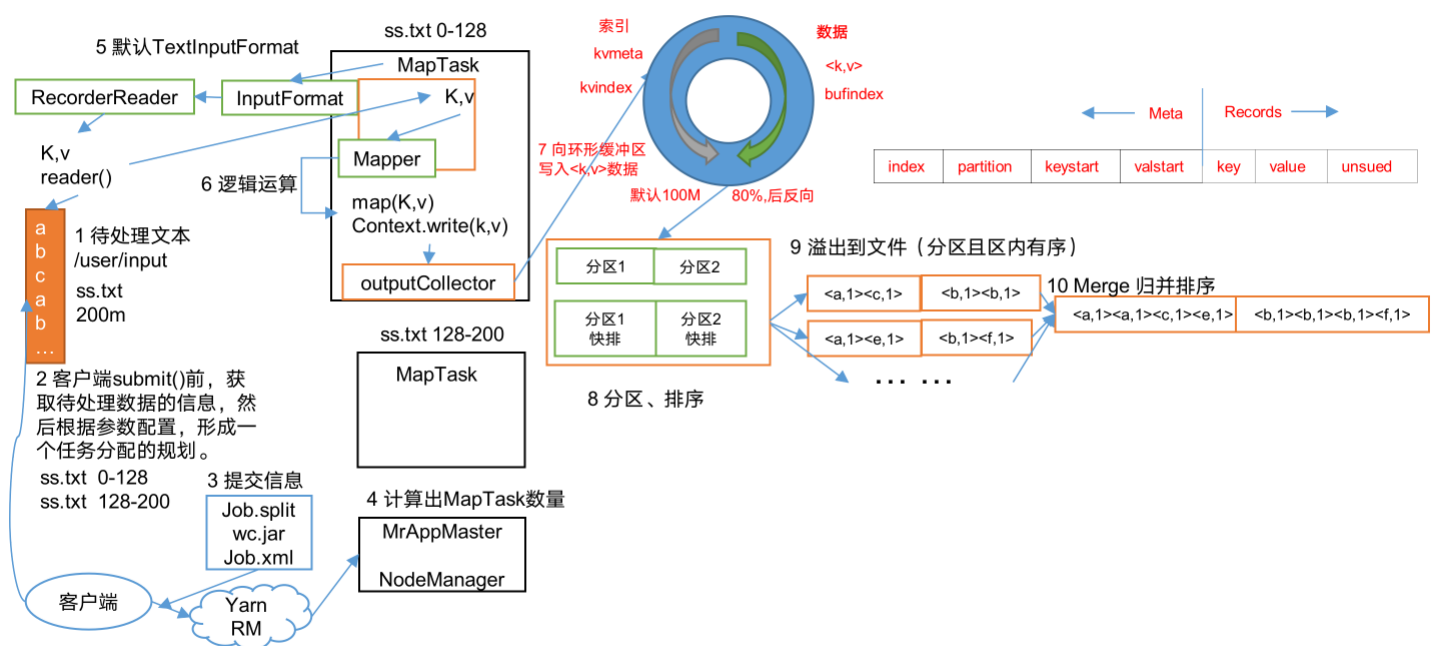
MySQL运维实战之ProxySQL(9.9)proxysql自身高可用
proxysql作为一个程序,本身也可能出现故障。部署proxysql的服务器也肯能出现故障。高可用架构的一个基本原则是消除单点。
可以在多个节点上部署proxysql,在proxysql之前再加一层负载均衡(如使用LVS或其他技术),从而消除proxysql的单点。也可以使用keepalived等技术来实现proxysql的高可用

部署多台proxysql后,需要确保多台proxysql的配置同步。不然就可能会引起客户端访问出错。可以使用proxysql自带的集群功能来保证多个节点之间的配置信息同步。
开启proxysql的集群功能,需要:
配置cluster账号,用于查询对比集群内各proxysql节点的配置信息
配置proxysql_servers,将集群内的proxysql节点信息添加到proxysql_servers表
以上操作需要到组成集群的每一个proxysql节点上执行。
配置cluster账号
通过参数admin-cluster_username和admin-cluster_password设置cluster账号。不能使用admin账号作为cluster账号,因为admin账号只能在本地(127.0.0.1)登陆。
同时还需要将cluster账号添加到参数admin-admin_credentials中。
set admin-admin_credentials = 'admin:admin;clusteradmin:passadmin'; set admin-cluster_username='clusteradmin'; set admin-cluster_password='passadmin'; load admin variables to runtime; save admin variables to disk;
使用proxysql集群
将组成proxysql集群的多个节点的信息添加到proxysql_servers表。
mysql> show create table proxysql_servers\G
*************************** 1. row ***************************
table: proxysql_servers
Create Table: CREATE TABLE proxysql_servers (
hostname VARCHAR NOT NULL,
port INT NOT NULL DEFAULT 6032,
weight INT CHECK (weight >= 0) NOT NULL DEFAULT 0,
comment VARCHAR NOT NULL DEFAULT '',
PRIMARY KEY (hostname, port) )
1 row in set (0.00 sec)
insert into proxysql_servers values('172.16.121.234', 6032, 1, 'proxysql node 1');
insert into proxysql_servers values('172.16.121.236', 6032, 1, 'proxysql node 2');
LOAD PROXYSQL SERVERS TO RUNTIME;
save PROXYSQL SERVERS TO disk;配置完成后,在其中一个节点修改配置,观察配置是否同步到集群的其他节点。