docker日志管理
docker的日志分类
一、Docker 引擎日志(也就是 dockerd 运行时的日志)
Ubuntu14.04:
/var/log/upstart/docker.log
Centos 6/7或ubuntu 16.04 :通过journalctl -u docker 命令查看 如下图:

二、容器的日志,容器内的服务产生的日志。
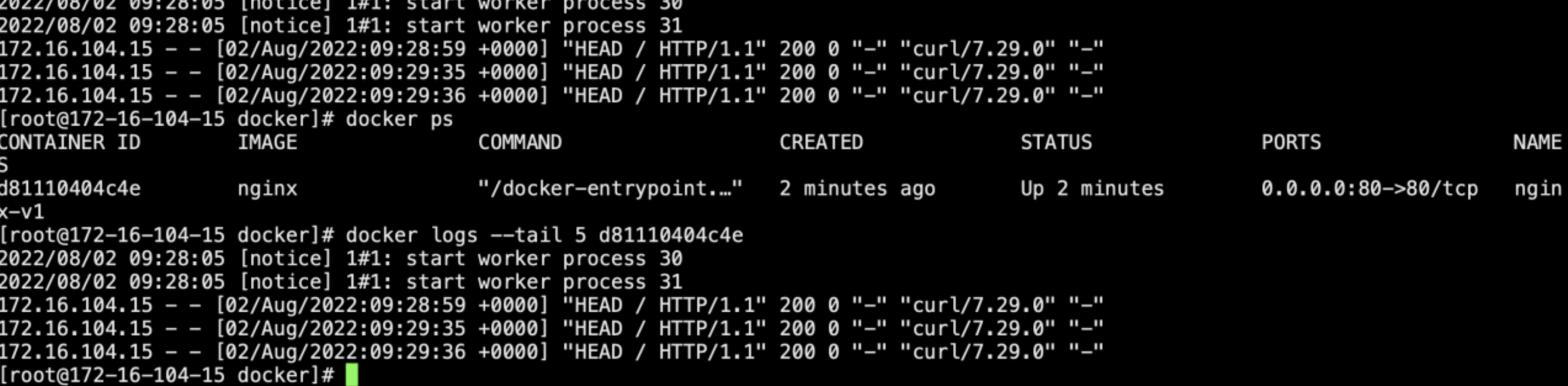
查看容器的输出日志命令: docker logs container_id|container_name
若日志量太大,通过命令 docker logs --tail N container_id来查看最新的N条或使用docker logs -f container_id实时监控日志输出
三、docker日志驱动
当我们启动一个容器时,其实是作为Docker Daemon的一个子进程运行,Docker Daemon可以拿到容器里进程的标准输出与标准错误输出,然后通过Docker的Log Driver模块来处理

查看单个容器的设置的日志驱动
docker inspect -f '{{.HostConfig.LogConfig.Type}}' container_id
查看系统当前设置的日志驱动
docker info --format '{{.LoggingDriver}}'

