race condition)使用 GIL 可以规避掉类似的问题。还有一点是因为 Python 解释器使用 C 语言库,而大部分 C 语言库都不是原生线程安全的。
3.2 GIL 工作过程
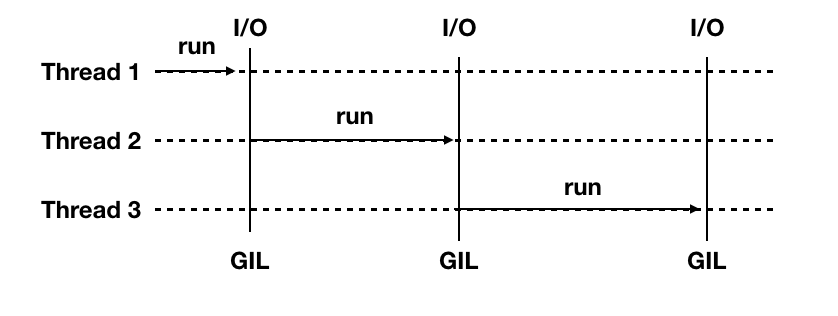
下图是 GIL 在 Python 程序的工作示例。Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL 以阻止别的线程执行;每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。 CPython 解释器会去轮询检查线程 GIL 的锁住情况。每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。该机制叫做 check_interval。
3.3 线程安全
有 GIL 并不意味着 Python 没有线程安全的问题,因为还有 check_interval 抢占机制,可以看下方 CASE:
import threading
num = 0
def add():
global num
for i in range(10000000):
num += 1
def sub():
global num
for i in range(10000000):
num -= 1
if __name__ == "__main__":
subThread01 = threading.Thread(target=add)
subThread02 = threading.Thread(target=sub)
subThread01.start()
subThread02.start()
subThread01.join()
subThread02.join()
print("num result : %s" % num)
程序每次执行的结果可能都不相同,结果都不为 0,此时就需要使用线程锁来规避此类问题。