查看当前版本支持的日志驱动: #当前dokcer版本不支持local日志驱动,目前有docker20.04支持
docker info |grep 'Log:'
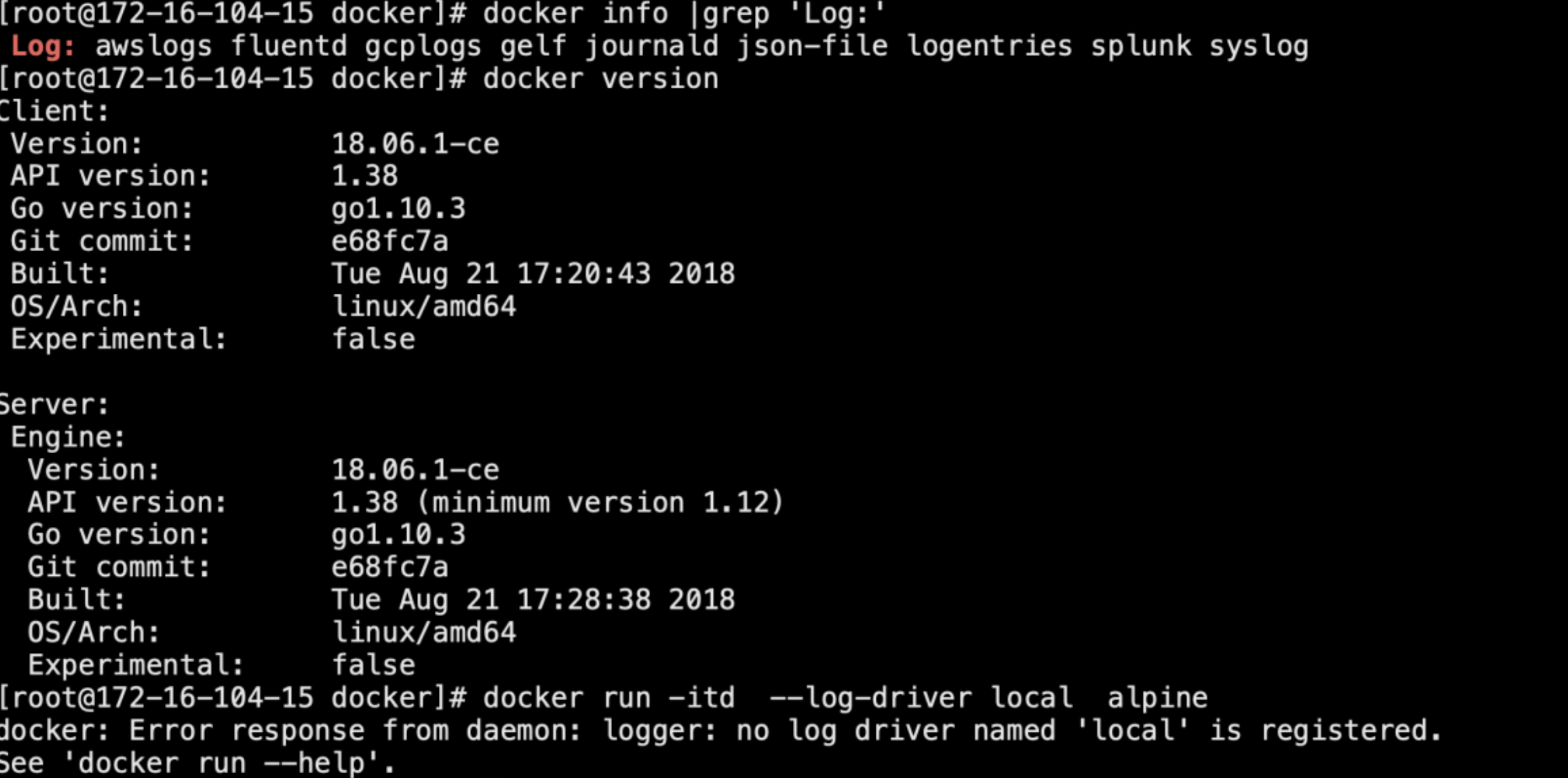
配置docker日志的全局驱动--应选择合适的docker版本,如docker20.04
修改日志全局驱动,配置文件 /etc/docker/daemon.json
{ "log-driver": "local",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
参数解释:
log-driver:日志驱动名字
max-size: 单个日志的大小,默认20M
max-file: 保存日志的个数,默认是5
例:配置单一容器日志驱动:
docker run -itd --log-driver local alpine ash #这里指定的日志驱动为 local
1、日志驱动1: local
local 日志驱动记录从容器的 STOUT/STDERR 的输出,并写到宿主机的磁盘。若设置了日志驱动的配置文件为100m,则local 日志驱动为每个容器保留 100MB 的日志信息,并启用自动压缩来保存。
local 日志驱动的储存位置: /var/lib/docker/containers/容器id/local-logs/ 以container.log 命名。
命令行启动一个容器,并配置日志驱动为local
# docker run -itd --log-driver local alpine ping www.baidu.com
3795b6483534961c1d5223359ad1106433ce2bf25e18b981a47a2d79ad7a3156
# docker inspect -f '{{.HostConfig.LogConfig.Type}}' 3795b6483534961c #查看运行的容器的 日志驱动是否是 local
local #查看日志
# tail -f /var/lib/docker/containers/3795b6483534961c1d5223359ad1106433ce2bf25e18b981a47a2d79ad7a3156/local-logs/container.log
NNdout????:64 bytes from 14.215.177.38: seq=816 ttl=55 time=5.320 ms
NNdout?μ???:64 bytes from 14.215.177.38: seq=817 ttl=55 time=4.950 ms
2、日志驱动2: json-file
所有容器默认的日志驱动 json-file。 json-file 日志驱动记录从容器的 STOUT/STDERR 的输出,用 JSON 的格式写到文件中,日志中不仅包含着 输出日志,还有时间戳和输出格式。
日志位置:/var/lib/docker/containers/container_id/container_id-json.log为了更容易的展现设置参数的最后效果,daemon.json的参数设置如下
cat daemon.json
{ "registry-mirrors": ["http://4a1df5ef.m.daocloud.io"],
"log-driver": "json-file",
"log-opts": { "max-size": "20k",
"max-file": "3" }
}
# docker run -itd alpine ping www.baidu.com #启动一个容器,一直ping
3、日志驱动3:syslog
syslog 日志驱动将日志路由到 syslog 服务器,syslog 以原始的字符串作为 日志消息元数据,接收方可以提取以下的消息:
level 日志等级 如debug,warning,error,info。
timestamp 时间戳
hostname 事件发生的主机f
acillty 系统模块
进程名称和进程 ID
Linux 系统中 我们用的系统日志模块时 rsyslog ,它是基于syslog 的标准实现。我们要使用 syslog 驱动需要使用 系统自带的 rsyslog 服务.查看rsyslogd当前版本信息

在rsyslogd.conf文件中配置rsyslog的tcp端口为514,重启rsyslog,并启动一个nginx容器,如下所示:

4、日志驱动4:journald
journald 日志驱动程序将容器的日志发送到 systemd journal, 可以使用 journal API 或者使用 docker logs 来查日志。除了日志本身以外, journald 日志驱动还会在日志加上下面的数据与消息一起储存。

配置journald的daemon.json文件。重启docker,启动一个nginx容器

查看容器的日志:

5、journald查看日志相关命令
# 查看所有日志(默认情况下 ,只保存本次启动的日志)
$ sudo journalctl
# 查看内核日志(不显示应用日志)$ sudo journalctl -k
# 实时滚动显示最新日志 $ sudo journalctl -f
# 查看指定进程的日志$ sudo journalctl _PID=1
# 查看某个路径的脚本的日志$ sudo journalctl /usr/bin/bash
# 查看指定用户的日志$ sudo journalctl _UID=33 --since today
# 显示日志占据的硬盘空间$ sudo journalctl --disk-usage
$ sudo journalctl --vacuum-size=1G
# 指定日志文件保存多久 $ sudo journalctl --vacuum-time=1years